오픈소스: 코드 분석 어떻게 하나?

MySQL, Apache, Tomcat 등과 같은 오픈 소스는 매뉴얼이나 문서, 책 등도 많이 나와 있으며 오픈 소스이지만 솔루션 자체도 안정적이라서 특별한 이유가 아니면 소스를 분석할 필요는 없습니다.
하지만 Hadoop이나 HBase 등과 같은 솔루션은 문서도 부족하지만 문서로만 설명할 수 없는 복잡한 내용으로 구성되어 있는 솔루션이 많습니다. 따라서 제대로 솔루션을 사용하거나 운영하기 위해서는 소스 코드를 봐야 하는 경우가 많습니다.
최근 Presto, Zeppelin, Kafka 등을 사용하면서 필요한 기능을 추가하거나 설치, 운영 중 에러를 해결하기 위해 사용하는 오픈 소스의 코드를 분석하였습니다. 이때 사용되었던 제 나름대로 가지고 있는 오픈소스 코드 분석 방법에 대해 정리해 보았습니다.
(제가 주로 사용하는 프로그램 언어가 자바라서 대부분 자바 기준으로 많이 되어 있습니다.)
해당 솔루션에 대한 기본 지식을 먼저 익혀라.
하둡을 분석하려면 구글에서 발표한 논문을 읽어 봐야하고, HBase를 분석하기 위해서는 BigTable 논문을 읽어야 합니다. 분석하고자 하는 솔루션에 대한 이론적인 배경 지식이 없는 상태에서 소스 코드를 바로 보면 그냥 스파게티처럼 얽혀 있는 코드를 보고 있는 느낌이 듭니다. 복잡한 분산 컴퓨팅 환경에서 운영되는 솔루션인 경우 더욱 더 그 시스템의 기본 개념과 아키텍처를 이해하고 있어야 합니다.
특정 알고리즘에 대해서는 코드가 더 보기 쉬울때도 있다.
전체 코드 중 일부는 어떤 알고리즘이나 기법을 구현한 코드가 있을 수 있는데 이 경우 해당 솔루션내에 있는 코드를 먼저 이해하기 보다는 그 알고리즘만 구현된 공개된 코드를 찾아서 보는 것이 알고리즘을 문서로 이해하는 것보다 훨씬 빨리 이해할 수 있습니다.
분석하고자 하는 프로그램 언어에 대한 기본 지식은 필수이다.
두말하면 잔소리가 되겠죠?
라이브러리 또는 다른 오픈 소스에 대한 지식도 필요하다.
최근 오픈 소스는 직접 모든 기능을 구현하기 보다는 또 다른 오픈 소스를 이용하여 만드는 경우가 많습니다. 네트워크 모듈은 Netty, 분산 환경에 대한 관리는 ZooKeeper, Dependency Injection 을 위한 Guice 등 수많은 라이브러리들이 있습니다. 이것들은 한번에 다 이해하기는 어렵지만 어느 정도 코드를 분석할 수 있는 수준까지는 알고 있어야 합니다.
본인 PC에 빌드 및 실행 환경을 구축하라.
코드 분석을 빨리하기 위해서는 분석에 필요한 로그를 추가하여 재 컴파일한 후 실행하면서 로그를 확인하는 것이 좋습니다. 단순 코드만 보면 특정 연산의 흐름이 어떻게 진행되고 있는지를 파악하기 어려운 경우가 많기 때문입니다. 실제로 필자가 가장 먼저 하는 부분이 바로 이 항목입니다.
최근의 오픈소스들은 분산 환경에서 운영되는 경우가 많은데 이 경우라 하더라도 개발자의 PC(가능하면 노트북)에 빌드와 실행환경을 모두 구성하는 것이 좋습니다. “좋다”라는 정도가 아니라 필수 사항이라 할 수 있습니다.
최근 오픈 소스는 복잡도의 증가와 연관된 다른 오픈 소스가 많아서 Eclipse, IntelliJ 등과 같은 IDE에 빌드 환경을 구성하는 것이 쉬운 작업은 아닙니다. 하지만 빌드 및 실행환경을 구성하는 것만으로 코드 분석의 50%는 진행되었다고 할 수 있습니다.
그리고 가능하면 노트북에 환경을 구성하여 회사, 집, 이동중에도 지속적으로 분석할 수 있는 환경을 갖추는 것이 좋습니다. 필자의 개발 노트북 환경은 메모리 16GB, CPU 4 Core, SSD로 구성되어 있으며 MySQL, ZooKeeper, Hadoop, HBase, Presto, Kafka, ElasticSearch 등 개발, 분석에 필요한 모든 솔루션을 하나의 노트북에서 실행합니다.
Eclipse의 여러 프로젝트를 동시에 볼 수 있는 기능
Hadoop이 여러개의 서브 프로젝트로 분리 되기 전에는 주로 Eclipse를 이용하였는데 이때에는 다음 화면과 같이 Eclipse에 100개 이상의 오픈 소스 프로젝트가 등록되어 있었습니다.
IntelliJ를 이용하면서 부터는 Eclipse와 같이 탐색기 형태로 여러 프로젝트를 볼 수 없는 부분이 좀 아쉽기는 합니다. 위 화면과 같은 방식의 장점은 여러 관련 프로젝트의 코드를 동시에 볼 수 있는 장점이 있어서 좋습니다.

IntelliJ의 Multiple sub project 구성
수정, 실행, 확인 사이클을 짧게 만들어라.
코드를 분석하기 위해서는 분석에 필요한 정보를 출력하는 코드나 확인을 위한 코드를 추가한 다음에 기능을 실행해서 확인해야 하는 경우가 많습니다. 이 경우 수정, 실행, 확인을 위한 시간이 길어지면 그만큼 효율이 떨어지게 되고 많은 시간이 소요됩니다. 몇번 반복하다 보면 같은 작업 패턴을 찾게되는데 이때에는 스크립트를 만들어서 반복 작업을 효율적으로 하는 것이 좋습니다.
자신에게 질문을 많이 하라.
오픈 소스 개발자라고 해서 하늘에서 떨어진 개발자는 아닙니다. 대부분 비슷한 교육을 받고 비슷한 경험을 했습니다. 따라서 특정 기능에 대해서 "나라면 어떻게 개발했을까?" 라고 자신에게 질문을 던지고 머리속에 어떻게 구현할 것인지를 먼저 그려 봅니다. 처음에는 자신이 예측했던 부분이 많이 틀리겠지만 코드를 많이 보고 연습을 많이 하면 이것도 얼추 많이 맞추게 됩니다. 유사한 오픈 소스 그룹은 유사한 패턴으로 개발하기 때문입니다. 대표적인 오픈 소스 그룹이 Hadoop 및 그 패밀리들(HBase, ZooKeeper, HBase, Hive 등)입니다.
분석하면서 문서로 정리하라.
분석을 하면서 그림 또는 문서로 정리를 하면 분석하는 그 시점에도 도움이 되지만 나중에도 도움이 됩니다. 문서는 굳이 UML이 아니더라도 ppt 같은 도구로 정리하면 됩니다. 이렇게 중간 중간에 정리하면 머리속에서만 빙빙 돌던 생각이 정리될때가 많습니다. “분석이 다 된 다음에 깔끔하게 정리해야지” 라는 생각이면 거의 정리는 못한다고 봐야 합니다. 나중에 정리하려면 정리도 어렵고 생각도 잘 나지 않습니다. 그리고 이미 다 이해한 내용을 굳이 문서로 남길 필요가 없지 않냐라는 귀챠니즘이 발동하게 됩니다.
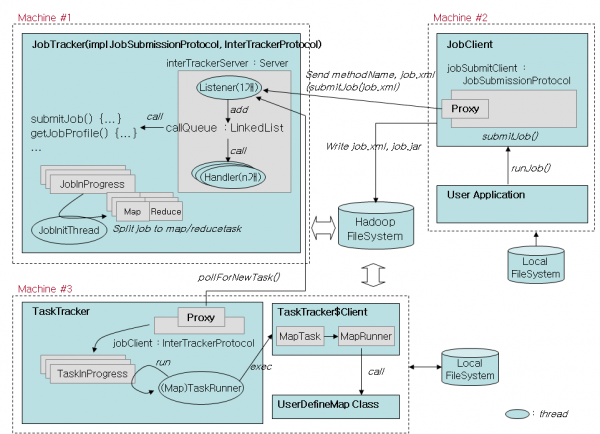
Hadoop 동작 원리 소스코드 분석 정리
다음은 필자가 2006년에 분석한 Hadoop의 MapReduce 처리를 정리한 그림입니다.
LOG level을 DEBUG로 설정하라.
배포되는 패키지는 대부분 Logger의 설정이 INFO 또는 WARN으로 설정된 경우가 많습니다. 더 많은 정보를 얻기 위해서는 logger의 레벨을 DEBUG로 설정합니다. DEBUG로 설정할 경우 너무 많은 로그 메시지가 나올 수 있는데 패키지 별로 서로 다른 수준의 LOG level을 설정하는 것이 좋습니다.
디버거의 breakpoint 기능을 활용하라.
집중적으로 분석하고 싶은 구간은 디버거의 breakpoint 기능을 이용하여 step 단위로 실행하면서 각 변수의 변화 상태를 확인하는 것이 좋습니다.
System.out.println 보다는 Thread.dumpStack()을 활용하라.
최근 오픈 소스는 리플렉션을 적극 활용하거나 DI 등을 이용하여 코드 그 차제만으로는 어떤 클래스가 실행중에 바인딩 되는지 찾기 어려운 경우가 많습니다. 그리고 해당 로직이 어떤 경로를 거쳐 호출되는지 찾기 어려운 경우가 많습니다.
이 경우 앞에서 설명한 디버거를 이용할 경우에도 어디에 breakpoint를 걸어야 할 지 애매한 경우가 많은데 이 경우 짐작이 가는 부분에 Thread.dumpStack() 코드를 추가하면 전체 호출 흐름 및 실제 바인딩 되는 클래스를 확인할 수 있습니다.
당장 관심있는 부분부터 집중적으로 파악하라.
방대한 시스템의 경우 전체를 보다 보면 금방 지루하고 갈 곳을 읽어 버리는 수가 많습니다. 당장 필요하거나 관심있는 부분부터 집중해서 보는 것이 좋습니다. 하둡 파일 시스템의 경우 클라이언트 모듈인 FileSystem과 DFSClient부터 보면서 해당 기능과 연결되어 있는 NameNode, DataNode의 method를 파악하는 것이 좋습니다.
Zeppelin의 경우 서버쪽 모듈 전체를 파악하기 보다는 Paragraph의 실행을 위해 어떤 서버 API 가 호출되고 그 API 이후에는 어떤 경로를 거쳐 실행되는지 파악해보는 것이 좋습니다. 이렇게 되면 전체 명령 실행 경로를 파악할 수 있습니다.
테스트 코드는 좋은 교본이 된다.
좋은 오픈 소스는 좋은 테스트 코드를 가지고 있습니다. 테스트 코드는 실제 운영되는 기능이나 모듈의 동작을 테스트하기 위한 프로그램 코드이기 때문에 특정 기능을 수행하기 위해 어떤 클래스의 어떤 메소드가 호출되는지가 바로 나타나 있는 경우가 많습니다.
그리고 테스트 코드 중 일부는 데몬을 실행하지 않고 바로 실행, 확인할 수 있는 코드가 많기 때문에 이런 테스트 코드와 breakpoint 등을 잘 조합하면 쉽고 빠르게 소스 코드를 분석할 수 있습니다.
그래도 어려우면 초기 버전을 다운로드 받아 분석하라.
복잡해보이는 오픈소스도 초창기 버전은 단순하게 기본 기능만 구현되어 있는 경우가 많습니다. 버전이 올라가면서 개발자들이 많이 참여하게 되고 코드는 점점 복잡해지고 기능도 많아지게 됩니다. 초창기 버전에서는 핵심 기능에만 집중하는 경우가 많기 때문에 핵심 기능을 분석하기에는 초창기 버전이 좋습니다. Hadoop 도 지금은 엄청난 기능과 수 많은 코드가 있지만 초기에는 수백개 정도의 클래스가 전부 였습니다. 위에서 본 분석 그림을 그리고 전체 코드를 파악하는데 1 ~ 2 주 정도면 충분했었으니까요.
오픈 소스의 다운로드 페이지에는 최근 버전 또는 이전 몇개 버전만 다운로드 가능한데 소스 레포지토리를 활용하거나 다운로드 페이지의 Archives 페이지를 활용하여 다운로드 받을 수 있습니다.
마치며
지금까지 오픈 소스 코드 분석을 위한 여러 가지 팁에 대해 생각나는 대로 정리해 보았습니다. 오픈 소스의 사용은 이제 선택이 아닌 필수 입니다. 오픈 소스를 사용하는데 있어 두려움을 없애는 가장 좋은 방법은 코드를 보는 것이라고 생각합니다. 코드를 보게 되면 그 코드를 통해 더 많은 것을 배우고 그 코드를 흉내냄으로써 기술적으로 한 단계 더 발전할 수 있을 것입니다. 처음에는 눈에 잘들어오지 않고 환경 구성을 위한 삽질의 연속이 되겠지만 익숙해지면 문제 발생 시 구글 검색을 하기 보다 소스 코드를 먼저 보고 있는 자신을 발견하게 될 것입니다.
더 좋은 팁 있으면 댓글 달아주시면 저와 다른 독자들에게도 도움이 되리라 생각합니다.