Corsera Machine Learning으로 기계학습 배우기 : week1

개요
알파고 등장 이후 시점으로 거의 대부분의 IT 기업에서 AI 그중에서도 머신러닝에 관심을 보이는 것을 어렵지않게 확인 할 수 있습니다.
그러나 이러한 트렌드에 맞추어 공부를 하기에는 막막하기도 하고 수학공식들에 압도당하기도 합니다.
2년 전쯤 인터넷에 유행했던 수학을 포기한 직업 프로그래머가 머신러닝 학습을 시작하기위한 학습법 글을 보면 Andrew. NG 교수의 코세라 머신러닝 강의가 머신러닝을 배우기 위한 가장 좋은 방법중의 하나라고 나옵니다.
이에 따라 필자가 코세라 강의를 정주행 하였는데 학습과정에서 한글로 정리한 슬라이드를 공유할까 합니다. 목적은 영어로 강의하는 코세라 강의를 보실 때 참고하시거나 강의를 따로 안보시더라도 슬라이드 내용만으로도 참고하시면 좋을듯 합니다.
편의상 앞으로의 글에서 경어체를 생략합니다.
글을 읽기에 앞서...
- 본글은 필자가 코세라 기계학습을 공부를 하는 과정에서 개념을 확고히 정리하기 위하는데 목적이 있다. (필자가 나중에 내용을 다시 찾아보기 위한 목적이 있다.)
- 코세라 강의 week 개수에 맞추어 포스팅을 진행할 예정이다.
- 코세라의 슬라이드에 한글 주석을 단것이 핵심으로 내용에서 글을 읽을 필요 없이 슬라이드 그림만으로 최대한 이해가 되게끔 하는데 목적이 있다.
- 수학은 한국의 고등수학을 베이스로 한다. 수학적 개념이 나올때 가급적 고등학교 수학을 베이스로 내용을 정리한다.
- 정리내용의 목차 구성을 코세라 강의와 동일하게 맞추고 또한 제목을 원문으로 둔다. (원본강의 내용과 정리 내용을 서로 서로 찾아보기 쉽게하기 위함이다.)
====================== 1강 ============================================
Introduction
Welcome



강의에서 배우는 것
- 최신의 기계학습 알고리즘
- 실전 연습을 통해 현재 사용되는 알고리즘을 직접 돌려보고 이해하는 것
알고리즘이 어떻게 유도되는지는 이해하는 것은 optional이지 필수가 아니다.
What is Machine Learning?





기계학습의 정의 2가지
2명의 전문가가 아래와 같이 정의함
Arthur Samuel(전통적 정의)
기계학습은 컴퓨터가 명시적으로 프로그래밍 되지 않아도 배울수 있도록 하는 과학이다.
Tom Mitchell
컴퓨터 프로그램이 T라는 작업을 수행하며 E라는 경험으로부터 배우고 이 품질은 P로 측정된다. 알파고로 유명한 바둑을 예로 들자면 아래와 같게 된다. E = 바둑을 여러판 두면서 얻게되는 경험 T = 바둑을 두는 작업 P = 알파고가 다음판에서 이길 확률
Supervised Learning

Supervised Learning의 2종류
- 분류(Classification) : 값이 이산값(Discrete)
- 회귀(Regression) : 연속된 값(Continuous)
- 그중에서도 강좌에서는 선형회귀(Linear Regression)을 다룸
- 입력변수 1개로 설명함
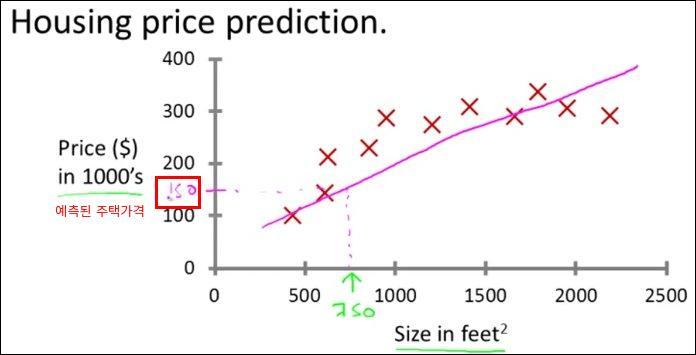
포틀랜드 feet당 주택가격 예제(이해를 돕기 위해 예제먼저)
해당 예제는 필자가 이해한 방식대로 설명한다.
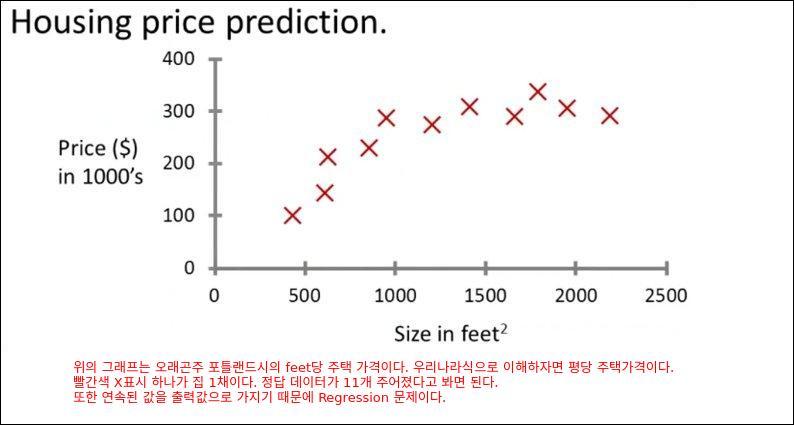
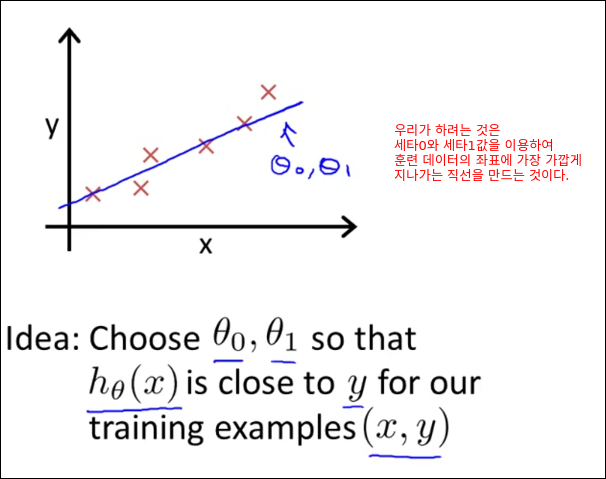
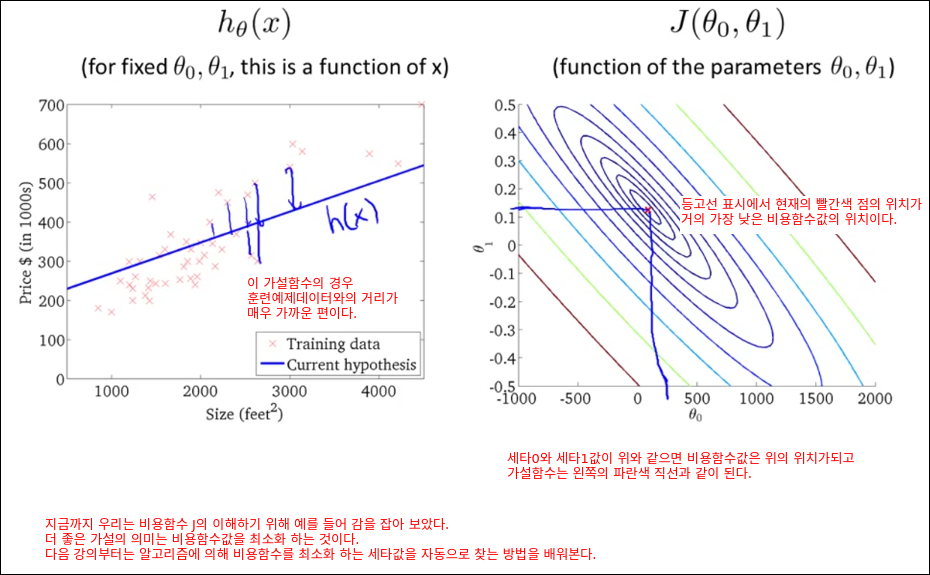
빨간 X표시의 값들을 학습하여 모델을 만든다는 행위는 빨간 X점들을 최대한 가깝게 지나가는 1차원 함수를 학습을 통해 만들어내는 행위가 될 수 있다. 즉, 아래와 같은 1차원 함수를 만들어내는 것이다. 다시말해 각 점으로부터 직선까지의 거리의 합이 가장 최소화 될수 있는 1차원 함수를 찾는것이다.

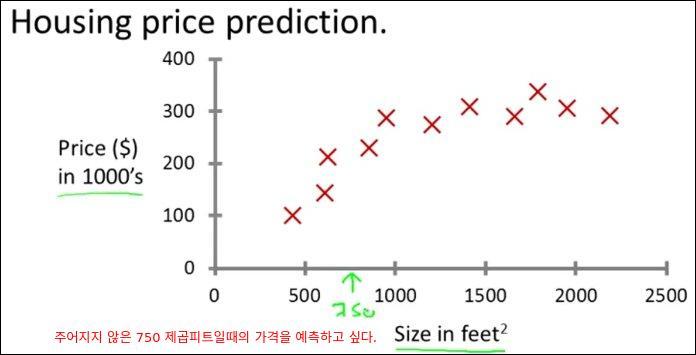
그러면 만들어진 모델(1차원 함수)를 통해 750 제곱피트일때의 가격이 15만 달러라고 예측 할 수 있다.
학습된 모델이 2차원 함수라면 아래와 같이 될 것이다. 이때는 750 제곱피트일때의 가격이 20만 달러가 된다. 학습모델이 1차원 함수가 될지 2차원 함수가 될지는 우리가 정하는 것이다. 이것이 Supervised Learning의 좋은 예이다.
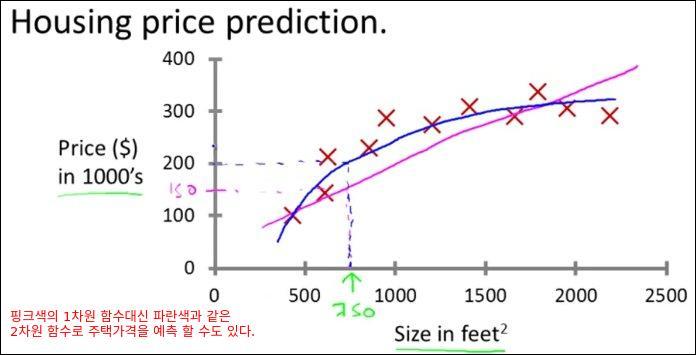
이렇게 학습된 모델을 가지고 답을 모르는 데이터를 넣으면 예측값을 출력해준다. 이 예제에서 학습된 적이 없는 평수를 입력하면 예측된 집값을 출력해준다.
포틀랜드 feet당 주택가격 예제는...
- Supervised Learning이다. 이유는 정확한 답을 알고있는 데이터를 가지고 학습을 수행했기 때문이다.
- Regression 문제이다 : 연속된 값을 예상하기 때문 (출력값은 가격)
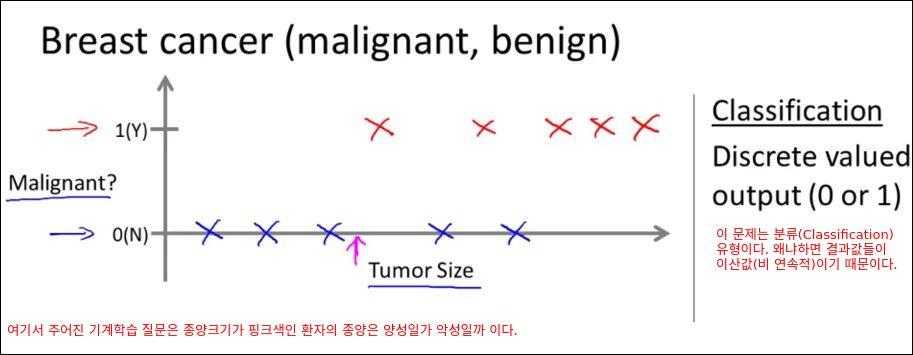
분류(Classification) 문제 예시 : 유방암 환자의 종양 크기 별 양성/악성 종양 유무
아래의 예제는 유방암 환자의 종양 크기 별 양성/악성 종양 유무를 나타내는 그래프이다. 입력은 종양의 크기이고 출력은 종양의 양성/악성 여부이다.

여기서 기계학습의 질문은 이 데이터를 학습시켰을때 핑크색의 종양 크기는 양성인지 악성인지를 판단하는 것이다. 이문제는 분류(Classification) 문제인데 이유는 학습 결과값이 연속된 값이 아닌 이산값(비연속적인 값)이기 때문이다. 즉 양성종양이냐 악성종양이냐로 결과가 딱 떨어지기 때문이다.
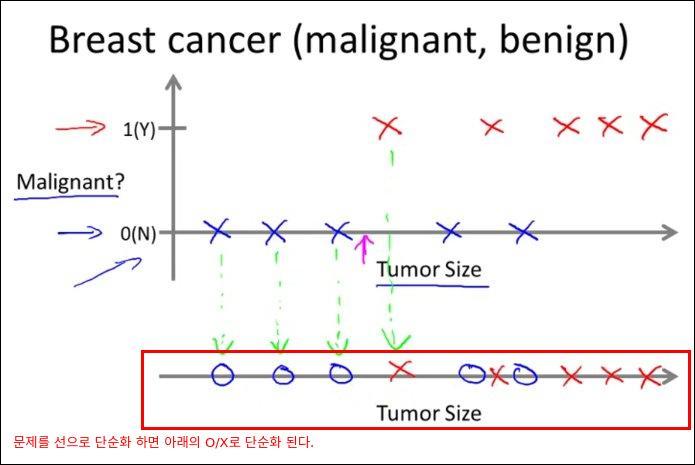
문제를 2차원에서 선으로 단순화 해서 설명하면 아래와 같다.
나이/종양크기별 악성/양성 종양 유무
예를 하나 더 들어 나이/종양크기별 악성/양성 종양 유무를 나타내는 그래프를 보자.

여기서 기계학습의 질문은 핑크색과 같은 나이와 종양크기를 가진 환자의 종양은 양성일까 악성일까 이다.
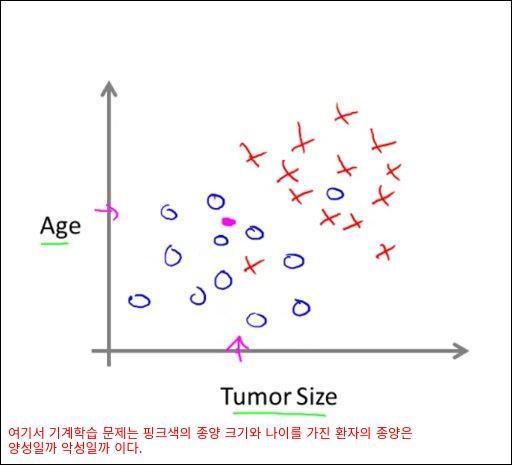
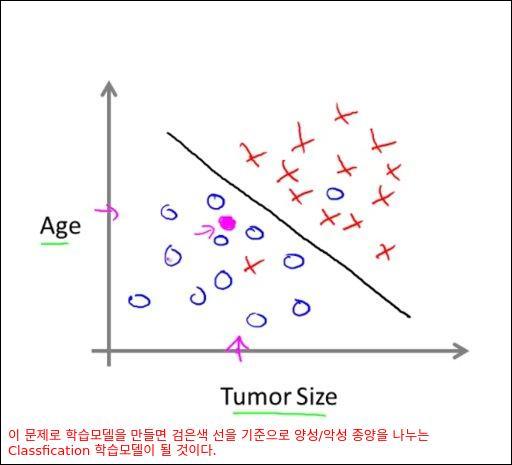
이 분류(Classification) 문제를 학습하여 모델을 만든다면 검은색 선을 기준으로 나이/종양 크기별로 양성/악성 유무를 판단하는 모델이 만들어 질 것이다.
Unsupervised Learning

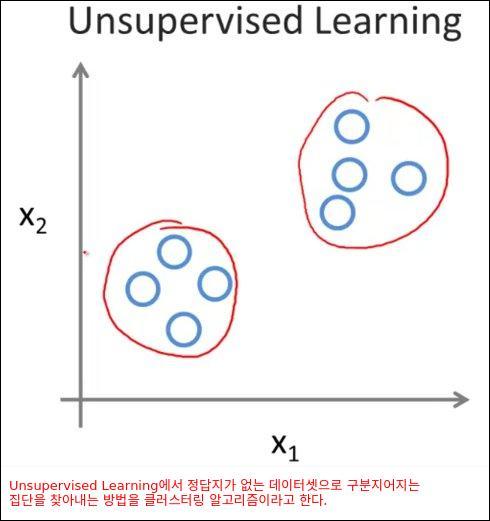
Unsupervised Learning은 정답지가 없는 데이터셋에서 기계학습에 의해 자동으로 구조적 특징을 찾아내는 것이다. Unsupervised Learning의 핵심은 데이터간의 거리를 어떻게 측정할 것인지가 가장 중요하다.

아래와 같이 정답지가 없는 데이터로 집단을 나누는 Unsupervised Learning을 클러스터링 알고리즘이라고 한다.
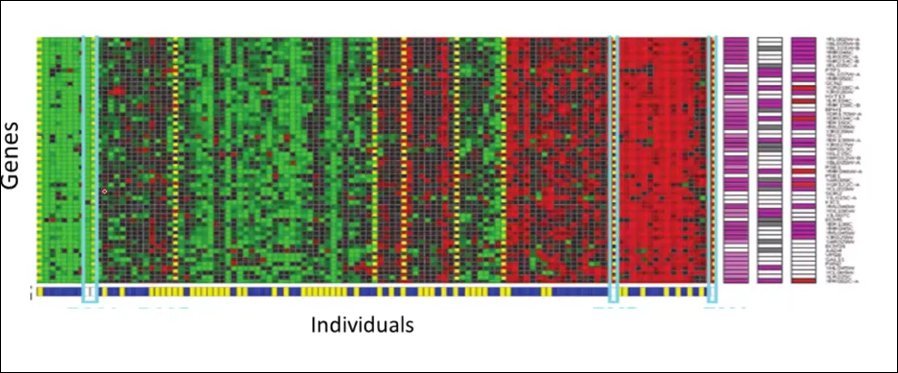
다른 예는 사람의 유전자 정보를 많이 입력하면 기계적으로 유전자별 구조를 분류해내는 것이다. 가로가 사람들 세로가 유전자 구성이다. 비슷한 유전자의 패턴을 묶어보는 것이다.
Model and Cost Function
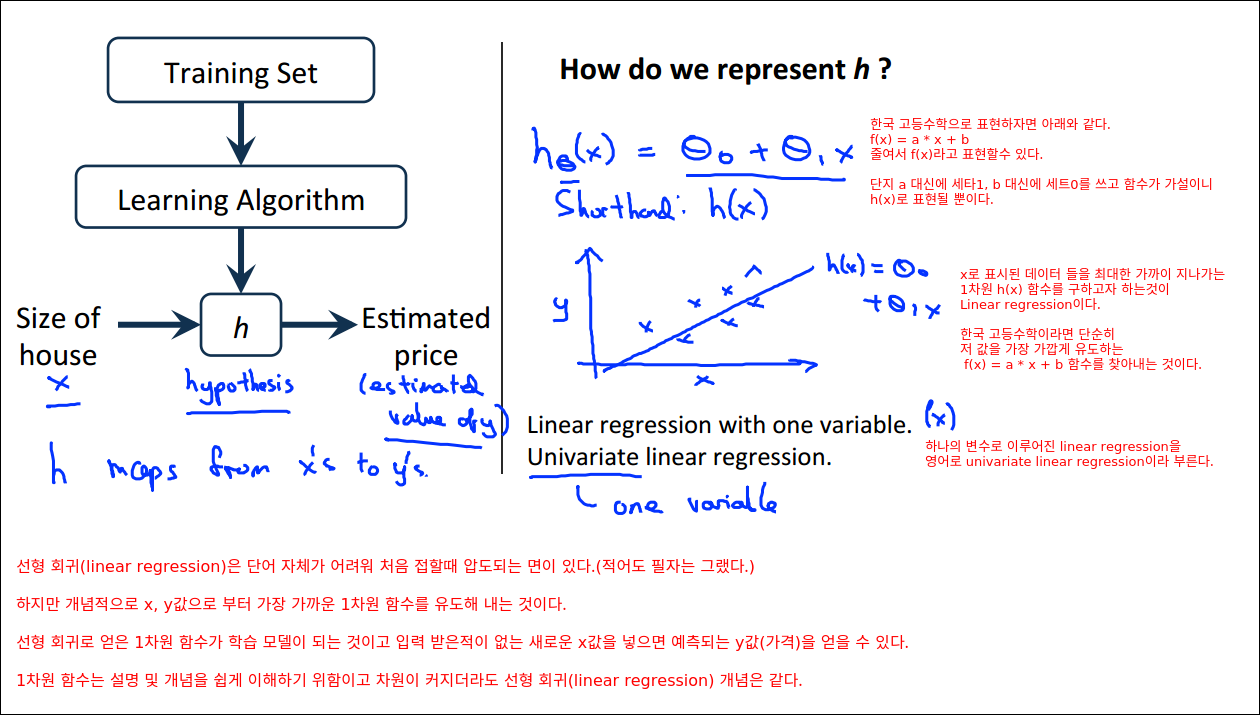
Model Representation
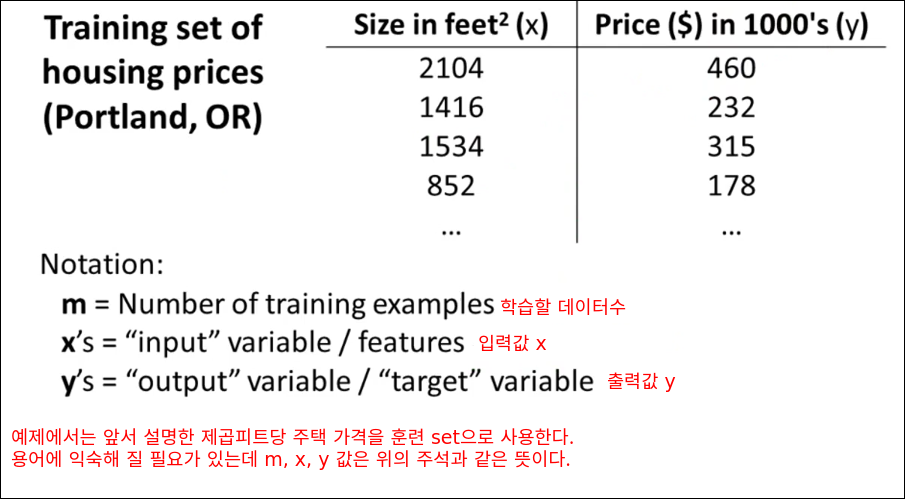
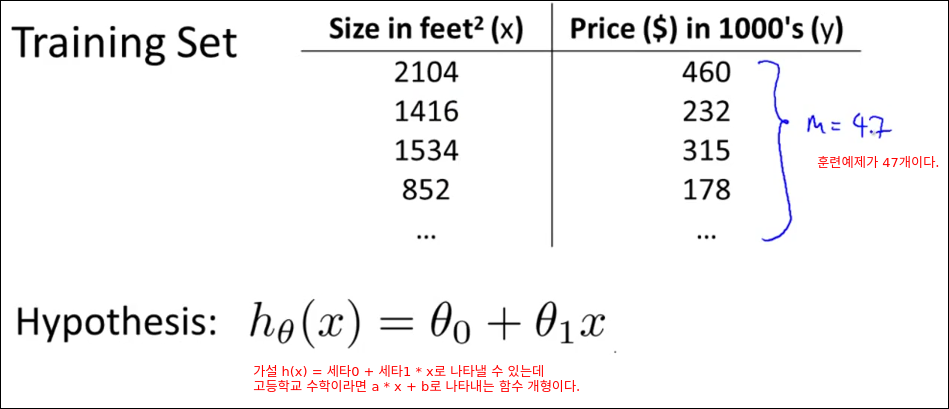
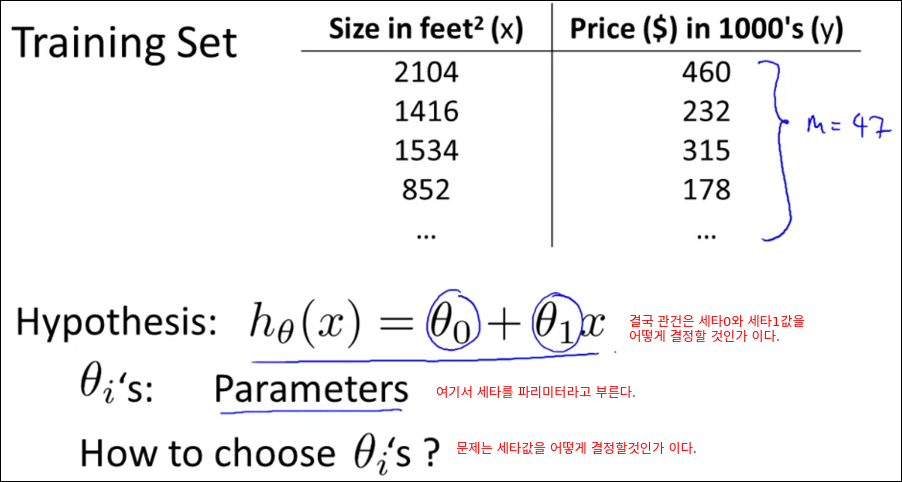
테이블이 의미하는 것은 집의 크기(제곱피트)당 집의 가격이다. m은 학습에 사용하는 데이터 수를 의미한다., x는 입력 혹은 feature로 표현된다.(집의 크기) y는 출력 혹은 target 변수로 표현한다.(집값)
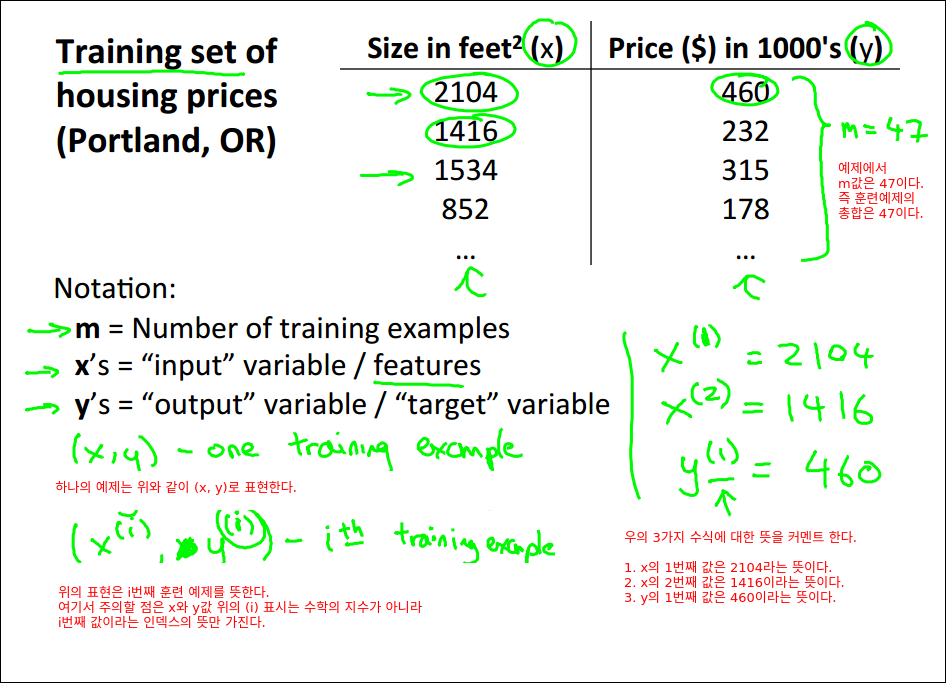
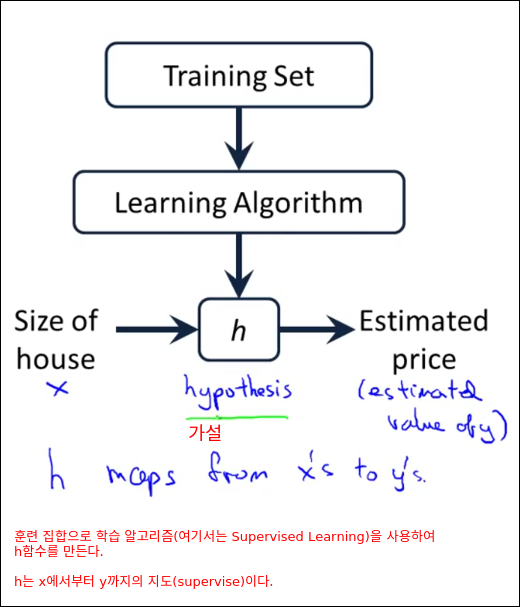
47개의 학습 데이터를 가지고 학습을 돌린다(에러를 줄인다). 그릴 통해 h모델을 만든다. 이 만들어진 모들에 입력된 적이 없는 집의 크기를 넣으면 예상된 집값을 출력해준다.
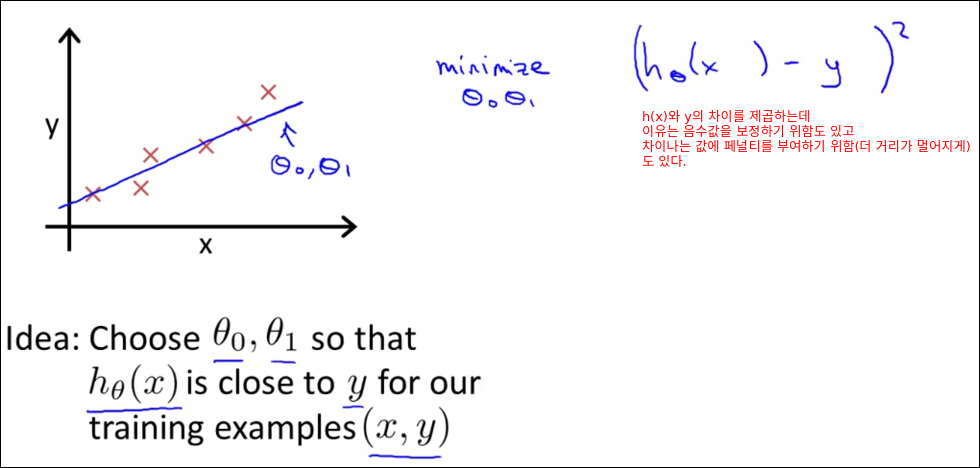
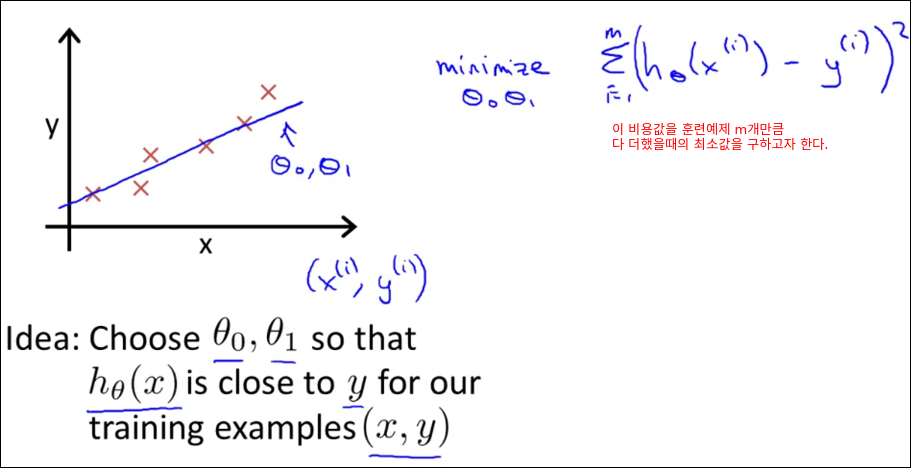
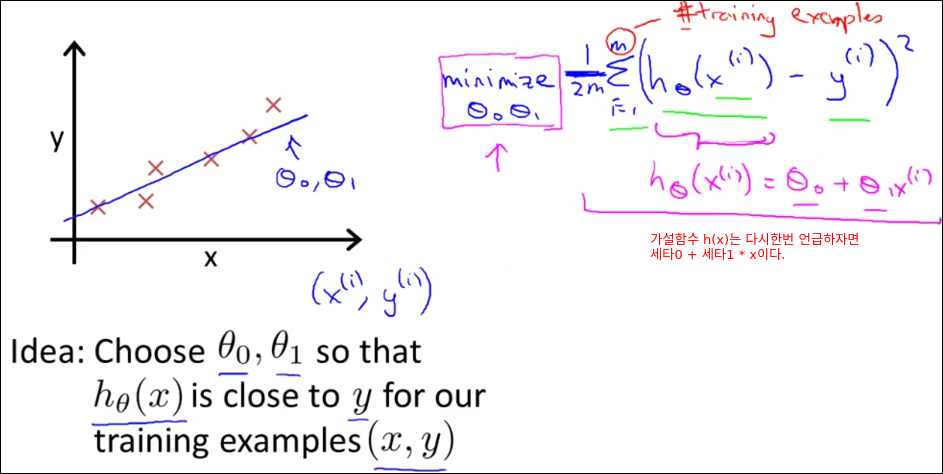
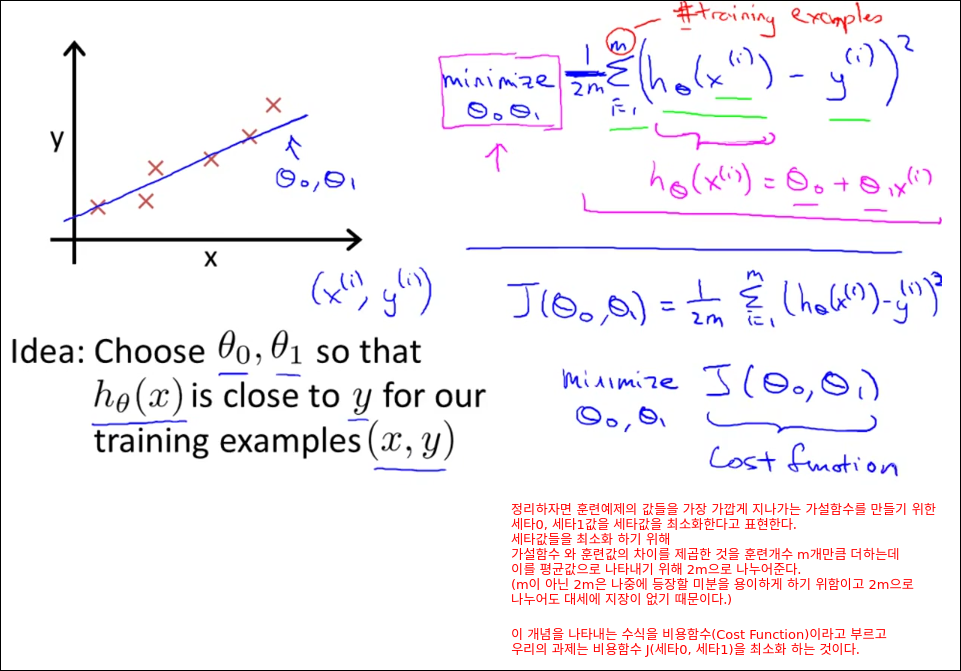
Cost Function(비용함수)

Cost Function은 다른말로 Error Function Loss Function이라고도 불린다.
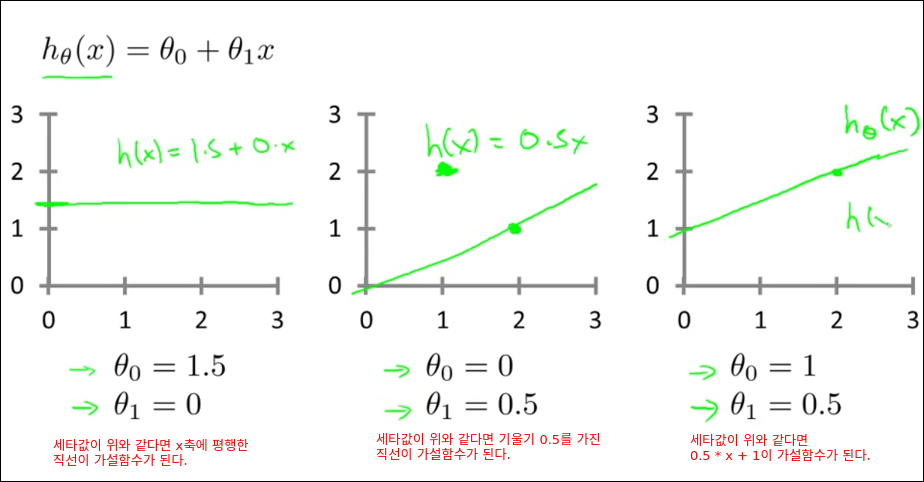


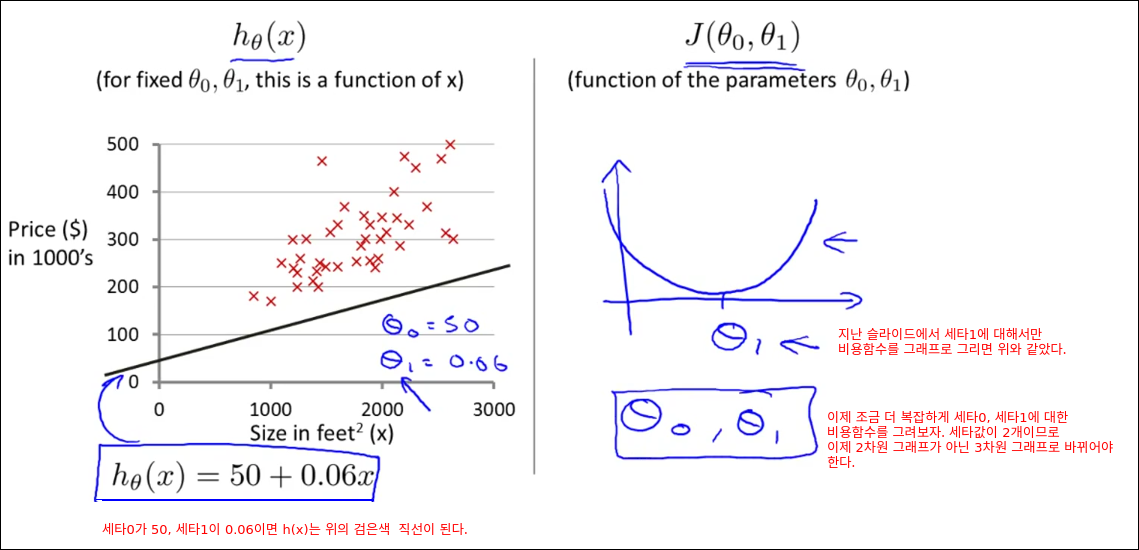
Cost Function Intuition I




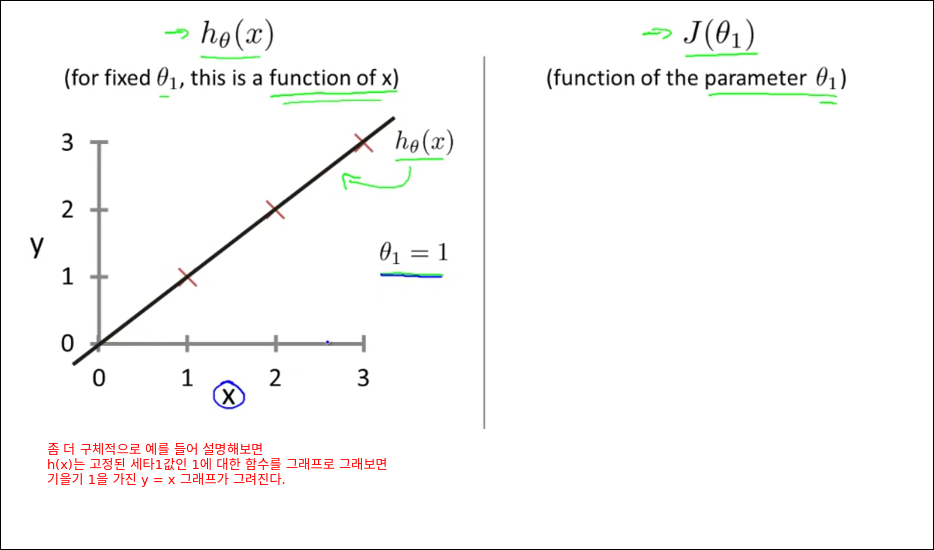
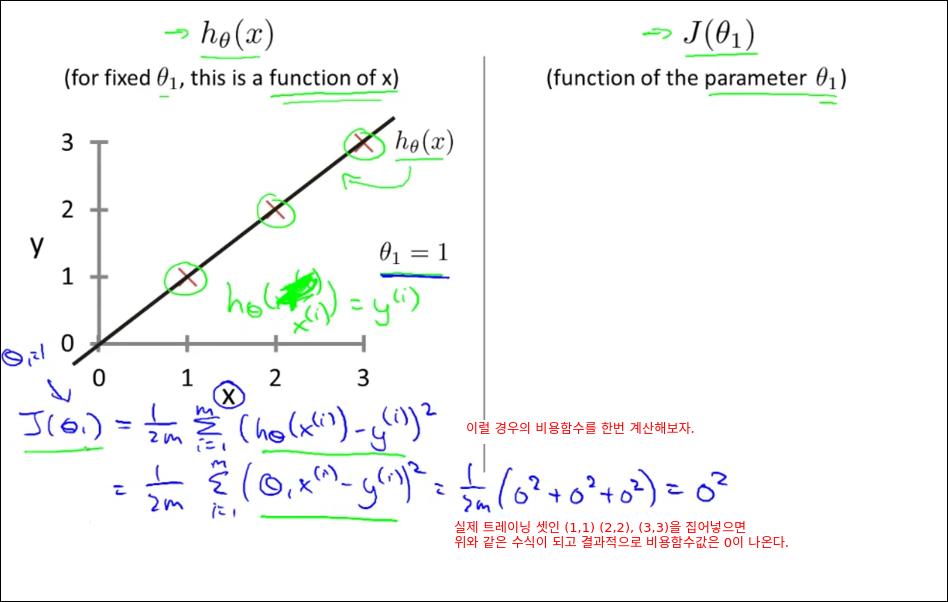
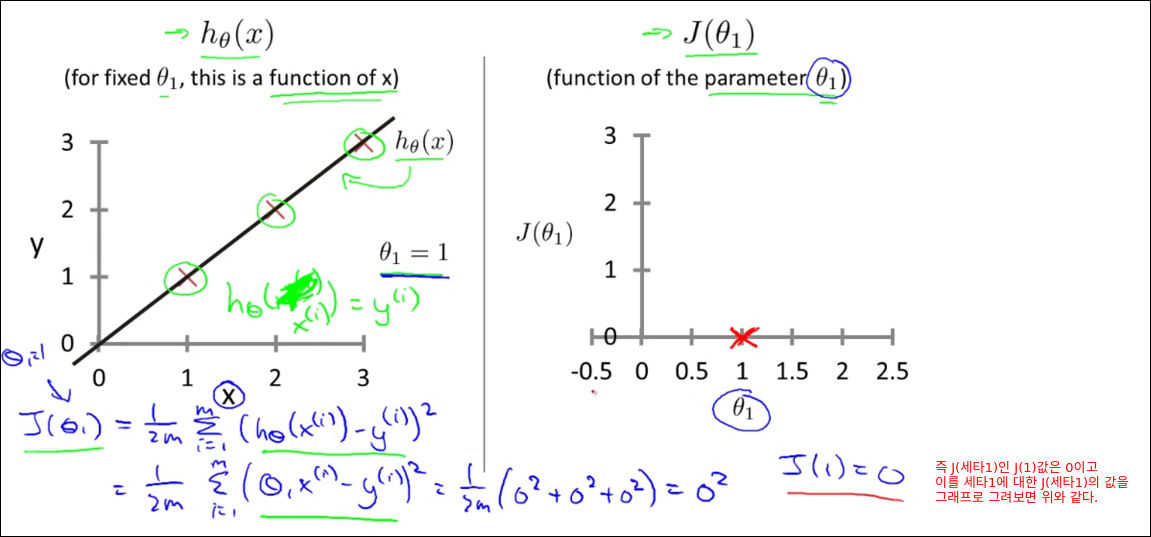
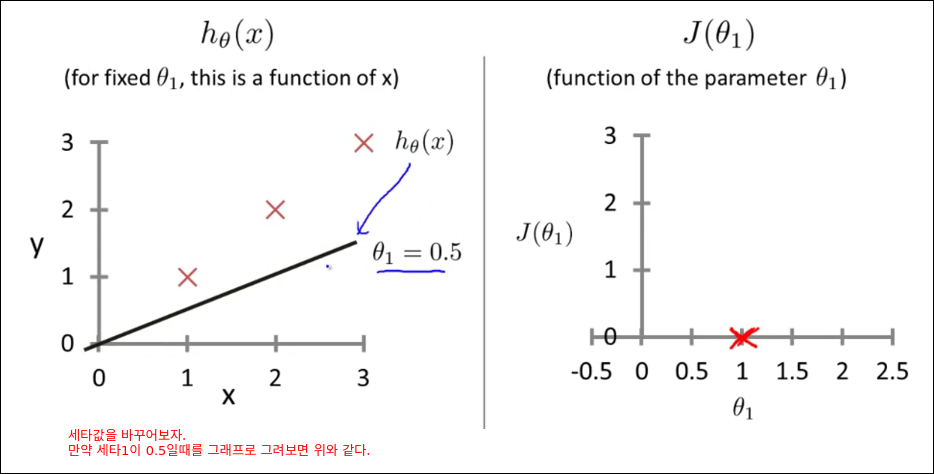
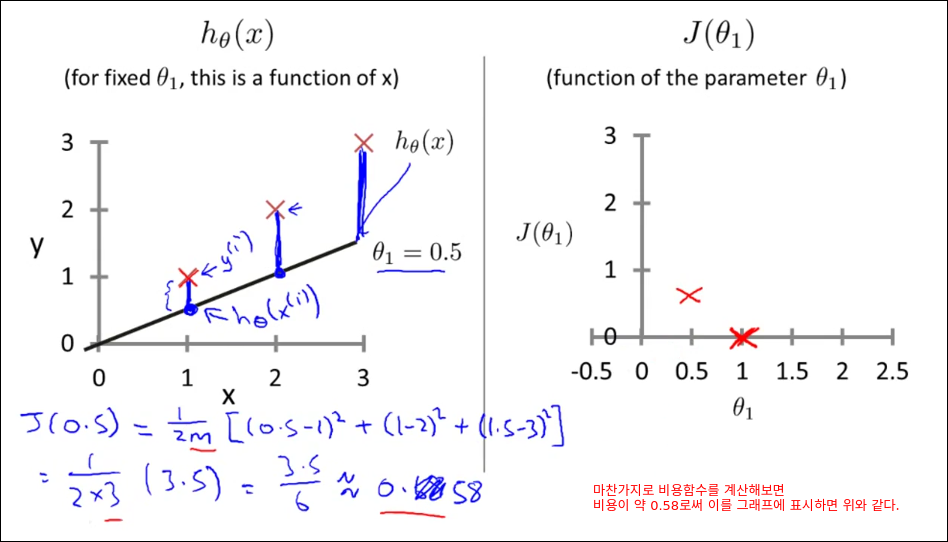
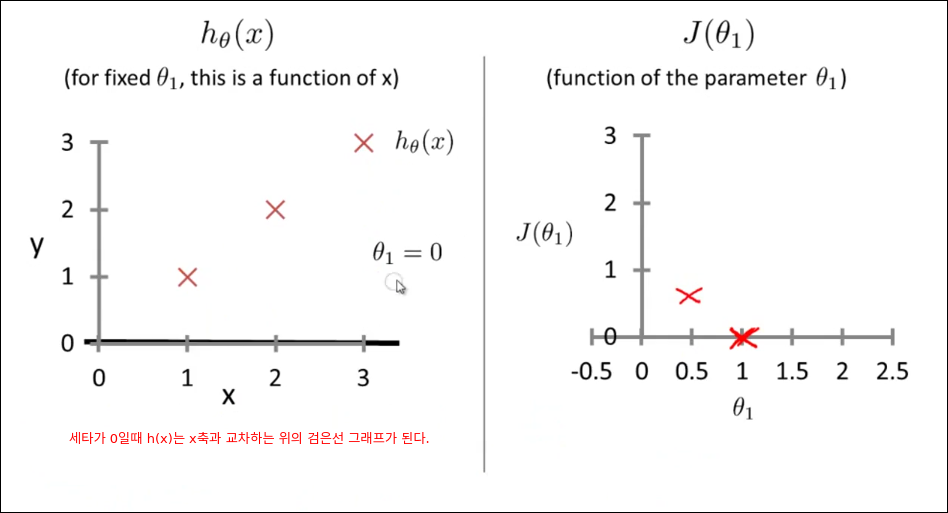
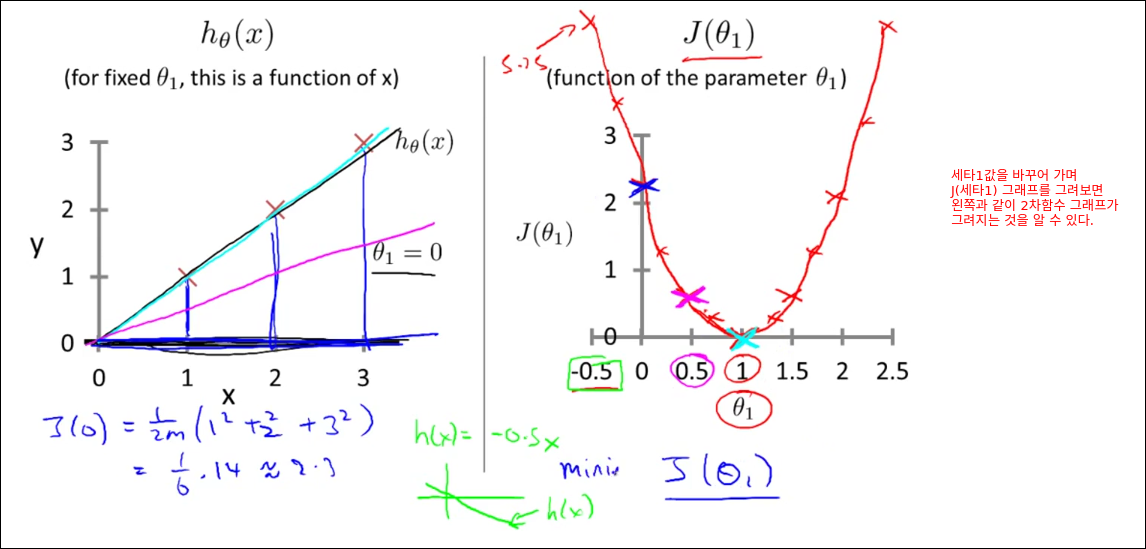
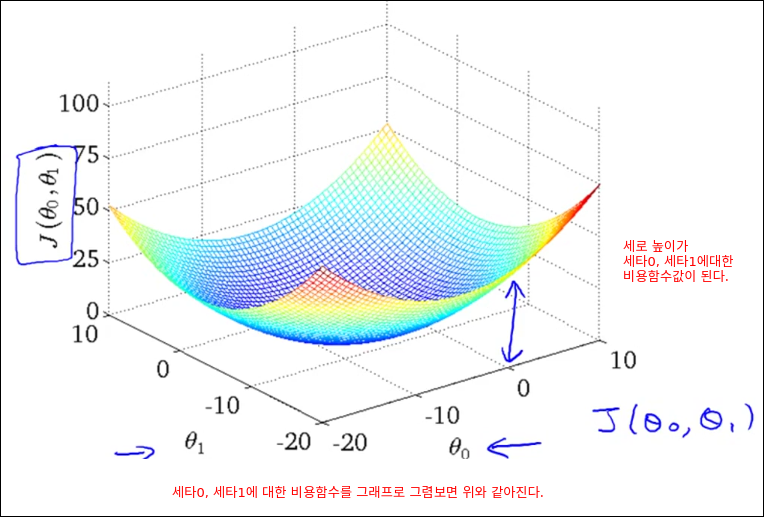
Cost Function Intuition II

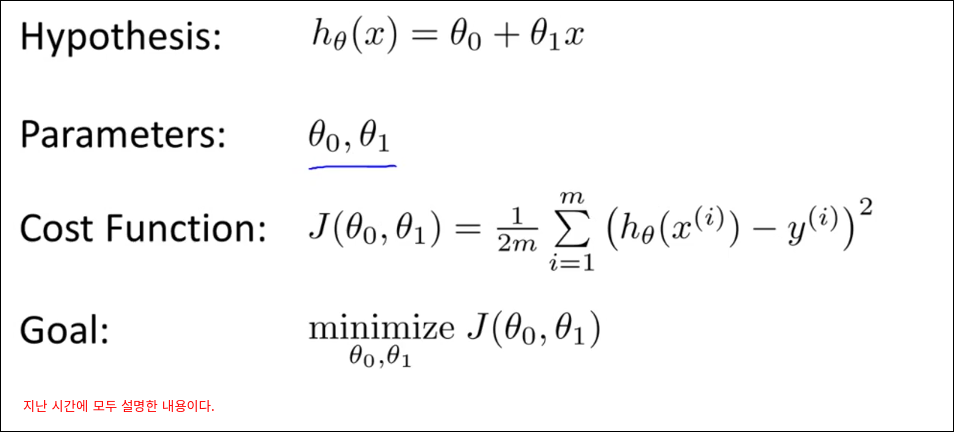
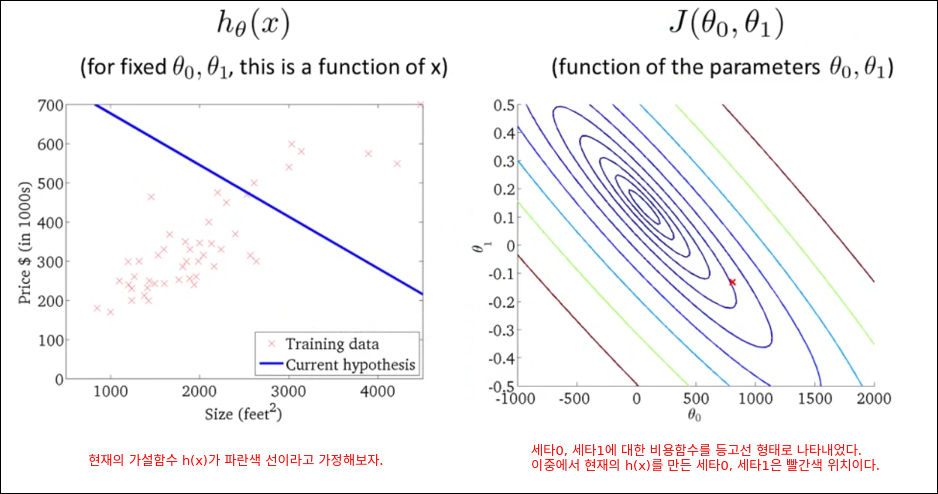
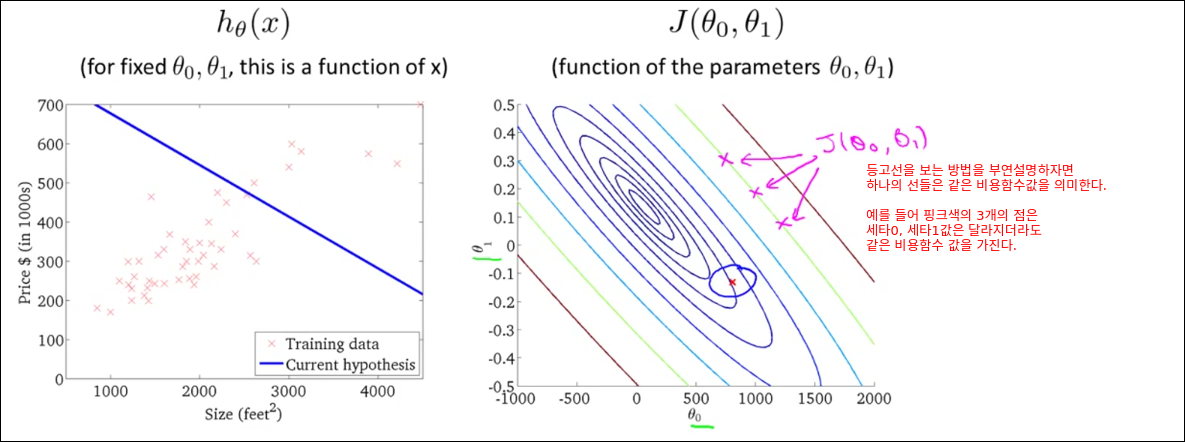

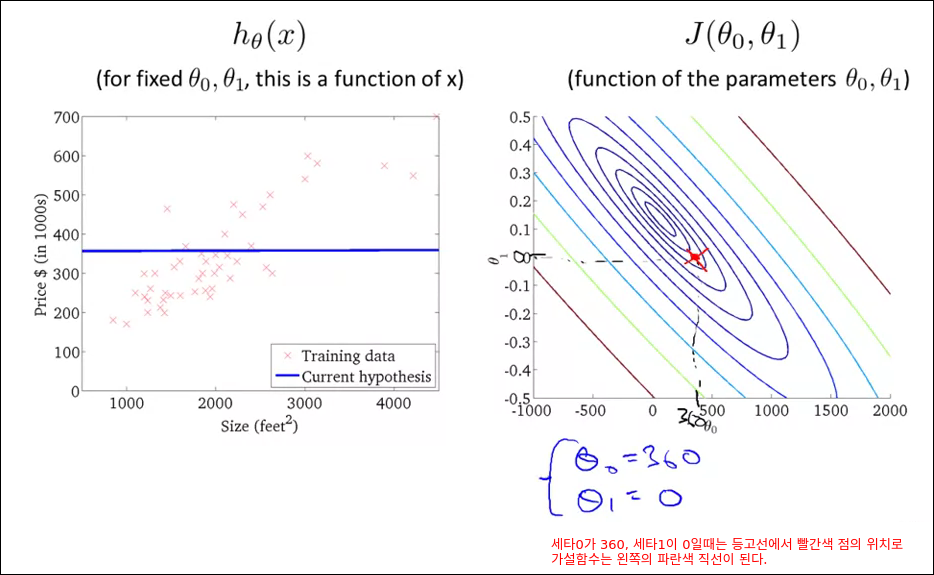
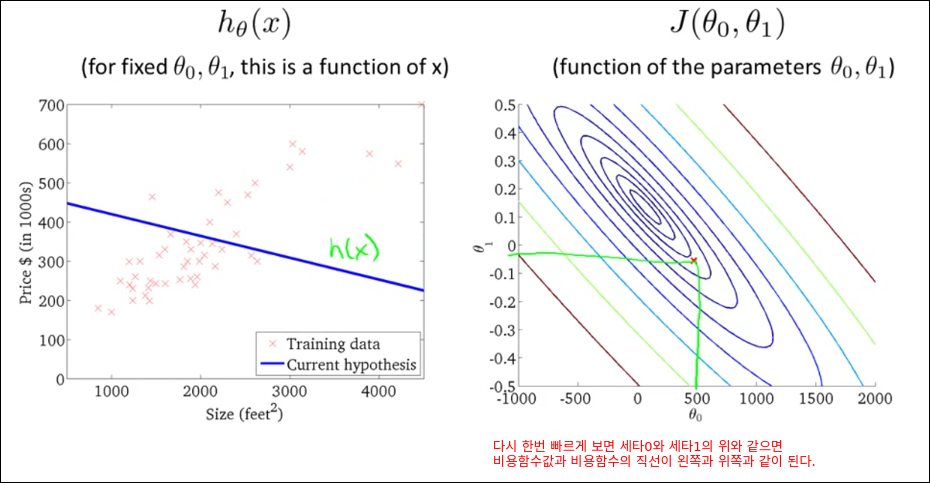
기계학습의 성능 병목은 미분이다. 이를 GPU를 통해 병렬화 하는 것이 기계학습 성능을 향상시키는 것이다.
Parameter Learning
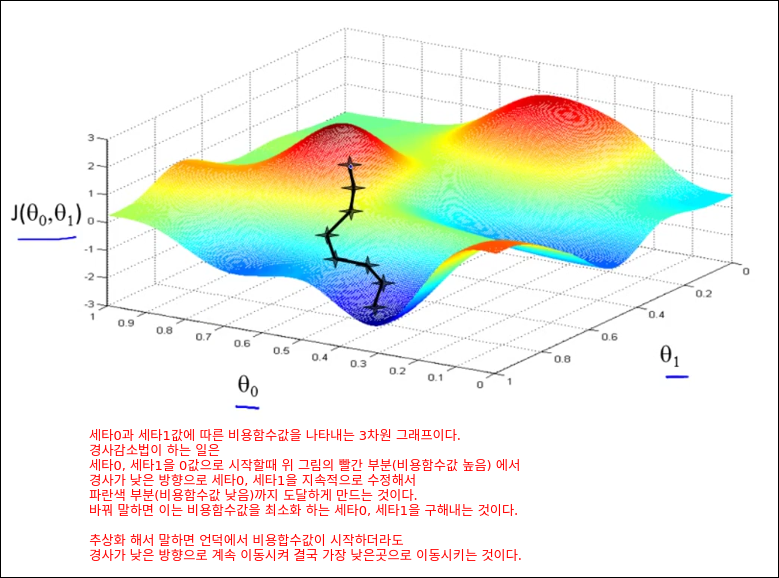
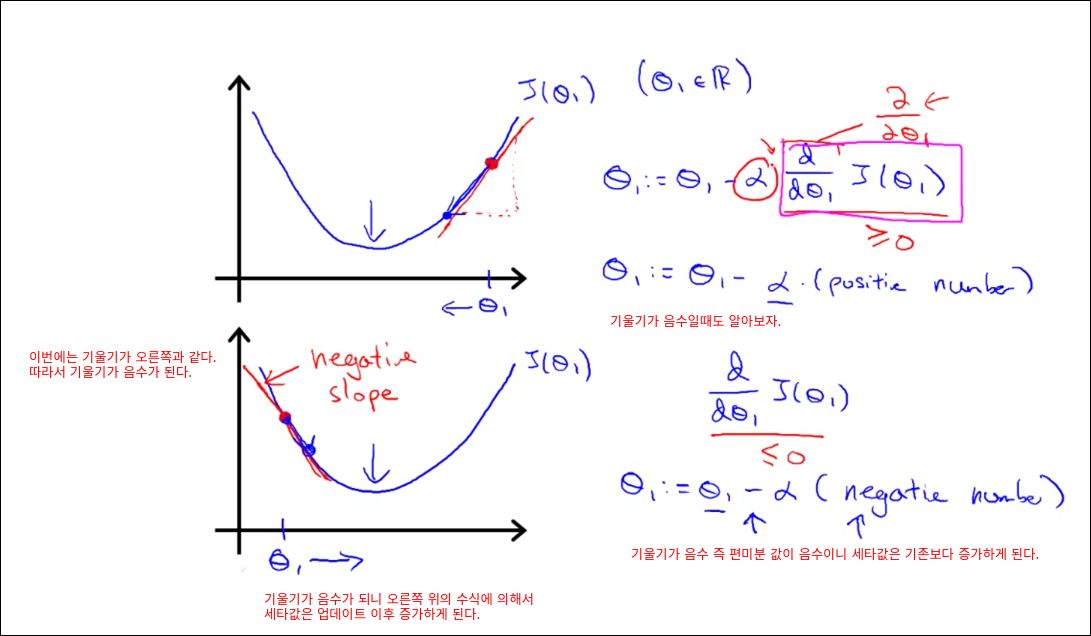
Gradient Descent







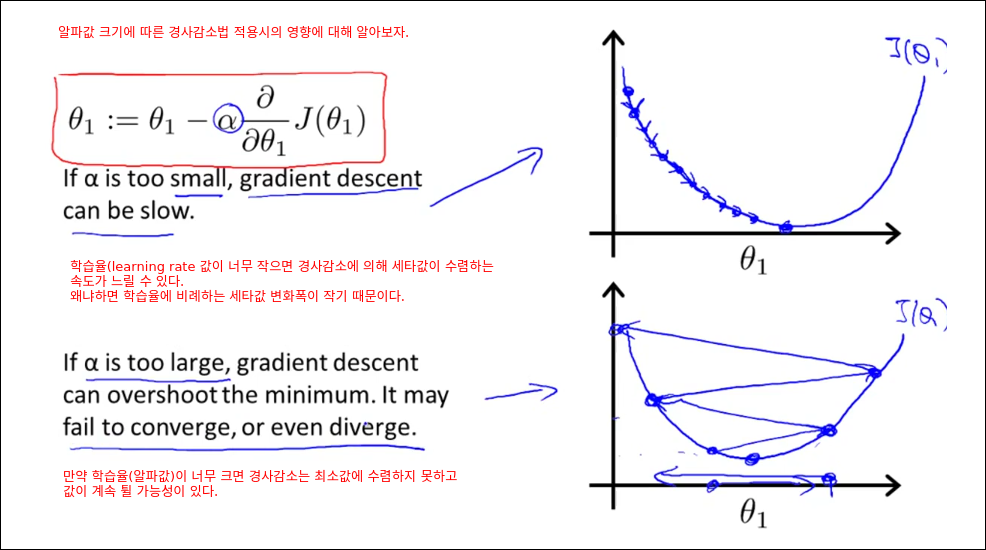
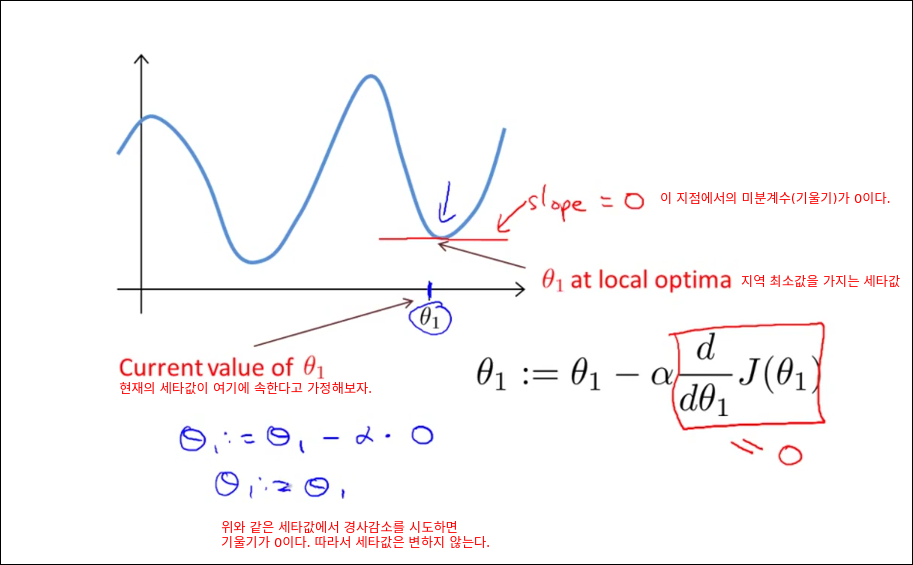
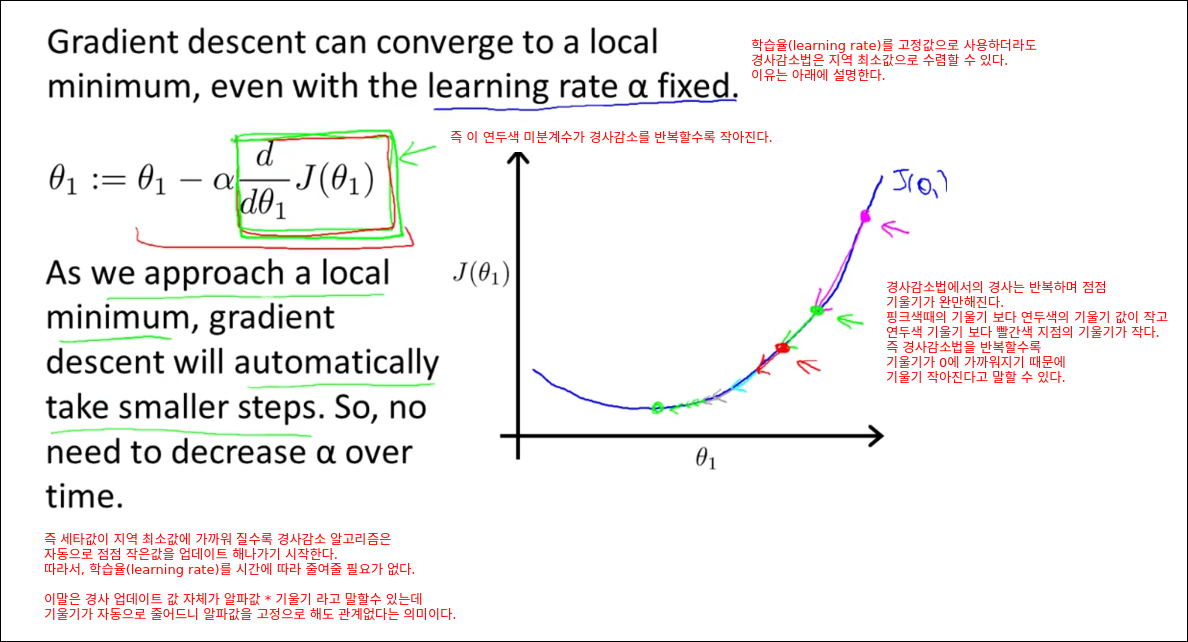
Gradient Descent Intuition


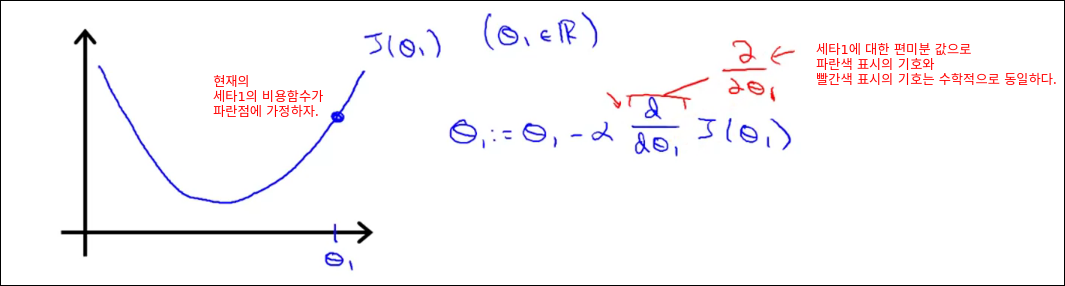
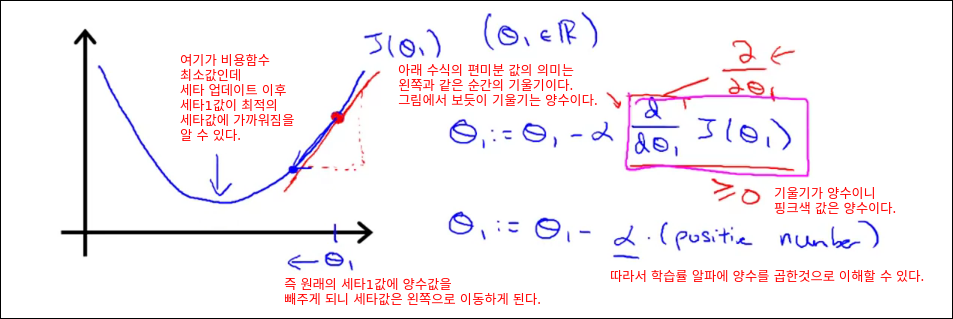

Gradient descent for linear regression

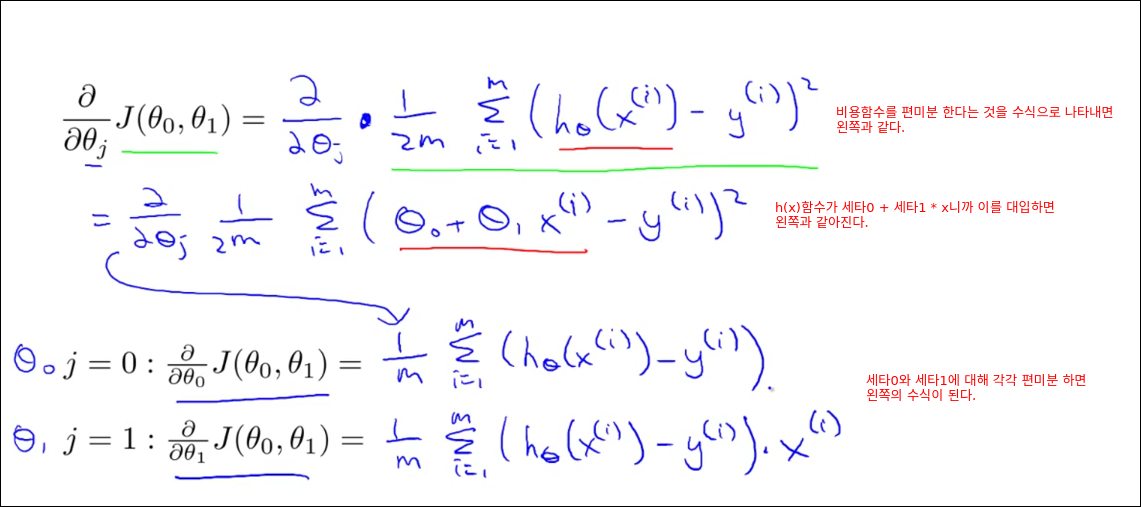


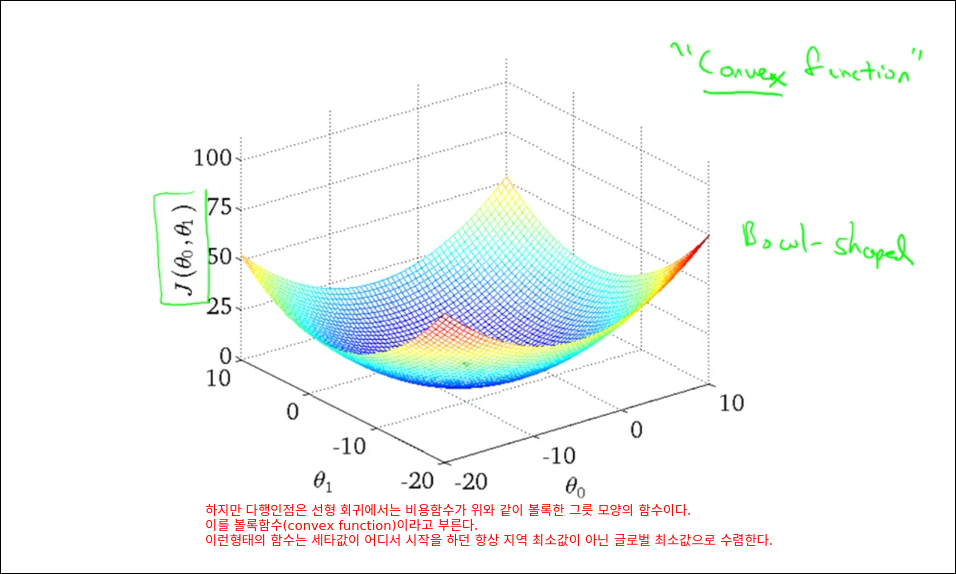
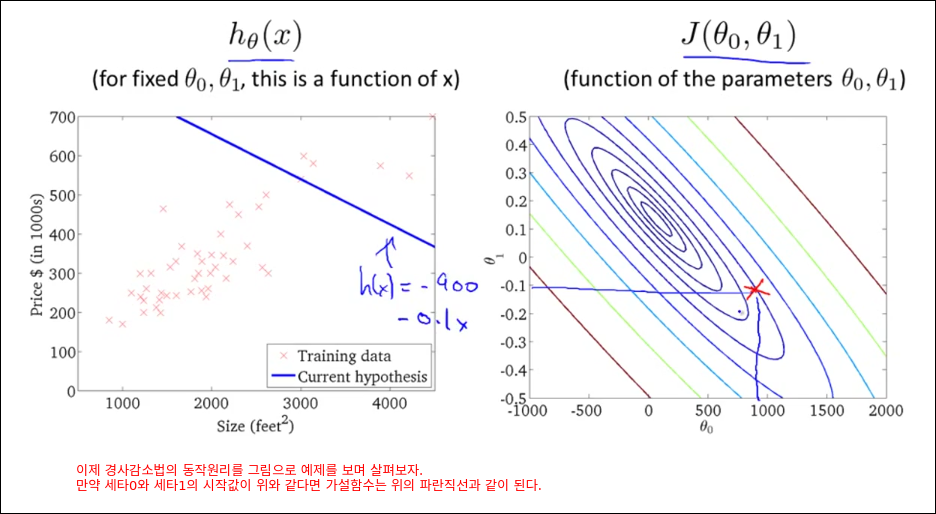
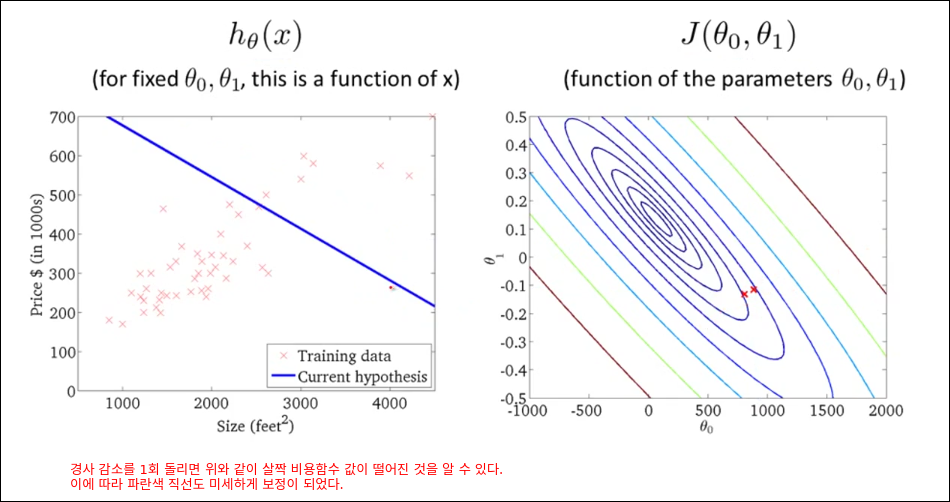
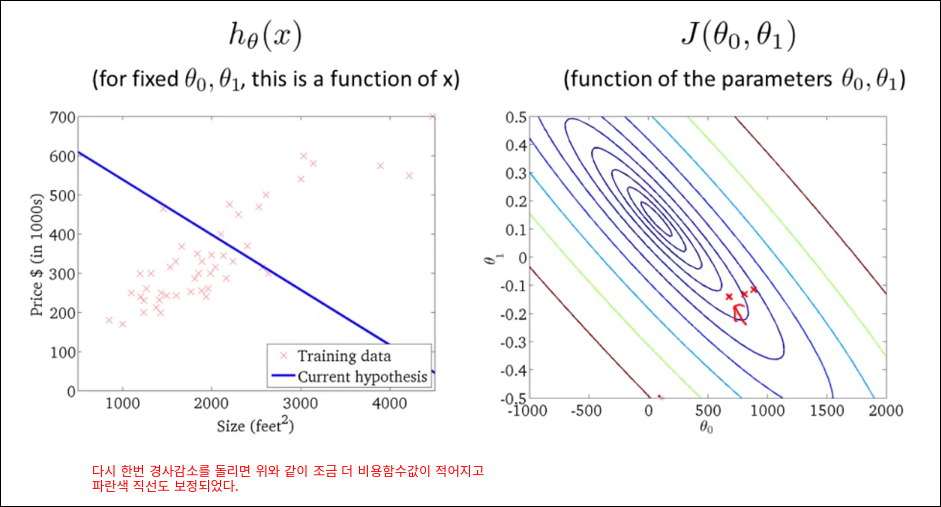
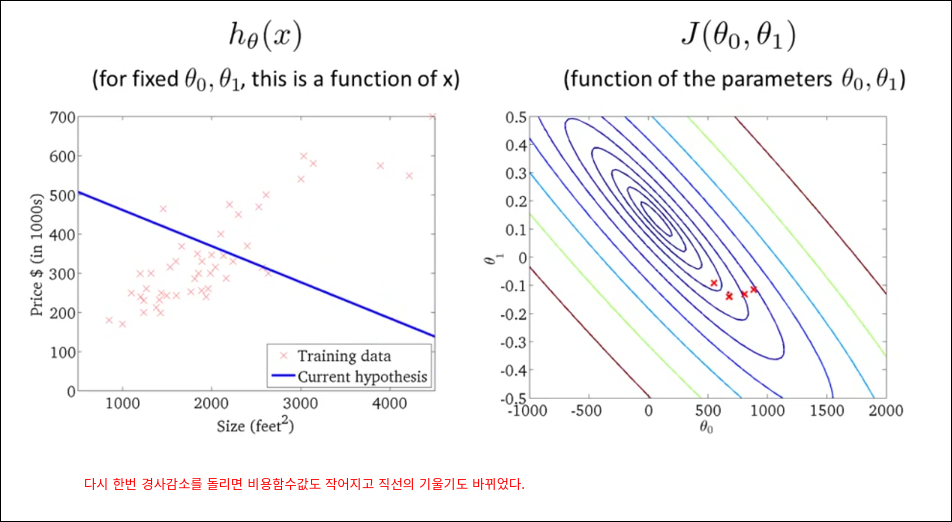
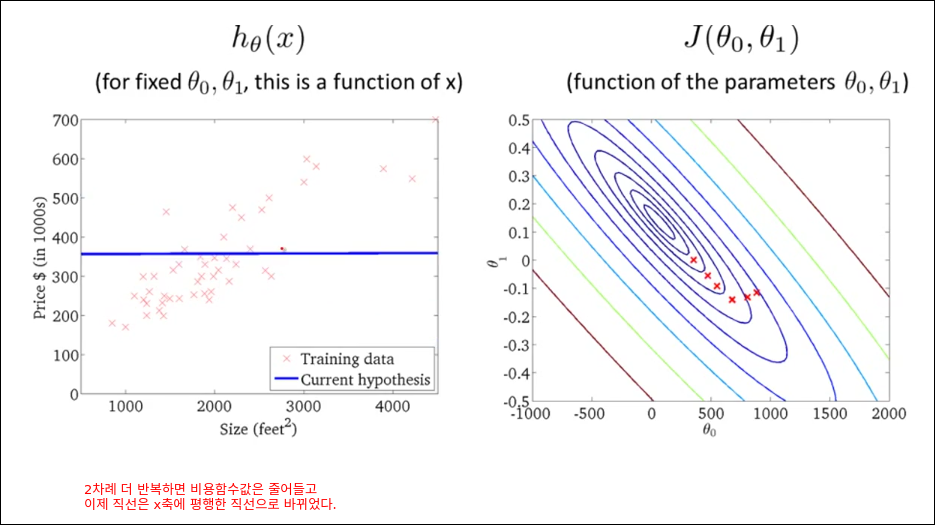
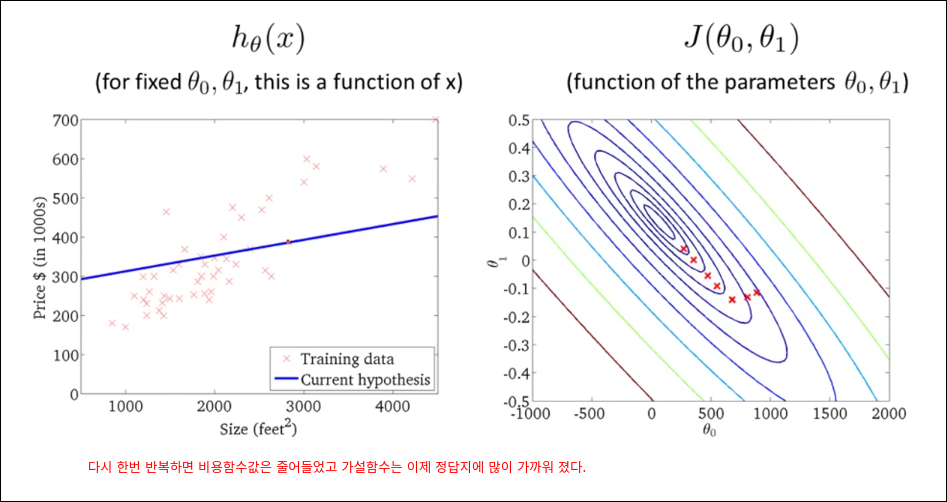
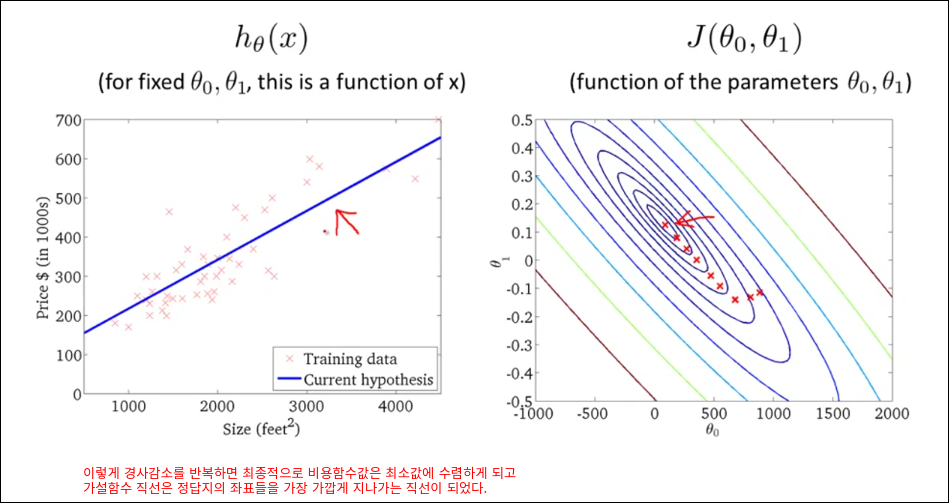
모든 훈련예제를 가지고 경사 감소를 1번 계산한다. 딥러닝은 아래와 같은 방법으로 epoch을 돌리면 너무 오래 걸리기 때문에 mini batch를 활용한다.

