코드 한줄 없이 서비스 Dashboard 만들기(1)

서비스를 운영하는 조직에서는 PV, UV 등과 같은 지표를 꾸준하게 관리하고 있습니다. 각종 지표를 꾸준하게 관리하는 이유는 서비스가 기획 의도했던 방향대로 사용자가 사용하고 있는지, 서비스의 문제는 없는지 등을 파악하기 위함입니다. 간단하게 이런 지표는 엑셀 등으로 관리할 수 있지만 많은 사람들이 공유하기 어렵고, 실시간 데이터를 바로 반영하기 어렵습니다. 또한, 새로운 기능을 출시하고 이 기능에 사용자가 어떻게 반응하는지 확인하기 위해서는 개발팀이 데이터를 지속적으로 뽑아 줘야 하는 경우가 많습니다.
Dashboard는 주로 자주 보거나 중요한 지표를 하나의 화면 또는 부서별, 업무별 화면으로 모아 놓은 화면으로 주로 TV나 큰 모니터에 나타내고 문제가 발생하면 글자나 바탕색을 이용하여 알람을 제공하는 용도로 사용됩니다. 물론 전시효과도 무시할 수는 없죠. 이런 Dashboard를 만드는 작업도 여간 귀찮은 작업이 아니며 항상 리소스가 부족한 스타트업의 경우 이런 Dashboard를 만드는 것에 소홀할 수 밖에 없습니다.
이번 글에서는 다음 글의 연장선에 있는 글로 Kafka에 저장된 로그 데이터나 MySQL에 저장된 실제 트렌젝션 데이터를 이용하여 코드 작성 없이 SQL(또는 유사한 질의) 만으로 Dashboard를 구성하는 방법에 대해 살펴 보려고 합니다.
- Presto, Zeppelin을 이용한 초간단 BI 시스템 구축 사례(1)
- Presto, Zeppelin을 이용한 초간단 BI 시스템 구축 사례(2)
- InfluxDB, Telegraf, Grafana 를 활용한 Monitoring System 만들기(1)
- InfluxDB, Telegraf, Grafana 를 활용한 Monitoring System 만들기(2)
- InfluxDB, Telegraf, Grafana 를 활용한 Monitoring System 만들기(3)
- NSA의 Dataflow 엔진 Apache NiFi 소개와 설치
시스템 요구사항
다음과 같은 시스템 요구사항을 갖는 Dashboard 시스템을 구축하였습니다.
- 데이터 발생 시점부터 Dashboard에 반영되는 시기는 빠르면 좋지만 최소한 5분 이내라야 함
- 로그 원본 데이터는 이미 S3에 저장되기 때문에 Dashboard 용 데이터만 처리하면 됨
- 로그 데이터 뿐만 아니라 트렌젠셕으로 발생하는 DB 데이터를 집계한 정보도 Dashboard에 나타나야 함
- 신규 기능이 추가 되었을 때 별도의 코드 수정없이 빠르게 Dashboard에 항목을 추가 할 수 있어야 함
- 사내 시스템으로 가끔 장애, 데이터 유실 등이 발생해도 됨
시스템 구성
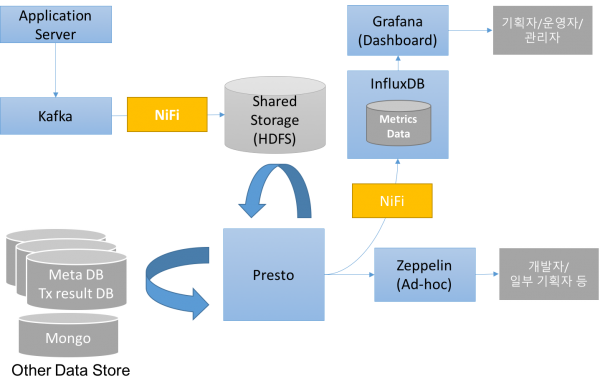
대략 다음과 같은 절차로 Dashboard 데이터를 저장, 가공, 조회를 하고 있습니다.
- Application Server에서 발생하는 로그 데이터는 Kafka로 저장
- Kafka의 데이터를 NiFi를 이용하여 HDFS에 저장
- 데이터 저장 시 Hourly partition 으로 구분하여 저장
- HDFS에 저장된 데이터 또는 MySQL에 저장된 데이터를 Presto를 이용하여 조회하여 InfluxDB 로 저장
- NiFi를 이용하여 매분 또는 십분 단위로 Presto Query 실행
- InfluxDB에 저장된 데이터를 이용하여 Grafana에 Dashboard 화면을 구성
이 시스템의 핵심 구성은 기존에 프로그램 코드로 만든 구성을 NiFi를 이용하여 클릭만으로 수정, 추가 할 수 있게 한 것과, InfluxDB와 Grafana를 이용하여 Dashboard를 쉽게 구성했다는 것입니다. 이런 구성의 아이디어는 Popit에 게시된 글을 참고하여 만들게 되었습니다. 그러면 NiFi로 어떻게 구성했는지 자세하게 살펴 보도록 하겠습니다.
NiFi를 이용하여 Kafka -> HDFS에 저장하기
NiFi는 기존의 Workflow와는 다르게 데이터가 NiFi 를 통과하면서 지정된 Processor를 실행하면서 원하는 작업을 수행하는 방식으로 동작합니다. NiFi에 대한 추가 설명은 위에 참고 링크에서 확인하세요.
NiFi 를 이용하면 Kafka에 저장되고 있는 레코드를 별도 코드 작업 없이 HDFS 에 저장할 수 있습니다. HDFS에 단순히 저장만 하는 것이 아니라 레코드의 내용을 변경하거나, HDFS에 Hive 테이블 파티션별로 레코드를 모아서 저장할 수 도 있습니다.
NiFi 전체 흐름은 다음 화면과 같습니다.
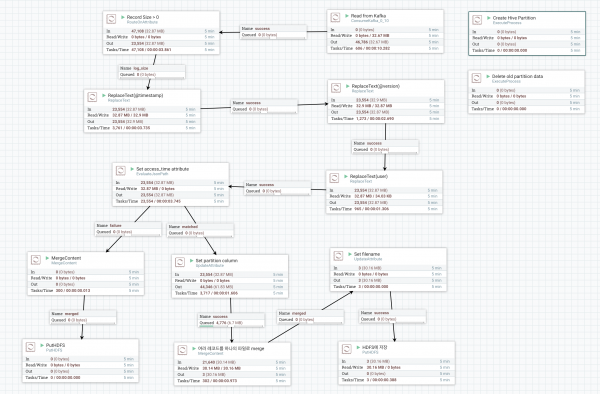
절차가 조금 많아서 화면이 뭉개져 보이는데 단계별로 보면 다음과 같은 절차와 Processor를 사용하고 있습니다.
- Read Kafka Topic: ConsumeKafka_0_10 Processor
- Record Size > 0 이상만 처리: RouteOnAttribute Processor
- ${fileSize:gt(0)}
- Log Record 에서 @timestamp를 access_time 으로 replace: ReplaceText Processor
- logstash를 이용하여 로그하는 경우 json의 키 값으로 @timestamp, @version이 자동으로 삽입되는데 Presto에서 json serde 를 사용하여 json의 key를 컬럼에 mapping 하게 되면 "@" 는 컬럼명에 사용할 수 없기 때문에 replace를 해야 함
- Log Record 에서 @version을 version 으로 replace: ReplaceText Processor
- Log Record에서 "user:" 를 "user_info:" 로 replace: ReplaceText Processor
- Log Record에서(json format) access_time 값을 찾아 Flow attribute에 설정: EvaluateJsonPath Processor
- HDFS에 저장시 hourly로 파티션된 디렉토리에 저장하기 위해 로그의 access_time 정보를 이용해야 함
- EvaluateJsonPath Processor를 이용하여 JsonPath를 지정하여 Json 값을 가져 올 수 있음
- NiFi는 데이터 흐름에서 실제 데이터(여기서는 Log Record)를 FlowFile이라고 하고 추가로 임의의 속성을 각 단계를 거치면서 설정할 수 있음
- 여기서는 Log Record는 다음 단계로 패스시키고 access_time 값을 읽어 "access_time" 이라는 attribute로 설정
- "access_time" attribute를 이용하여 "datehour" attribute를 설정: UpdateAttribute Processor
- datehour = ${access_time:toDate("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'"):format("yyyyMMddHH")}
- 여러개의 Log Record를 모음: MergeContent Processor
- 최종적으로 HDFS에 저장하는 Processor는 PutHDFS Processor를 이용하는데 이 Processor는 전달된 하나의 FlowFile(하나의 LogRecord)을 HDFS 파일에 저장하는 기능을 수행. 따라서 Merge 하지 않으면 하나의 Log Record 당 하나의 파일이 생성됨
- 이 문제를 해결하기 위해 MergeContent Processor를 이용하여 여러 레코드를 하나의 파일에 저장
- 설정값은 다음과 같음
- Correlation Attribute Name: datehour (앞에서 정의한 파티션을 위한 attribute)
- Minimum Number of Entries: 1000
- Minimum Group Size: XX MB (XX MB가 넘으로면 Merge)
- Maximum number of Bins: 2 minutes (2분이 넘으면 Merge)
- "filename" attribute 설정: UpdateAttributeProcessor
- PutHDFS Processor는 "filename" attribute를 이용하여 저장. 따라서 PutHDFS Processor 호출하기 전에 filename 이 설정되어 있어야 함
- filename = ${datehour}_${now():toNumber()}_${hostname()}
- HDFS에 저장: PutHDFS Processor
- FlowFile(여러 Record가 Merge된)을 HDFS 파일에 저장
- PutHDFS에는 HDFS에 저장하기 위해 몇가지 설정을 해야 함
- Hadoop Configuration Resources: conf 파일을 ,로 구분하여 지정.
- /opt/hadoop-2.7.1/etc/hadoop/core-site.xml,/opt/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
- Directory: "/user/hive/external/log/datehour=${datehour}"
- Hadoop Configuration Resources: conf 파일을 ,로 구분하여 지정.
여기까지 해서 Kafka -> HDFS로 최대 2분 Deplay 되게 저장할 수 있습니다. 추가로 캡쳐된 화면의 우측 상단에 보면 두개의 Processor는 연결되지 않은 상태인데 이 두개는 다음과 같은 주기적으로 독립적인 기능을 수행하기 위해 만들어 졌습니다.
- Hive의 테이블 파티션 추가
- Presto는 Hive 메타 정보를 이용하는데 파티션을 인식 시키기 위해서는 "alter table add partition" 명령을 실행해야 합니다. 따라서 위 구성에서는 datehour가 파티션 구성이기 때문에 주기적(1시간 단위)으로 다음 시간대의 파티션을 미리 생성합니다.
- ExecuteProcess 를 이용하였으며 linux shell script를 실행하도록 설정
- 스케쥴 설정은 Cron Expression으로 "0 10 * * * ?" 로 설정하였습니다.
- 과거 데이터 삭제
- 글의 초기에 밝혔듯이 여기 저장된 데이터는 단순히 Dashboard 계산용이기 때문에 계산된 이후에는 불필요한 데이터입니다. 따라서 1일 정도만 보관하고 삭제 하고 있습니다.
- ExecuteProcess 를 이용하였으며 linux shell script를 실행하도록 설정
- 스케쥴 설정은 Cron Expression으로 "0 20 * * * ?" 로 설정하였습니다.
위 Flow는 다음 Template 파일을 NiFi에 로딩하면 확인할 수 있습니다.
이번 글에서는 코드 한줄 없는 Dashboard를 만들기 위한 시스템 구성과 NiFi를 이용하여 Kafka의 큐에 저장되고 있는 데이터를 HDFS에 저장하는 방법에 대해 살펴 보았습니다. 다음 글에서는 HDFS나 MySQL에 저장된 데이터를 Presto Query를 이용하여 어떻게 Dashboard를 구성하는지에 대해 살펴보도록 하겠습니다.