MXNet을 활용한 이미지 분류 앱 개발하기

최근 딥러닝 기반으로 이미지를 분류하는 앱을 시연해야하는 일이 생겼다. 주요한 요건은 기기-서버 사이의 네트워크 사용량을 최소화하는 것으로, 네트워크가 없는 곳에서도 사용이 가능해야 한다는 점이다. 따라서 모바일에서 촬영한 이미지를 서버로 전송하고, 서버에서 학습된 모델을 기반으로 이미지를 분류한 결과를 전달하는 API 방식은 사용할 수 없다. 대신 서버에서 학습한 모델을 모바일 기기에 임베딩하고, 예측(prediction) 인터페이스를 통해 모바일 기기 내에서 분류하는 형태의 개발이 필요하다.
텐서플로우는 모바일을 지원하며, 토치 또한 모바일 버전을 지원한다. 그리고 MXNet도 모바일을 지원한다. 이 중에서 MXNet을 선택했는데, 무엇보다도 빌드 과정이 가장 단순해 보였기 때문이며, 이번 기회에 아마존이 선택한 딥러닝 프레임워크를 배워보고 싶기 때문이었다. 이 글에서는 MXNet을 살펴보고, MXNet을 이용하여 MNIST 분류기를 개발하는 방법을 소개한다. 그리고 MXNet 프레임워크를 안드로이드에서 사용할 수 있게 빌드하는 방법을 설명한다. 마지막으로 학습된 resnet-152 모델을 안드로이드에 탑재하여, 이미지 분류기를 개발하는 데모를 소개한다.
MXNet 소개
들어가기 전에
이 글을 통해 완성하려는 안드로이드 앱은 다음과 같다.
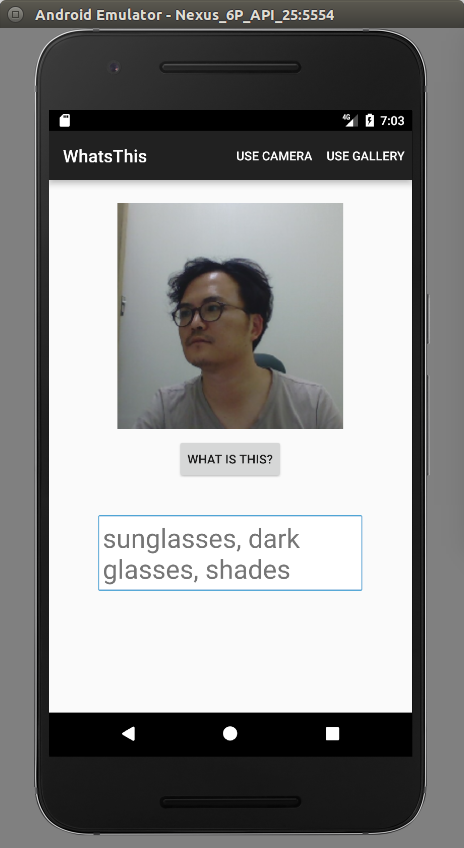
그림. 이미지 분류 App 데모 실행 화면
앱을 실행하여 분류하려는 이미지를 추가한 후 "WHAT IS THIS" 버튼을 클릭한다. 예측 결과로는 이미지에 포함된 개체를 이미지 하단에 출력한다.
MXNet 튜토리얼
MXNet이란
MXNet은 오픈소스 딥러닝 프레임워크로 최근 아마존에서 MXNet을 공식적으로 채택하면서 주목을 받고 있다. MXNet은 다음과 같은 특징을 가진다.
- Imperative 모델과 Symbolic 모델을 모두 지원
- 멀티 CPU / GPU 지원 및 CPU - GPU 모델간 switch가 단순함
- 서버 / 데스크톱 / 모바일 등 멀티 플랫폼 지원
- 분산 학습 지원
- 멀티 클라이언트 프로그래밍 지원
- 뛰어난 성능
MXNet 설치하기
MXNet을 설치한다. 플랫폼별 설치 방법은 MXNet: A Scalable Deep Learning Framework에서 확인할 수 있다. 여기에서는 "Python /Pre-built /Linux / CUDA8.0"을 선택했으며, virtualenv 환경에서 설치한다.
1 2 3 4$ virtualenv --system-site-packages mxnet $ source mxnet/bin/activate $ pip install --upgrade pip $ pip install mxnet-cu80 # GPU with CUDA 8.0
그리고 아래 모듈도 필요한 경우 추가로 설치한다.
1 2 3$ sudo apt-get install graphviz $ pip install graphviz # for mx.viz $ pip install matplotlib
Imperative vs. Symbolic
MXNet은 MixNet이기도 한데, Imperative 모델과 Symbolic 모델을 섞어서 프로그래밍할 수 있기 때문이다. Imperative 모델은 일반적인 프로그래밍 모델로, 예를 들면 아래와 같다.
1 2 3 4 5 6>>> a = mx.nd.array([1, 2, 3]) >>> b = a * 2 + 1 >>> print(b) <NDArray 3 @cpu(0)> >>> print(b.asnumpy()) [ 3. 5. 7.]
위와 동일한 코드를 Symbolic 모델로 구현하면 다음과 같다.
1 2 3 4 5 6 7>>> a = mx.sym.Variable('a') >>> b = a * 2 + 1 >>> ex = b.bind(ctx=mx.cpu(), args={'a': mx.nd.array([1, 2, 3])}) >>> ex.forward() [<NDArray 3 @cpu(0)>] >>> print(ex.outputs[0].asnumpy()) [ 3. 5. 7.]
심볼릭 프로그래밍 모델에서는 심볼을 이용하여 오퍼레이션에 대한 그래프를 먼저 정의한 후, 그래프에 실제값을 바인딩하여 실행시키는 과정을 거친다. 즉 오퍼레이션을 정의하는 과정과 오퍼레이션을 실행하는 단계가 분리되어 있다.
토치(Torch)는 Imperative 딥러닝 프로그래밍 모델이며, 텐서플로우(TensorFlow)는 Symbolic 모델을 사용한다. Imperative 모델은 기반 프로그래밍 모델(이 경우 파이썬)의 구문을 모두 활용할 수 있으므로 좀더 유연하며, 디버깅이 용이하다. 반면 Symbolic 프로그래밍 모델에서는 기반 프로그래밍 요소를 사용할 수 없으며, 주어진 심볼릭 구분만을 이용해야 하므로 제약이 따른다. 심볼릭 프로그래밍 모델은 DSL(Domain Specific Language)로 볼 수 있으며, 메모리 재사용이 가능하고 실행 과정이 최적화된다. 좀 더 자세한 설명은 Programming Models for Deep Learning에서 확인할 수 있다.
MXNet 기본 문법을 먼저 살펴보려고 한다. 관련 예제는 Github에서 다운로드할 수 있다.
1$ git clone https://github.com/socurites/mxnet-started
Imperative 모델: mxnet.ndarray 고속배열 사용하기
먼저 고속 배열인 ndarray를 사용하는 방법에 대해 소개한다. 관련 내용은 Tutorials > Python > Basics > CPU/GPU Array Manipulation을 참고했으며 예제 코드는 basics/ndarray_tutorial.py에 위치한다.
MXNet에서는 numpy의 고속배열인 numpy.ndarray와 유사한 mxnet.ndarry를 제공한다.
배열 생성하기
mx.nd.array 배열을 생성하는 방법에는 여러가지가 있으며, 파이썬 리스트를 이용하여 1차원 배열을 생성하는 방법은 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13>>> import mxnet as mx >>> import numpy as np >>> >>> # create a 1-dimensional array with a python list >>> a = mx.nd.array([1, 2, 3]) >>> print(a) <NDArray 3 @cpu(0)> >>> print(a.shape) (3L,) >>> print(a.dtype) <type 'numpy.float32'> >>> print(a.asnumpy()) [ 1. 2. 3.]
2차원 배열도 비슷한 방법으로 생성할 수 있다.
1 2 3 4 5 6 7 8 9 10 11>>> # create a 2-dimensional array with a nested python list >>> b = mx.nd.array([[1,2,3], [2,3,4]]) >>> print(b) <NDArray 2x3 @cpu(0)> >>> print(b.shape) (2L, 3L) >>> print(a.dtype) <type 'numpy.float32'> >>> print(b.asnumpy()) [[ 1. 2. 3.] [ 2. 3. 4.]]
기본 배열 타입은 numpy.float32이며, 배열 생성시 배열 타입을 지정할 수 있다.
1 2 3 4>>> # specify the element type with dtype ... a = mx.nd.array([1, 2, 3], dtype=np.int32) >>> print(a.dtype) <type 'numpy.int32'>
numpy와 마찬가지로 특수 배열 생성자를 지원한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21>>> # special initializers >>> a = mx.nd.zeros((2,3)) >>> print(a.shape) (2L, 3L) >>> print(a.asnumpy()) [[ 0. 0. 0.] [ 0. 0. 0.]] >>> >>> a = mx.nd.ones((2,3)) >>> print(a.shape) (2L, 3L) >>> print(a.asnumpy()) [[ 1. 1. 1.] [ 1. 1. 1.]] >>> >>> a = mx.nd.full((2,3), 7) >>> print(a.shape) (2L, 3L) >>> print(a.asnumpy()) [[ 7. 7. 7.] [ 7. 7. 7.]]
기본 오퍼레이션
배열 요소 단위의 기본 오퍼레이션은 다음과 같이 계산할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12>>> # element-wise operation >>> a = mx.nd.ones((2,3)) >>> b = mx.nd.full((2,3), 5) >>> c = a + b >>> print(c.asnumpy()) [[ 6. 6. 6.] [ 6. 6. 6.]] >>> >>> c = a - b >>> print(c.asnumpy()) [[-4. -4. -4.] [-4. -4. -4.]]
접근 및 슬라이스
요소 접근은 [] 구문은 사용한다.
1 2 3 4 5 6 7 8 9 10>>> # indexing >>> a = mx.nd.array(np.arange(6).reshape(3, 2)) >>> print(a.shape) (3L, 2L) >>> print(a.asnumpy()) [[ 0. 1.] [ 2. 3.] [ 4. 5.]] >>> print(a[0][1].asnumpy()) [ 1.]
슬라이스 구문은 각 axis별로 수행할 수 있다. 기본 axis는 0이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15>>> # slice >>> print(a[1:2].asnumpy()) [[ 2. 3.]] >>> >>> # slice with particular axis >>> d = mx.nd.slice_axis(a, axis=0, begin=1, end=2) >>> print(d.asnumpy()) [[ 2. 3.]] >>> >>> # using another axis >>> d = mx.nd.slice_axis(a, axis=1, begin=1, end=2) >>> print(d.asnumpy()) [[ 1.] [ 3.] [ 5.]]
shape 변경하기
여타 고속배열과 마찬가지로 원본 메모리의 데이터는 그대로 둔 채 형태만 변경할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28>>> # reshape >>> a = mx.nd.array(np.arange(24)) >>> print(a.shape) (24L,) >>> print(a.asnumpy()) [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23.] >>> b = a.reshape((2, 3, 4)) >>> print(b.shape) (2L, 3L, 4L) >>> print(b.asnumpy()) [[[ 0. 1. 2. 3.] [ 4. 5. 6. 7.] [ 8. 9. 10. 11.]] [[ 12. 13. 14. 15.] [ 16. 17. 18. 19.] [ 20. 21. 22. 23.]]] >>> b[0][0][2] = -9 # changing value at 0 channel, 0 row, 2 col >>> print(b.asnumpy()) [[[ 0. 1. -9. 3.] [ 4. 5. 6. 7.] [ 8. 9. 10. 11.]] [[ 12. 13. 14. 15.] [ 16. 17. 18. 19.] [ 20. 21. 22. 23.]]] >>> print(a.asnumpy()) [ 0. 1. -9. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23.]
배열 연결하기(concatenate)
두 배열은 연결할 수 있으며, 마찬가지로 axis별로 연결할 수 있다. 기본 axis는 0이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21>>> # concatenate >>> a = mx.nd.ones((2, 3)) >>> b = mx.nd.ones((2, 3)) * 2 >>> print(a.asnumpy()) [[ 1. 1. 1.] [ 1. 1. 1.]] >>> print(b.asnumpy()) [[ 2. 2. 2.] [ 2. 2. 2.]] >>> c = mx.nd.concatenate([a, b]) >>> print(c.asnumpy()) [[ 1. 1. 1.] [ 1. 1. 1.] [ 2. 2. 2.] [ 2. 2. 2.]] >>> >>> # concatenate with a particular axis >>> c = mx.nd.concatenate([a, b], axis=1) >>> print(c.asnumpy()) [[ 1. 1. 1. 2. 2. 2.] [ 1. 1. 1. 2. 2. 2.]]
리듀스(reduce)하기
배열을 스칼라(scalar) 값으로 리듀스할 수 있다. 마찬가지로 axis별로 연결할 수 있다. 기본 axis는 0이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15>>> a = mx.nd.ones((2, 3)) >>> print(a.asnumpy()) [[ 1. 1. 1.] [ 1. 1. 1.]] >>> b = mx.nd.sum(a) >>> print(b.asnumpy()) [ 6.] >>> >>> # reduce along a particular axis ... c = mx.nd.sum_axis(a, axis=0) >>> print(c.asnumpy()) [ 2. 2. 2.] >>> c = mx.nd.sum_axis(a, axis=1) >>> print(c.asnumpy()) [ 3. 3.]
GPU 지원
MXNet은 멀티 CPU/GPU를 지원한다. CPU/GPU간 스위치는 컨텍스트(context)를 기반으로 하며, 여러개인 경우 CPU/GPU 숫자를 입력한다.
1 2 3 4 5 6 7 8 9>>> a = mx.nd.ones((100, 100)) >>> b = mx.nd.ones((100, 100), mx.cpu(0)) >>> c = mx.nd.ones((100, 100), mx.gpu(0)) >>> print(a) <NDArray 100x100 @cpu(0)> >>> print(b) <NDArray 100x100 @cpu(0)> >>> print(c) <NDArray 100x100 @gpu(0)>
또는 아래와 같이 mx.Context() 구문을 이용할 수도 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16>>> # using a context >>> def f(): ... a = mx.nd.ones((100, 100)) ... b = mx.nd.ones((100, 100)) ... c = a + b ... print(c) ... >>> # in default mx.cpu() is used >>> f() <NDArray 100x100 @cpu(0)> >>> >>> # change the default context to the first GPU >>> with mx.Context(mx.gpu()): ... f() ... <NDArray 100x100 @gpu(0)>
Symbolic 모델: mxnet.sym 심볼 사용하기
mxnet.sym을 이용하여 Symbolic 모델을 사용하는 방법에 대해 소개한다. 관련 내용은 Tutorials > Python > Basics > Neural Network Graphs을 참고했으며 예제 코드는 basics/symbol_tutorial.py에 위치한다.
computation graph 기본
mxnet.sym을 이용하여 Symbolic 모델을 구현하는 방법은 다음과 같다. 먼저 심볼을 기반으로 computation graph를 구성한다.
1 2 3 4 5 6 7 8>>> # Configure computation graph >>> import mxnet as mx >>> a = mx.sym.Variable('a') >>> b = a * 2 + 1 >>> print(a) <Symbol a> >>> print(b) <Symbol _plusscalar0>
mx.vis 패키지를 이용하여 그래프를 그려보자.
1 2 3# Plot computation graph vis = mx.viz.plot_network(symbol=b) vis.render('graph')
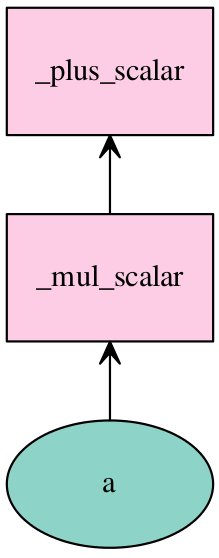
그림. mx.viz 패키지를 이용한 그래프 plotting
그래프는 데이터를 바인딩한 후 실행하여 그 결과를 확인할 수 있다. 텐서플로우의 session.run(..)과 동일한 형태라고 이해할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12>>> # Bind data >>> ex = b.bind(ctx=mx.cpu(), args={'a': mx.nd.ones((2, 3))}) >>> # Execute computation graph >>> ex.forward() [<NDArray 2x3 @cpu(0)>] >>> print(ex.outputs) [<NDArray 2x3 @cpu(0)>] >>> print(len(ex.outputs)) 1 >>> print(ex.outputs[0].asnumpy()) [[ 3. 3. 3.] [ 3. 3. 3.]]
신경망 만들기
사칙연산 이외에 신경망을 구성하기 위한 오퍼레이션을 제공한다. 아래는 2개의 레이어로 구성된 MLP(Multi Layer Perceptron)을 구성하는 예다.
1 2 3 4 5 6 7 8>>> # Basic Neural Networks >>> net = mx.sym.Variable('data') >>> net = mx.sym.FullyConnected(data=net, name='fc1', num_hidden=128) >>> net = mx.sym.Activation(data=net, name='relu1', act_type="relu") >>> net = mx.sym.FullyConnected(data=net, name='fc2', num_hidden=10) >>> net = mx.sym.SoftmaxOutput(data=net, name='out') >>> vis = mx.viz.plot_network(net, shape={'data': (100, 200)}) >>> vis.render('basic')
아래는 그래프를 시각화한 것이다.
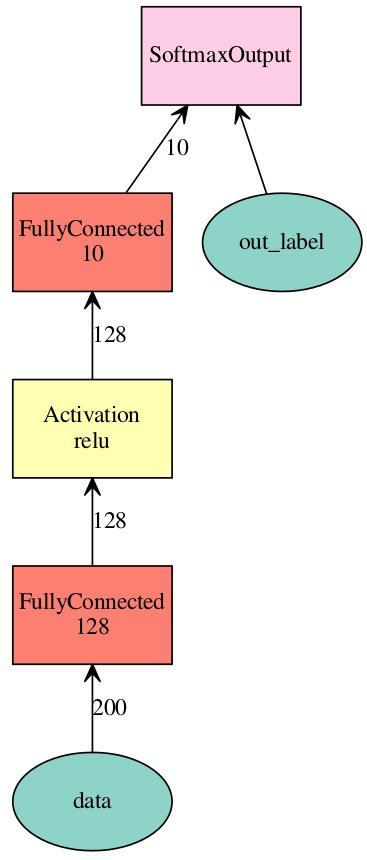
그림. 2레이어 MLP
모듈화하기
CNN과 같이 깊은 신경망은 유사한 레이어가 반복적으로 필요하며, 각 레이어를 하나씩 추가하는 일은 소모적이다. 대신에 아래와 같이 Factory 함수로 모듈화하여 재사용할 수 있다.
1 2 3 4 5 6 7>>> # Modulelized Construction for Deep Networks >>> def ConvFactory(data, num_filter, kernel, stride=(1, 1), pad=(0, 0), name=None, suffix=''): ... conv = mx.symbol.Convolution(data=data, num_filter=num_filter, kernel=kernel, stride=stride, pad=pad, ... name='conv_%s%s' % (name, suffix)) ... bn = mx.symbol.BatchNorm(data=conv, name='bn_%s%s' % (name, suffix)) ... act = mx.symbol.Activation(data=bn, act_type='relu', name='relu_%s%s' % (name, suffix)) ... return act
ConvFactory() 함수를 이용하여 2개의 Convolution 레이어로 구성된 네트워크를 아래와 같이 구성할 수 있다.
1 2 3 4 5 6>>> prev = mx.symbol.Variable(name="Previos Output") >>> conv_comp1 = ConvFactory(data=prev, num_filter=64, kernel=(7, 7), stride=(2, 2), name='Conv1') >>> conv_comp2 = ConvFactory(data=conv_comp1, num_filter=32, kernel=(7, 7), stride=(2, 2), name='Conv2') >>> shape = {"Previos Output": (128, 3, 28, 28)} >>> vis = mx.viz.plot_network(symbol=conv_comp2, shape=shape) >>> vis.render('conv-factory')
시각화된 그래프는 다음과 같다.
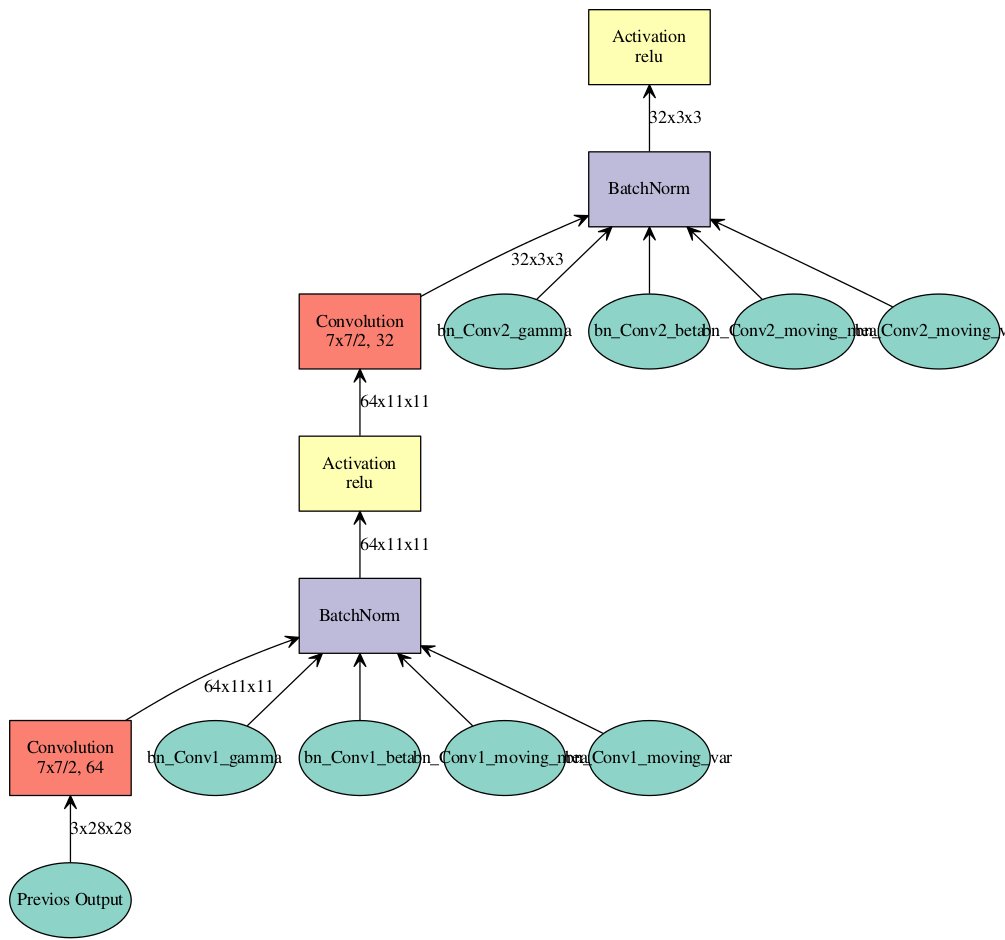
그림. 2 레이어 CNN
computation graph 저장 및 로드하기
구성한 그래프는 JSON 형태로 저장하고, 다른 프로그램에서 로드하여 재사용할 수 있다.
1 2 3 4 5 6 7 8 9>>> # Load and save computation graph >>> a = mx.sym.Variable('a') >>> b = mx.sym.Variable('b') >>> c = a + b >>> >>> c.save('symbol-b.json') >>> c2 = mx.symbol.load('symbol-b.json') >>> print(c.tojson() == c2.tojson()) True
학습된 파라미터 또한 파일로 직렬화할 수 있으며, 관련된 내용은 조금 후에 다른다.
저수준 API를 이용한 훈련하기
앞에서 생성한 그래프를 훈련하는 방법을 소개한다. 관련 내용은 Tutorials > Python > Basics > Training and Inference with Module을 참고했으며 예제 코드는 basics/training_inference_low.py에 위치한다.
MXNet은 텐서플로우와 마찬가지로 저수준 API와 고수준 API를 제공한다. 텐서플로우의 경우 고수준 API는 tf.contfib.learn 패키지로 분리된 반면, MXNet에서는 mx.mod.Module을 저수준으로 사용할수도 있고 고수준으로 이용할 수도 있다. 이는 MXNet의 설계 철학으로 API를 유연하면서도 사용하기 쉽게 만들려는 목표 때문이다.
그래프 구성하기
먼저 학습할 데이터셋을 로드한다.
1 2 3 4 5 6 7 8>>> import mxnet as mx >>> from util.data_iter import SyntheticData >>> import logging >>> # set logging level to INFO >>> logging.basicConfig(level=logging.INFO) >>> >>> # synthetic 10 classes dataset with 128 dimension >>> data = SyntheticData(10, 128)
MXNet에서 데이터셋은 Iterator를 기반으로 구성한다. 자세한 내용은 "데이터 로드하기"에서 다룬다.
그리고 신경망 그래프를 구성한다.
1 2 3 4 5 6 7 8 9>>> # simple multi-layer perceptron for 10 classes >>> net = mx.sym.Variable('data') >>> net = mx.sym.FullyConnected(net, name='fc1', num_hidden=64) >>> net = mx.sym.Activation(net, name='relu1', act_type="relu") >>> net = mx.sym.FullyConnected(net, name='fc2', num_hidden=10) >>> net = mx.sym.SoftmaxOutput(net, name='softmax') >>> >>> vis = mx.viz.plot_network(net) >>> vis.render('mlp')
시각화된 그래프는 아래와 같다.
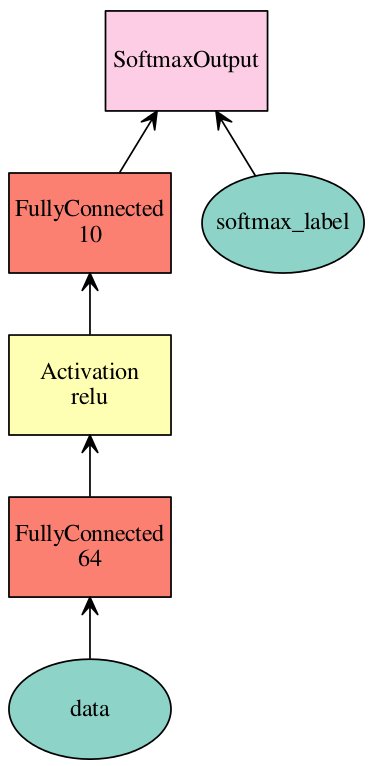
그림. MLP
상태 머신으로써의 Module
모듈은 computational 상태 머신으로 볼 수 있으며 아래의 상태를 차례대로 거친다
- 초기 상태 실볼 기반의 그래프만 존재하며 메모리가 할당되지 않은 상태 계산(computation)이 실행될 수 없는 상태
- 데이터 바인딩 상태 입력, 출력, 파라미터 등에 대해 메모리가 할당된 상태 계산(computation)이 실행될 수 있는 상태
- 파라미터 초기화 상태 훈련 과정의 최적화를 위해 파라미터를 적절한 값으로 초기화환 상태
- 옵티마이저 할당 상태 옵티마이저가 할당된 상태 계산(computation)을 반복적으로 실행하여 파라미터를 업데이트 할 수 있는 상태
위의 네트워크는 아래와 같이 학습된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28>>> # initial state >>> mod = mx.mod.Module(symbol=net) >>> >>> # bind, tell the module the data and label shapes, so ... # that memory could be allocated on the devices for computation >>> batch_size=32 >>> train_iter = data.get_iter(batch_size) >>> mod.bind(data_shapes=train_iter.provide_data, label_shapes=train_iter.provide_label) >>> >>> # init parameters >>> mod.init_params(initializer=mx.init.Xavier(magnitude=2.)) >>> >>> # init optimizer >>> mod.init_optimizer(optimizer='sgd', optimizer_params=(('learning_rate', 0.1),)) >>> >>> # use accuracy as the metric >>> metric = mx.metric.create('acc') >>> >>> # train one epoch, i.e. going over the data iter one pass >>> for batch in train_iter: ... mod.forward(batch, is_train=True) # compute predictions ... mod.update_metric(metric, batch.label) # accumulate prediction accuracy ... mod.backward() # compute gradients ... mod.update() # update parameters using SGD ... >>> # training accuracy >>> print(metric.get()) ('accuracy', 0.4)
훈련 과정은 "forward -> backward -> update(parameter)"를 따른다.
mx.mod.Module을 이용한 훈련하기
앞에서 생성한 그래프를 고수준 API인 fit() 함수를 이용하여 훈련하는 방법을 소개한다. 관련 내용은 Tutorials > Python > Basics > Training and Inference with Module을 참고했으며 예제 코드는 basics/training_inference_module.py에 위치한다.
그래프 구성하기
앞에서 사용한 데이터셋 그래프를 그대로 사용한다. 먼저 학습할 데이터셋을 로드한다.
1 2 3 4 5 6 7 8>>> import mxnet as mx >>> from util.data_iter import SyntheticData >>> import logging >>> # set logging level to INFO >>> logging.basicConfig(level=logging.INFO) >>> >>> # synthetic 10 classes dataset with 128 dimension >>> data = SyntheticData(10, 128)
MXNet에서 데이터셋은 Iterator를 기반으로 구성한다. 자세한 내용은 "데이터 로드하기"에서 다룬다.
그리고 신경망 그래프를 구성한다.
1 2 3 4 5 6 7 8 9>>> # simple multi-layer perceptron for 10 classes >>> net = mx.sym.Variable('data') >>> net = mx.sym.FullyConnected(net, name='fc1', num_hidden=64) >>> net = mx.sym.Activation(net, name='relu1', act_type="relu") >>> net = mx.sym.FullyConnected(net, name='fc2', num_hidden=10) >>> net = mx.sym.SoftmaxOutput(net, name='softmax') >>> >>> vis = mx.viz.plot_network(net) >>> vis.render('mlp')
훈련 모듈 생성하기
그래프를 훈련시킬 모듈을 생성한다.
1 2 3 4 5 6 7 8 9>>> # Create Module ... # symbol : the network Symbol ... # context : the device (or a list of devices) for execution ... # data_names : the list of data variable names ... # label_names : the list of label variable names >>> mod = mx.mod.Module(symbol=net, ... context=mx.cpu(), ... data_names=['data'], ... label_names=['softmax_label'])
- symbol: 신경망 그래프
- context: 훈련 모드 (CPU / GPU)
- data_names: 훈련 데이터 X의 key 값
- label_names: 훈련데이터 Y의 key 값(레이블)
data_names와 label_names는 사용하는 데이터 Iterator에 정의하며, data_names는 'data'를 label_names의 경우 'softmax_label'을 기본값으로 사용한다. 아래는 데이터 Iterator에 정의된 각 key 값이다(util/data_iter.py).
1 2 3 4 5 6@property def provide_data(self): return [('data', self.data_shape)] @property def provide_label(self): return [('softmax_label', self.label_shape)]
훈련하기
모듈의 fit() 함수를 이용하여 훈련을 실행한다. 아래 코드에서는 SGD를 옵티마이저로 사용한다. 각 에폭이 끝날 때 마다 테스트 데이터셋(eval_data)를 이용하여 평가 정확도(Validatio-accuracy)를 측정할 수 있는 편의도 제공한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18>>> # Train >>> batch_size=32 >>> mod.fit(data.get_iter(batch_size), ... eval_data=data.get_iter(batch_size), ... optimizer='sgd', ... optimizer_params={'learning_rate':0.1}, ... eval_metric='acc', ... num_epoch=5) INFO:root:Epoch[0] Train-accuracy=0.134375 INFO:root:Epoch[0] Time cost=0.055 INFO:root:Epoch[0] Validation-accuracy=0.137500 INFO:root:Epoch[1] Train-accuracy=0.156250 INFO:root:Epoch[1] Time cost=0.022 INFO:root:Epoch[1] Validation-accuracy=0.118750 ... INFO:root:Epoch[4] Train-accuracy=0.212500 INFO:root:Epoch[4] Time cost=0.019 INFO:root:Epoch[4] Validation-accuracy=0.287500
예측하기
훈련이 끝나면, 새로운 데이터에 대해 출력 레이블을 예측할 수 있으며 predict() 함수를 이용한다.
1 2 3 4 5 6 7>>> # Predcit >>> y = mod.predict(data.get_iter(batch_size)) >>> print(y.shape) (320L, 10L) >>> print(y[0].asnumpy()) [ 0.1154182 0.09531597 0.09487709 0.10238722 0.09996634 0.09539144 0.09973843 0.0991783 0.09789511 0.09983196]
또는 forward() 함수를 사용할 수 있다. predict와의 차이는 Iterator 객체가 아니라 (key, value) 형태의 Batch 객체를 받는다는 점과, 예측값을 리턴하지 않고 module.get_outputs()로 접근할 수 있다는 점이다.
1 2 3 4 5 6 7 8 9 10>>> # Forward >>> data.get_iter(batch_size).reset() >>> >>> mod.forward(data.get_iter(batch_size).next()) >>> z = mod.get_outputs()[0] >>> print(z.shape) (32L, 10L) >>> print(z[0].asnumpy()) [ 0.10492473 0.0956347 0.09484128 0.11074156 0.1005571 0.09451112 0.09992547 0.09713381 0.10363641 0.09809381]
실제로 predict() 함수 내부에서는 각 미니 Batch에 대해 forward() 함수를 호출한 후, 데이터를 합치는 코드로 구현되어 있다.
1 2 3 4 5 6 7 8 9 10 11 12def predict(self, eval_data, num_batch=None, merge_batches=True, reset=True, always_output_list=False): ... output_list = [] for nbatch, eval_batch in enumerate(eval_data): if num_batch is not None and nbatch == num_batch: break self.forward(eval_batch, is_train=False) pad = eval_batch.pad outputs = [out[0:out.shape[0]-pad].copy() for out in self.get_outputs()] output_list.append(outputs) ....
또한 predict는 데이터셋 Iteator 전체에 대해 예측을 수행하므로 리턴되는 예측값의 크기가 메모리보다 클 수 있다. 이 경우 moduel.iter_predict() 함수를 사용한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16>>> # Predcit iteratively >>> for preds, i_batch, batch in mod.iter_predict(data.get_iter(batch_size)): ... pred_label = preds[0].asnumpy().argmax(axis=1) ... label = batch.label[0].asnumpy().astype('int32') ... print('batch %d, accuracy %f' % (i_batch, float(sum(pred_label==label))/len(label))) ... batch 0, accuracy 0.250000 batch 1, accuracy 0.218750 batch 2, accuracy 0.031250 batch 3, accuracy 0.250000 batch 4, accuracy 0.125000 batch 5, accuracy 0.281250 batch 6, accuracy 0.156250 batch 7, accuracy 0.250000 batch 8, accuracy 0.125000 batch 9, accuracy 0.187500
Batch별 메트릭이 아닌 전체 데이터셋에 대한 메트릭만 보려면 module.score() 함수를 이용한다.
1 2>>> print(mod.score(data.get_iter(batch_size), ['mse', 'acc'])) [('mse', 28.373765373229979), ('accuracy', 0.18125)]
사용할 수 있는 메트릭은 metric.py에 정의되어 있으며 다음과 같다.
1 2 3 4 5 6 7 8 9 10metrics = { 'acc': Accuracy, 'accuracy': Accuracy, 'ce': CrossEntropy, 'f1': F1, 'mae': MAE, 'mse': MSE, 'rmse': RMSE, 'top_k_accuracy': TopKAccuracy }
모델 저장 및 로드하기
학습이 진행되는 동안 각 에폭별로 체크포인트를 생성할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20>>> model_prefix = 'mx_mlp' >>> checkpoint = mx.callback.do_checkpoint(model_prefix) >>> >>> mod = mx.mod.Module(symbol=net) >>> mod.fit(data.get_iter(batch_size), num_epoch=5, epoch_end_callback=checkpoint) INFO:root:Epoch[0] Train-accuracy=0.059375 INFO:root:Epoch[0] Time cost=0.041 INFO:root:Saved checkpoint to "mx_mlp-0001.params" INFO:root:Epoch[1] Train-accuracy=0.084375 INFO:root:Epoch[1] Time cost=0.020 INFO:root:Saved checkpoint to "mx_mlp-0002.params" INFO:root:Epoch[2] Train-accuracy=0.106250 INFO:root:Epoch[2] Time cost=0.016 INFO:root:Saved checkpoint to "mx_mlp-0003.params" INFO:root:Epoch[3] Train-accuracy=0.137500 INFO:root:Epoch[3] Time cost=0.019 INFO:root:Saved checkpoint to "mx_mlp-0004.params" INFO:root:Epoch[4] Train-accuracy=0.106250 INFO:root:Epoch[4] Time cost=0.020 INFO:root:Saved checkpoint to "mx_mlp-0005.params"
아래와 같이 에폭별 체크포인트 파일과 모델에 대한 symbol.json 파일이 생성됨을 확인할 수 있다.
1 2 3 4 5 6 7$ ll mx_mlp* -rw-rw-r-- 1 itrocks itrocks 35828 Apr 11 13:42 mx_mlp-0001.params -rw-rw-r-- 1 itrocks itrocks 35828 Apr 11 13:42 mx_mlp-0002.params -rw-rw-r-- 1 itrocks itrocks 35828 Apr 11 13:42 mx_mlp-0003.params -rw-rw-r-- 1 itrocks itrocks 35828 Apr 11 13:42 mx_mlp-0004.params -rw-rw-r-- 1 itrocks itrocks 35828 Apr 11 13:42 mx_mlp-0005.params -rw-rw-r-- 1 itrocks itrocks 1423 Apr 11 13:42 mx_mlp-symbol.json
저장된 체크포인트 파일에 대해 에폭번호를 지정하여 로드할 수 있다. 로드하는 항목은 모델(sym), 파라미터(arg_params), 부가 파라미터(aux_params)로 구성된다.
1 2 3>>> # Load checkpoit at epoch 3rd >>> sym, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, 3) >>> print(sym.tojson() == net.tojson())
당연히 앞에서 정의한 네트워크 모델(net.tojson())과 로드한 모델(sym.tojson())은 동일하며, 로드한 파라미터를 초기값으로 이용하여 3에폭 이후부터 재훈련을 진행할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13>>> # Resume training from a saved checkpoint by assign the loaded parameters to the module >>> mod.set_params(arg_params, aux_params) >>> >>> mod = mx.mod.Module(symbol=sym) >>> mod.fit(data.get_iter(batch_size), ... num_epoch=5, ... arg_params=arg_params, ... aux_params=aux_params, ... begin_epoch=3) INFO:root:Epoch[3] Train-accuracy=0.100000 INFO:root:Epoch[3] Time cost=0.032 INFO:root:Epoch[4] Train-accuracy=0.146875 INFO:root:Epoch[4] Time cost=0.016
훈련된 모델을 예측 서비스에 사용하는 경우에도 위와 동일한 과정을 거친다. 자세한 내용은 "학습된 모델 로드하기"에서 다시 설명한다.
데이터 로드하기
먼저 고속 배열인 ndarray를 사용하는 방법에 대해 소개한다. 관련 내용은 Tutorials > Python > Basics > Data Loading을 참고했으며 예제 코드는 basics/loading_data.py에 위치한다.
심볼과 변수
다시 앞의 MLP 그래프를 살펴보자.
1 2 3 4 5 6 7>>> import mxnet as mx >>> num_classes = 10 >>> net = mx.sym.Variable('data') >>> net = mx.sym.FullyConnected(data=net, name='fc1', num_hidden=64) >>> net = mx.sym.Activation(data=net, name='relu1', act_type="relu") >>> net = mx.sym.FullyConnected(data=net, name='fc2', num_hidden=num_classes) >>> net = mx.sym.SoftmaxOutput(data=net, name='softmax')
훈련에 필요한 데이터는 입력과 출력의 쌍이다. 그리고 그래프 내부의 파라미터는 학습해야할 변수다.
1 2 3 4>>> print(net.list_arguments()) ['data', 'fc1_weight', 'fc1_bias', 'fc2_weight', 'fc2_bias', 'softmax_label'] >>> print(net.list_outputs()) ['softmax_output']
- 'data': 입력값을 가리키는 key
- 'softmax_label': 출력 레이블을 가리키는 key
- 'softmax_output': 모델의 예측값을 가리키는 key
- 'opname_varname': 모델의 파라미터를 가리키는 key
즉 학습 파라미터는 'opname_varname' 형태의 명명 규칙을 따르며, 입력값과 레이블을 가리키는 key값의 기본값은 각각 'data', 'opname_label'이다.
데이터 바인딩하기
훈련을 위한 데이터를 바인딩하는 일은 결국 'data'와 'softmax_label'에 값을 할당하는 일이다. 아래의 pseudo 코드와 같이 직접 데이터를 할당하여 바인딩할 수 있다.
1 2 3 4 5 6 7 8for i in range(num_epochs): data.setCurrentBatch(i) x, y = data.get(batch_size) args['data'][:] = x args['softmax_label'][:] = y ex.forward(is_train=True) ex.backward() ...
데이터 Batch
학습 데이터를 직접 바인딩하지 않고, 배치 사이즈만큼의 데이터셋을 리턴할 수 있는 Iterator 기반으로 구현하면 더 효과적이다. 먼저 배치 사이즈 n에 대한 데이터셋을 나태느는 데이터 배치는 아래와 같이 구현한다.
1 2 3 4 5 6# Data Batch class SimpleBatch(object): def __init__(self, data, label, pad=0): self.data = data self.label = label self.pad = pad
- data 입력 데이터 X list of mx.nd.array로 구성 데이터 shape의 첫 번째 차원은 batch_size가 됨 예) 입력이 3x224x224 이미지이고 배치 사이즈가 100인 경우, data.shape은 (100, 3, 224, 224)여야 함
- label 출력 데이터 Y list of mx.nd.array로 구성 데이터 shape의 첫 번째 차원은 batch_size가 됨 예) 10개의 분류 문제이고 배치 사이즈가 100인 경우, label.shape은 (100, )여야 함
- pad 미니 배치중 배치 사이즈보다 남은 데이터가 적어 단순히 패딩한 데이터의 갯수 일반적으로 0이며 0보다 큰 k값인 경우, 인덱스가 k 이상인 데이터는 하습에 사용되지 않음
데이터 Batch Iterator
데이터 Batch Iterator 구현을 위한 규칙은 다음과 같다.
- next() 호출시 다음 Batch를 리턴한다. 다음 Batch가 없는 경우 StopIteraton 예외를 던진다
- reset() 처음 Batch로 초기화한다
- provide_data 속성 (입력 데이터 key, 입력 데이터 shape)을 리턴한다
- provide_label 속성 (출력 데이터 key, 출력 데이터 shape)을 리턴한다
위의 규칙을 따라 데이터 Batch Iterator를 간단히 구현한 코드는 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37>>> import numpy as np >>> class SimpleIter: ... def __init__(self, data_names, data_shapes, data_gen, ... label_names, label_shapes, label_gen, num_batches=10): ... self._provide_data = zip(data_names, data_shapes) ... self._provide_label = zip(label_names, label_shapes) ... self.num_batches = num_batches ... self.data_gen = data_gen ... self.label_gen = label_gen ... self.cur_batch = 0 ... def __iter__(self): ... return self ... def reset(self): ... self.cur_batch = 0 ... def __next__(self): ... return self.next() ... @property ... def provide_data(self): ... return self._provide_data ... @property ... def provide_label(self): ... return self._provide_label ... def next(self): ... if self.cur_batch < self.num_batches: ... self.cur_batch += 1 ... data = [mx.nd.array(g(d[1])) for d,g in zip(self._provide_data, self.data_gen)] ... assert len(data) > 0, "Empty batch data." ... label = [mx.nd.array(g(d[1])) for d,g in zip(self._provide_label, self.label_gen)] ... assert len(label) > 0, "Empty batch label." ... return SimpleBatch(data, label) ... else: ... raise StopIteration >>> n = 32 >>> data = SimpleIter(['data'], [(n, 100)], ... [lambda s: np.random.uniform(-1, 1, s)], ... ['softmax_label'], [(n,)], ... [lambda s: np.random.randint(0, num_classes, s)])
입력 데이터의 key와 출력 데이터 key는 앞서 정의한 네트워크의 arguments에 정의한 변수 명과 동일해야 한다(이 경우 각각 'data', 'softmax_label'에 해당).
데이터 Batch Iterator 사용 예시
데이터 Batch Iterator가 준비되면 아래와 같이 간단히 모듈을 학습시킬 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12>>> mod = mx.mod.Module(symbol=net) >>> mod.fit(data, num_epoch=5) INFO:root:Epoch[0] Train-accuracy=0.109375 INFO:root:Epoch[0] Time cost=0.015 INFO:root:Epoch[1] Train-accuracy=0.096875 INFO:root:Epoch[1] Time cost=0.011 INFO:root:Epoch[2] Train-accuracy=0.100000 INFO:root:Epoch[2] Time cost=0.010 INFO:root:Epoch[3] Train-accuracy=0.109375 INFO:root:Epoch[3] Time cost=0.007 INFO:root:Epoch[4] Train-accuracy=0.112500 INFO:root:Epoch[4] Time cost=0.007
이미지 데이터 로드하기
이미지 데이터셋에 대한 Iterator를 생성하여 사용하는 방법을 소개한다.
먼저 고속 배열인 ndarray를 사용하는 방법에 대해 소개한다. 관련 내용은 Tutorials > Python > Basics > Image IO을 참고했으며 예제 코드는 basics/image_data_io.py에 위치한다.
MXNet에서 이미지 로드하는 방법
MXNet에서 이미지를 로드하는 방법엔 아래 3가지다.
- mx.io.DataIter를 상쇽하여 커스텀 Iterator를 구현
- mx.io.ImageRecordIter 사용 예전 방법으로 유연성이 낮음 Record IO 포맷으로 저장된 rec 파일로부터 데이터를 로드
- mx.img.ImageIter 사용 최신 방법으로 유연하며 확장이 쉬움 rec 파일 뿐만 아니라 raw 이미지 파일을 로드 가능
이 장에서는 mx.io.ImageRecordIter를 사용하는 방법을 소개한다.
Record IO 포맷
mx.io.ImageRecordIter는 Record IO 포맷의 rec 파일을 이용하여 이미지 데이터셋을 로드한다. 먼저 훈련한 데이터셋을 다운로드 한다. 데이터셋은 101개의 레이블로 구성된 이미지 파일들이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20>>> # Download datasets >>> import os >>> import mxnet as mx >>> import numpy as np >>> import matplotlib.pyplot as plt >>> >>> os.system('wget http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz -P data/') --2017-04-11 15:31:11-- http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz Resolving www.vision.caltech.edu (www.vision.caltech.edu)... 35.166.79.253, 52.40.211.70 Connecting to www.vision.caltech.edu (www.vision.caltech.edu)|35.166.79.253|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 131740031 (126M) [application/x-tar] Saving to: ‘data/101_ObjectCategories.tar.gz’ 100%[===================================================================================================================================================================>] 131,740,031 2.87MB/s in 31s 2017-04-11 15:31:43 (4.03 MB/s) - ‘data/101_ObjectCategories.tar.gz’ saved [131740031/131740031] 0 >>> os.chdir('data') >>> os.system('tar -xf 101_ObjectCategories.tar.gz') 0 >>> os.chdir('../')
이미지 파일은 레이블을 하위 디렉토리명으로 구성되어 저장되어 있다.
1 2 3 4 5 6 7 8 9 10$ tree -L 1 101_ObjectCategories 101_ObjectCategories ├── accordion ├── airplanes ├── anchor ├── ant ├── BACKGROUND_Google ├── barrel ... 102 directories, 0 files
이미지 파일을 rec 파일로 변환하기 위해서는 MXNET tool 함수 중 im2rec.py를 사용한다. mxnet 소스코드를 클론한다(--recursive추가하여 하위 프로젝트도 클론).
1$ git clone --recursive https://github.com/dmlc/mxnet.git
클론한 mxnet 디렉토리를 MXNET_HOME 변수로 할당한 후, 이미지에 대한 인덱스 파일을 생성한다.
1 2>>> MXNET_HOME="/home/itrocks/Git/MXNet/mxnet" # change this to your mxnet location >>> os.system('python %s/tools/im2rec.py --list=1 --recursive=1 --shuffle=1 --train-ratio=0.8 --test-ratio=0.2 data/caltech data/101_ObjectCategories'%MXNET_HOME)
- list=1 각 이미지는 1개의 레이블을 가진다
- shuffle=1 셔플링을 한다
- train-ratio=0.8 전체 데이터 중 80%를 훈련 데이터셋으로 만든다
- test-ratio=0.2 전체 데이터 중 20%를 테스트 데이터셋으로 만든다
- data/caltech 데이터 디렉토리에 인덱스 파일을 생성하며, 파일명에 대한 prefix로 caltech을 추가
위의 명령이 실행되면 아래와 같이 caltech_test.lst, clatech_train.lst 인덱스 파일이 생성된다.
1 2 3 4 5 6 7 8$ ll total 129024 drwxrwxr-x 3 itrocks itrocks 4096 Apr 11 15:39 ./ drwxrwxr-x 10 itrocks itrocks 4096 Apr 11 15:31 ../ drwxr-xr-x 104 itrocks itrocks 4096 Nov 9 2004 101_ObjectCategories/ -rw-rw-r-- 1 itrocks itrocks 131740031 Dec 13 03:03 101_ObjectCategories.tar.gz -rw-rw-r-- 1 itrocks itrocks 70994 Apr 11 15:39 caltech_test.lst -rw-rw-r-- 1 itrocks itrocks 285281 Apr 11 15:39 caltech_train.lst
인덱스 파일은 [이미지 번호 \t 레이블번호 \t 이미지 경로] 형태를 가진다.
1 2 3 4 5 6$ head -5 caltech_train.lst 8734 95.000000 watch/image_0115.jpg 420 0.000000 BACKGROUND_Google/image_0421.jpg 2712 6.000000 airplanes/image_0323.jpg 7922 83.000000 sea_horse/image_0043.jpg 4435 25.000000 cougar_body/image_0046.jpg
이미지와 인덱스 파일을 이용하여 rec파일을 생성한다.
1 2 3 4 5 6 7 8 9 10 11>>> os.system("python %s/tools/im2rec.py --num-thread=4 --pass-through=1 data/caltech data/101_ObjectCategories"%MXNET_HOME) Creating .rec file from /home/itrocks/Git/MXNet/mxnet-started/data/caltech_train.lst in /home/itrocks/Git/MXNet/mxnet-started/data time: 0.00131702423096 count: 0 time: 0.0444710254669 count: 1000 time: 0.0346348285675 count: 2000 time: 0.0452909469604 count: 3000 time: 0.0350391864777 count: 4000 time: 0.0344908237457 count: 5000 time: 0.0329620838165 count: 6000 time: 0.0182249546051 count: 7000 Creating .rec file from /home/itrocks/Git/MXNet/mxnet-started/data/caltech_test.lst in /home/itrocks/Git/MXNet/mxnet-started/data
ImageRecordIter
생성된 rec 파일을 이용하여 ImageRecordIter 객체를 생성한다.
1 2 3 4 5 6 7 8 9 10>>> train_data_iter = mx.io.ImageRecordIter( ... path_imgrec="./data/caltech_train.rec", # the target record file ... data_shape=(3, 227, 227), # output data shape. An 227x227 region will be cropped from the original image. ... batch_size=4, # number of samples per batch ... resize=256 # resize the shorter edge to 256 before cropping ... # ... you can add more augumentation options here. use help(mx.io.ImageRecordIter) to see all possible choices ... ) [15:48:54] src/io/iter_image_recordio.cc:221: ImageRecordIOParser: ./data/caltech_train.rec, use 3 threads for decoding.. >>> train_data_iter.reset() >>> batch = train_data_iter.next()
다른 Iterator와 마찬가지로 reset(), next() 명령어를 통해 데이터 Batch에 접근할 수 있다.
MXNet 분류 예제
이 장에서는 MXNet을 이용하여 MNIST 필기체 분류 문제를 MLP와 CNN으로 각각 학습해 본다.
MNIST MLP
MNIST 분류 문제를 MLP를 이용하여 학습한다. 관련 내용은 Tutorials > Python > Computer Vision > Handwritten Digit Classification을 참고했으며 예제 코드는 vision/mnist_classify.py에 위치한다.
데이터셋 다운로드하기
데이터셋을 다운로드한 후 로드한다. 관련 유틸 함수는 util/mnist_data.py에 위치한다.
1 2 3 4 5 6 7 8 9 10 11>>> import mxnet as mx >>> import numpy as np >>> import matplotlib.pyplot as plt >>> from vision import mnist_data as mnist_data >>> >>> # Download data >>> path='http://yann.lecun.com/exdb/mnist/' >>> (train_lbl, train_img) = mnist_data.read_data( ... path+'train-labels-idx1-ubyte.gz', path+'train-images-idx3-ubyte.gz') >>> (val_lbl, val_img) = mnist_data.read_data( ... path+'t10k-labels-idx1-ubyte.gz', path+'t10k-images-idx3-ubyte.gz')
각 이미지는 1x28x28 사이즈를 가지며, 60,000개의 훈련 데이터셋과 10,000개의 테스트 데이터셋으로 구성된다.
1 2 3 4 5 6 7 8 9 10>>> train_lbl array([5, 0, 4, ..., 5, 6, 8], dtype=int8) >>> train_img.shape (60000, 28, 28) >>> train_lbl.shape (60000,) >>> val_img.shape (10000, 28, 28) >>> val_lbl.shape (10000,)
이미지는 아래와 같은 형태를 가진다.
1 2 3 4 5 6 7>>> # Plot the first 10 images and print their labels ... for i in range(10): ... plt.subplot(1,10,i+1) ... plt.imshow(train_img[i], cmap='Greys_r') ... plt.axis('off') ... >>> plt.show()
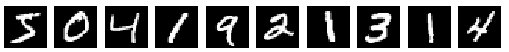
그림. MNIST 이미지 10개
각 이미지에 대응하는 레이블은 다음과 같다.
1 2>>> print('label: %s' % (train_lbl[0:10],)) label: [5 0 4 1 9 2 1 3 1 4]
데이터 Batch Iterator 생성하기
mx.io.NDArrayIter 클래스를 이용하여 훈련 Iterator와 테스트 Iterator를 각각 생성한다. 각 이미지를 1x28x28 shape을 가지도록 변환하고 각 픽셀의 값을 0~1사이의 값이 되도록 255로 나눈다
1 2 3 4 5 6 7 8>>> # Create data iterators >>> def to4d(img): ... return img.reshape(img.shape[0], 1, 28, 28).astype(np.float32) / 255 ... >>> >>> batch_size = 100 >>> train_iter = mx.io.NDArrayIter(to4d(train_img), train_lbl, batch_size, shuffle=True) >>> val_iter = mx.io.NDArrayIter(to4d(val_img), val_lbl, batch_size)
MNIST MLP 그래프 정의하기
MLP 그래프를 구성한다. 이전 예제에서 본 MLP와 동일한 구조이며, 차이는 3차원(channel, width, height)로 구성된 입력 이미지를 1차원(channel * width *height)으로 shape을 변경한다는 점이다.
1 2 3 4 5 6 7 8 9 10>>> # Create a place holder variable for the input data >>> data = mx.sym.Variable('data') >>> # Flatten the data from 4-D shape (batch_size, num_channel, width, height) into 2-D (batch_size, num_channel*width*height) >>> data = mx.sym.Flatten(data=data) >>> fc1 = mx.sym.FullyConnected(data=data, name='fc1', num_hidden=128) >>> act1 = mx.sym.Activation(data=fc1, name='relu1', act_type="relu") >>> fc2 = mx.sym.FullyConnected(data=act1, name='fc2', num_hidden = 64) >>> act2 = mx.sym.Activation(data=fc2, name='relu2', act_type="relu") >>> fc3 = mx.sym.FullyConnected(data=act2, name='fc3', num_hidden=10) >>> mlp = mx.sym.SoftmaxOutput(data=fc3, name='softmax')
그래프를 그려서 확인해 본다.
1 2 3 4>>> # We visualize the network structure with output size (the batch_size is ignored.) >>> shape = {"data" : (batch_size, 1, 28, 28)} >>> vis = mx.viz.plot_network(symbol=mlp, shape=shape) >>> vis.render('mnist-mlp')
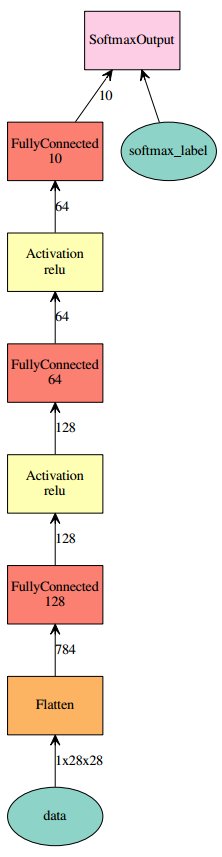
그림. MNIST MLP
훈련 및 평가하기
모듈을 생성한 후 훈련을 실행한다. 데이터셋이 사이즈가 크므로, cpu가 아닌 gpu에서 실행하기 위해 context=mx.gpu()를 설정한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28>>> # Start training >>> import logging >>> logging.getLogger().setLevel(logging.DEBUG) >>> >>> mod = mx.mod.Module(symbol=mlp, ... context=mx.gpu(), ... data_names=['data'], ... label_names=['softmax_label']) >>> >>> # Train, Predict and Evaluate >>> mod.fit(train_iter, ... eval_data=val_iter, ... optimizer='sgd', ... optimizer_params={'learning_rate':0.1}, ... eval_metric='acc', ... num_epoch=10, ... batch_end_callback = mx.callback.Speedometer(batch_size, 200)) # output progress for each 200 data batches INFO:root:Epoch[0] Batch [200] Speed: 114420.43 samples/sec Train-accuracy=0.112985 INFO:root:Epoch[0] Batch [400] Speed: 165656.40 samples/sec Train-accuracy=0.112550 INFO:root:Epoch[0] Train-accuracy=0.259447 INFO:root:Epoch[0] Time cost=0.425 INFO:root:Epoch[0] Validation-accuracy=0.488100 ... INFO:root:Epoch[9] Batch [200] Speed: 139078.35 samples/sec Train-accuracy=0.972736 INFO:root:Epoch[9] Batch [400] Speed: 135514.33 samples/sec Train-accuracy=0.977750 INFO:root:Epoch[9] Train-accuracy=0.979296 INFO:root:Epoch[9] Time cost=0.428 INFO:root:Epoch[9] Validation-accuracy=0.966800
훈련이 완료되면 테스트 데이터셋을 이용하여 테스트 정확도를 확인한다.
1 2 3 4 5>>> # Evaluate the accucracu give an data iterator >>> valid_acc = mod.score(val_iter, ['acc']) >>> print 'Validation accuracy: %f%%' % (valid_acc[0][1] *100,) Validation accuracy: 96.680000% >>> assert valid_acc[0][1] > 0.95, "Low validation accuracy."
MNIST CNN
MNIST 분류 문제를 MLP를 이용하여 학습한다. 관련 내용은 Tutorials > Python > Computer Vision > Image Classification을 참고했으며 예제 코드는 vision/mnist_cnn_classify.py에 위치한다. 동일한 문제를 같은 데이터셋을 이용하여 CNN으로 학습하는 과정은 그래프를 정의하는 방법에서만 차이가 난다. 따라서 데이터셋을 다운로드하고 데이터 Batch Iterator를 생성하는 부분은 앞의 예제와 완전히 동일하다.
MNIST MLP 그래프 정의하기
Convolution 레이어를 이용하여 그래프를 구성한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21>>> data = mx.symbol.Variable('data') >>> # first conv layer >>> conv1 = mx.sym.Convolution(data=data, kernel=(5,5), num_filter=20) >>> tanh1 = mx.sym.Activation(data=conv1, act_type="tanh") >>> pool1 = mx.sym.Pooling(data=tanh1, pool_type="max", kernel=(2,2), stride=(2,2)) >>> # second conv layer >>> conv2 = mx.sym.Convolution(data=pool1, kernel=(5,5), num_filter=50) >>> tanh2 = mx.sym.Activation(data=conv2, act_type="tanh") >>> pool2 = mx.sym.Pooling(data=tanh2, pool_type="max", kernel=(2,2), stride=(2,2)) >>> # first fullc layer >>> flatten = mx.sym.Flatten(data=pool2) >>> fc1 = mx.symbol.FullyConnected(data=flatten, num_hidden=500) >>> tanh3 = mx.sym.Activation(data=fc1, act_type="tanh") >>> # second fullc >>> fc2 = mx.sym.FullyConnected(data=tanh3, num_hidden=10) >>> # softmax loss >>> lenet = mx.sym.SoftmaxOutput(data=fc2, name='softmax') >>> >>> shape = {"data" : (batch_size, 1, 28, 28)} >>> vis = mx.viz.plot_network(symbol=lenet, shape=shape) >>> vis.render('mnist-cnn')
훈련 및 평가하기
훈련 및 평가하는 과정도 MLP 예제와 완전히 동일하다. 이 경우 평가 정확도는 다음과 같다.
1 2 3 4 5>>> # Evaluate the accucracu give an data iterator >>> valid_acc = mod.score(val_iter, ['acc']) >>> print 'Validation accuracy: %f%%' % (valid_acc[0][1] *100,) Validation accuracy: 98.250000% >>> assert valid_acc[0][1] > 0.95, "Low validation accuracy."
resnet-152: 학습된 모델 로드하기
이 장에서는 모바일에 탑재할 모델을 설명한다. 관련 내용은 Tutorials > HowTo > Predict with pre-trained models을 참고했으며 예제 코드는 howto/resnet-152.py에 위치한다.
학습된 모델: resnet-152
예제 모델은 10M개의 ImageNet 전체 데이터셋을 이용하여 10,000개의 레이블을 분류하도록 학습된 모델이다. 먼저 학습된 모델을 다운로드한다.
1 2 3 4 5 6 7 8 9 10 11>>> import os, urllib >>> def download(url): ... filename = url.split("/")[-1] ... if not os.path.exists(filename): ... urllib.urlretrieve(url, filename) ... >>> def get_model(prefix, epoch): ... download(prefix+'-symbol.json') ... download(prefix+'-%04d.params' % (epoch,)) ... >>> get_model('http://data.mxnet.io/models/imagenet/resnet/50-layers/resnet-50', 0)
아래와 같이 그래프 정의인 symbol.json과 학습된 파라미터 파일인 params 파일을 확인할 수 있다.
1 2 3$ ll -h resnet-50-* -rw-rw-r-- 1 itrocks itrocks 98M Apr 11 19:03 resnet-50-0000.params -rw-rw-r-- 1 itrocks itrocks 75K Apr 11 19:03 resnet-50-symbol.json
학습된 모델 로드하기
학습된 모델을 로드한다. 먼저 앞서 다운로드받은 심볼 파일과 파라미터 파일을 mx.model.load_checkpoint() 함수를 이용하여 로드한다.
1 2 3 4 5 6 7>>> import mxnet as mx >>> sym, arg_params, aux_params = mx.model.load_checkpoint('resnet-50', 0) [19:09:44] src/nnvm/legacy_json_util.cc:153: Loading symbol saved by previous version v0.8.0. Attempting to upgrade... >>> >>> vis = mx.viz.plot_network(sym) >>> vis.render('resnet') ...
로드한 그래프와 파라미터를 이용하여 모듈을 초기화한다. 새로운 이미지를 예측할 때는 1개의 이미지만을 사용하므로 shape을 (1, 3, 224, 224)로 설정한다(1 image x 3 channels x 224 width x 224 height).
1 2 3 4 5>>> mod = mx.mod.Module(symbol=sym, context=mx.gpu()) >>> mod.bind(for_training = False, ... data_shapes=[('data', (1,3,224,224))]) [09:48:52] src/operator/./cudnn_convolution-inl.h:55: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable) >>> mod.set_params(arg_params, aux_params)
예측할 데이터 준비
학습된 모델을 이용하여 예측할 새로운 이미지 데이터를 다운로드한다.
1 2 3 4 5>>> # Download and extract validation data >>> import tarfile >>> download('http://data.mxnet.io/data/val_1000.tar') >>> tfile = tarfile.open('val_1000.tar') >>> tfile.extractall()
압축이 풀링 val1000/ 디렉토리에는 총 1000개의 이미지가 들어있다. 그리고 label 파일이 추가로 있는데, 각 이미지의 실제 레이블의 index를 숫자형태로 포함하고 있다.
1 2 3 4 5 6$ head -5 val_1000/label 577 0.jpg 201 1.jpg 412 2.jpg 66 3.jpg 776 4.jpg
이미지별 레이블 정보를 포함하는 리스트를 하나 생성한다.
1 2>>> with open('val_1000/label') as f: ... val_label = [int(l.split('\t')[0]) for l in f]
그리고 레이블을 숫자가 아닌 실제 단어로 매핑하기 위한 synset 파일을 다운로드하고, 리스트 형태로 준비한다.
1 2 3 4>>> # Download synset ... download('http://data.mxnet.io/models/imagenet/resnet/synset.txt') >>> with open('synset.txt') as f: ... synsets = [l.rstrip() for l in f]
synsets의 각 index(key)는 앞의 label의 숫자값이며, value는 텍스트 단어다. 즉 0.jpg(577)과 1.jpg(201)은 각각 "gong, tam-tam", "silky terrier, Sydney sily"다.
1 2 3 4>>> synsets[577] 'n03447721 gong, tam-tam' >>> synsets[201] 'n02097658 silky terrier, Sydney silky'
실제로 0.jpg ~ 7.jpg 이미지를 확인해 본다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15>>> import matplotlib >>> matplotlib.rc("savefig", dpi=100) >>> import matplotlib.pyplot as plt >>> import cv2 >>> for i in range(0,8): ... img = cv2.cvtColor(cv2.imread('val_1000/%d.jpg' % (i,)), cv2.COLOR_BGR2RGB) ... plt.subplot(2,4,i+1) ... plt.imshow(img) ... plt.axis('off') ... label = synsets[val_label[i]] ... label = ' '.join(label.split(',')[0].split(' ')[1:]) ... plt.title(label) ... >>> >>> plt.show()

그림. 예측할 테스트 이미지 몇가지
이미지 변환하기
이미지를 resnet-152에 맞게 변환한다. 즉 이미지를 (1, 3, 224, 224) 형태로 변경해야 한다. 아래 코드를 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21>>> tfile = 'val_1000/0.jpg' >>> timg = cv2.imread(tfile) # read image in b,g,r order >>> type(timg) <type 'numpy.ndarray'> >>> timg.shape (281, 340, 3) >>> timg = cv2.cvtColor(timg, cv2.COLOR_BGR2RGB) # change to r,g,b order >>> timg.shape (281, 340, 3) >>> timg = cv2.resize(timg, (224, 224)) # resize to 224*224 to fit model >>> timg.shape (224, 224, 3) >>> timg = np.swapaxes(timg, 0, 2) >>> timg.shape (3, 224, 224) >>> timg = np.swapaxes(timg, 1, 2) # change to (channel, height, width) >>> timg.shape (3, 224, 224) >>> timg = timg[np.newaxis, :] # extend to (example, channel, heigth, width) >>> timg.shape (1, 3, 224, 224)
위와 같은 역할을 하는 아래와 같이 함수를 정의한다.
1 2 3 4 5 6 7 8 9 10>>> import numpy as np >>> import cv2 >>> def get_image(filename): ... img = cv2.imread(filename) # read image in b,g,r order ... img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # change to r,g,b order ... img = cv2.resize(img, (224, 224)) # resize to 224*224 to fit model ... img = np.swapaxes(img, 0, 2) ... img = np.swapaxes(img, 1, 2) # change to (channel, height, width) ... img = img[np.newaxis, :] # extend to (example, channel, heigth, width) ... return img
예측하기
새로운 이미지에 대해 예측하려면 mx.mod.Module.forward(Batch(..)) 함수를 사용한다. 따라서 이미지에 대핸 numpy 배열을 Batch([mx.nd.array(img)])와 같은 형태로 변환 후 forward(..) 함수로 전달한다.
1 2 3 4 5 6 7 8 9>>> from collections import namedtuple >>> Batch = namedtuple('Batch', ['data']) >>> >>> img = get_image('val_1000/0.jpg') >>> mod.forward(Batch([mx.nd.array(img)])) >>> prob = mod.get_outputs()[0].asnumpy() >>> y = np.argsort(np.squeeze(prob))[::-1] # sort descending >>> print('truth label %d(%s); top-1 predict label %d(%s)' % (val_label[0], synsets[val_label[0]], y[0], synsets[y[0]])) truth label 577(n03447721 gong, tam-tam); top-1 predict label 577(n03447721 gong, tam-tam)
모델 준비하기
모바일 App 데모에서는 앞에서 설명한 resnet-152 모델을 사용한다. 위의 예제에서 설명한 아래의 파일을 준비해 둔다.
- resnet-50-symbol.json 네트워크 모델 그래프
- resnet-50-000.params 학습된 파라미터
- synsets.txt 레이블 정보
MXNet for Mobile
MXNet은 다양한 플랫폼에 쉽게 이식할 수 있도록 설계되었다. 모바일도 그 중 하나로, 모바일 탑재가 용이하도록 전체 MXNet 라이브러리를 1개의 소스 코드로 합치는 amalgamation 생성 스크립트를 지원한다. 이는 텐서플로우와 비슷한데 아래 그림을 보자.

그림, 학습된 모델을 이용한 이미지 분류
(출처: Supercharging Android Apps With TensorFlow)
즉 학습된 모델을 모바일에 탑재하여 새로운 이미지에 대한 분류정보를 제시한다. 내부적으로는 딥러닝 프레임워크를 모바일 기기에 탑재하고, SDK에서는 JNI 호출을 통해서 딥러닝 프레임워크를 호출하는 구조를 갖는다.
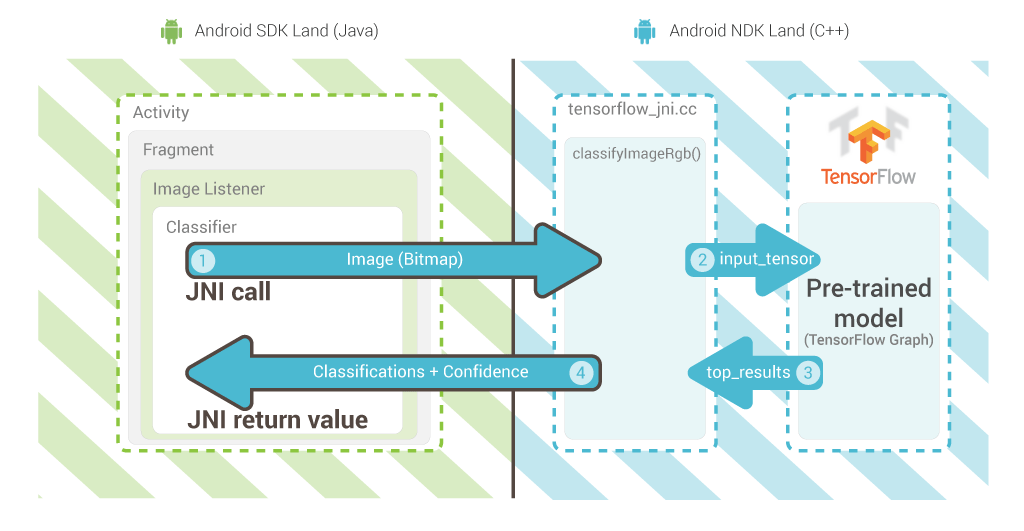
그림, JNI 호출을 통합 딥러닝 프레임워크 API 사용
(출처: Supercharging Android Apps With TensorFlow)
위의 그림에서 TensorFlow 부분만 MXNet으로 변경하면 그 구조는 완전히 동일하다.
MXNet Amalgamation
MXNet amalgamation 프로젝트는 MXNet Amalgamation에 위치한다. 현재 amalgamation 생성 스크립트는 예측 API만을 하나의 소스 파일로 생성한다. 즉 서버에서 모델을 학습하고, 모바일 기기에서는 새로운 데이터에 대해 예측만 하면 되므로 예측 API만 필요하다.
amalgamation 코드 생성하기
먼저 앞에서 클론한 MXNET 프로젝트에서 amalgamation 디렉토리로 이동한다. 그리고 make 명령어를 실행하면 아래 2개의 파일이 생성된다.
- mxnet_predict-all.cc 예측 API를 컴파일하기 위해 사용하는 소스 코드 파일
- ../lib/libmxnet_predict.so 예측을 위한 동적 라이브러리
1 2$ cd mxnet/amalgamation/ $ make
MXNet amalgamation 코드는 BLAS 라이브러리에 의존성이 있으며, 안드로이드에 탑재하기 위해서는 안드로이드 NDK 빌드 환경을 설치한 후 BLAS 라이브러리를 안드로이드 디바이스(ARM, X86, 등)에 맞게 빌드해야 한다. 데모와 빌드를 위해 안드로이드 개발/빌드 환경을 먼저 구축한다.
안드로이드 개발환경 구축하기
안드로드이드 스튜디오 설치하기
안드로이드 스튜디오 설치 가이드는 Install Android Studio에서 확인할 수 있다. 단순히 설치파일을 다운로드 후 압축만 풀면 된다.
데모 프로젝트 살펴보기
데모 프로젝트는 Github > Leliana / WhatsThis를 사용한다. 해당 프로젝트는 앞에서 설명한 resnet-152 모델을 안드로이드에 탑재한 프로젝트다. 먼저 프로젝트를 클론한다.
1$ git clone https://github.com/Leliana/WhatsThis.git
프로젝트는 아래와 같이 구성된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27$ tree app/src/main/ app/src/main/ ├── AndroidManifest.xml ├── java │ ├── com │ │ └── happen │ │ └── it │ │ └── make │ │ └── whatisit │ │ ├── Constants.java │ │ ├── MxNetUtils.java │ │ ├── WhatsActivity.java │ │ └── WhatsApplication.java │ └── org │ └── dmlc │ └── mxnet │ ├── MxnetException.java │ └── Predictor.java ├── jniLibs │ └── armeabi │ └── libmxnet_predict.so └── res ├── raw │ ├── mean.json │ ├── params │ ├── symbol.json │ └── synset.txt
- java/com/happen/it/make/wahtsit 앱 어플리케이션 코드
- java/org/dmlc/mxnet MXNet JNI 라이브러
- jniLibs/armeabi/libmxnet_predict.so MXNet JNI 공유 라이브러
- res/raw/ 학습된 모델 파일
안드로이드 스튜디오 실행하기
안드로이드 스튜디오를 실행한다.
1$ android-studio/bin/studio.sh

그림. 안드로이드 스튜디오 실행 화면
클론한 WhatsThis 프로젝트를 Import(Import project)한다. 프로젝트가 임포트되면 아래와 같은 경고가 나타나면 일단 설치해 둔다(본인은 안드로이드 개발을 잘 모르기에 일단 다 설치했다).
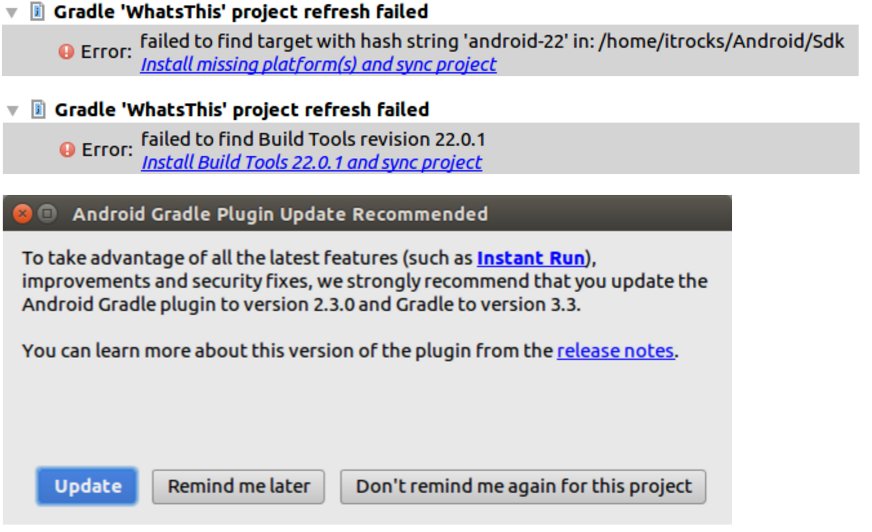
그림. 안드로이드 스튜디오 처음 실행시 나타난 경고들
AVD 생성하기
앱을 에뮬레이션 할 AVD를 생성한다. 대개의 노트북/PC는 x86이므로 AVD도 x86 계열로 생성해야 속도저하가 발생하지 않는다.
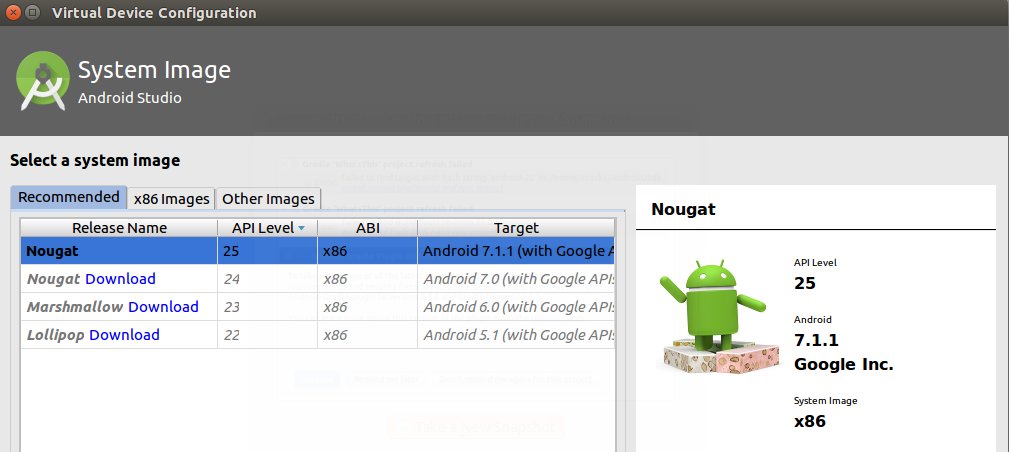
그림. x86 AVD 생성
WhatsThis 프로젝트에서는 armeabi 계열용 so 라이브러리만을 포함하고 있다. 따라서 안드로이드 스튜디오에서 에뮬레이션하기 위해서는 MXNet amalgamation 코드를 x86에 맞게 새롭게 빌드해야 한다. 또한 안드로이드 빌드 환경에 맞게 MXNet을 빌드하기 위해서는 안드로이드 NDK 빌드 툴을 설치해야 한다.
NDK 설치하기
안드로이드 NDK에 대한 설명은 Android NDK에서 확인할 수 있다. NDK는 안드로이드 스튜디오 내에서 설치가 가능하다. 메뉴에서 Tools > Android > SDK Manager를 선택한다. [SDK Tools] 탭을 선택한 후, CMake, LLDB, NDK를 클릭한 후 Apply를 선택하여 설치한다.
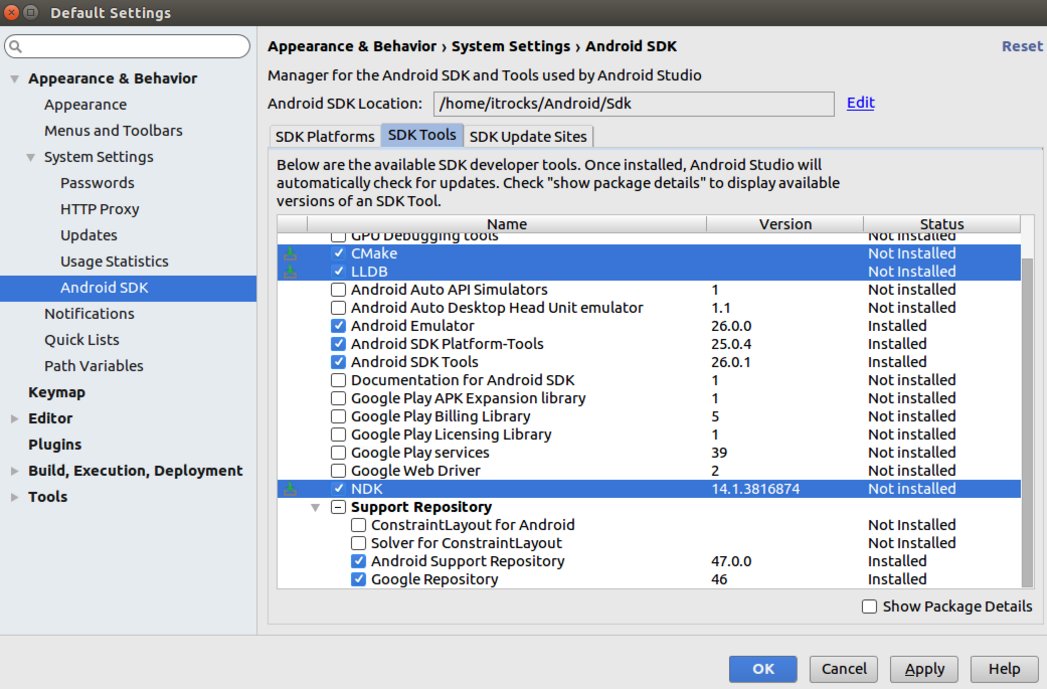
그림. NDK 설치하기
OpenBlas 빌드하기
먼저 MXNet MXNet amalgamation 코드가 의존하는 Blas 라이브러리를 빌드한다. 안드로이드 아키텍처에 맞게 OpenBLAS를 빌드하는 자세한 방법은 How to build OpenBLAS for Android에서 확인할 수 있다.
OpenBLAS 코드 받기
먼저 OpenBLAS 코드를 클론한다.
1$ git clone https://github.com/xianyi/OpenBLAS.git
안드로이드 Toolchain 생성하기
안드로이드는 NDK를 안드로이드 스튜디오 외부에서 사용할 수 있는 Standalone Toolchain을 제공한다. 자세한 내용은 Standalone Toolchains에서 확인할 수 있다. 툴체인을 생성하는 방법은 다음과 같다.
1 2$NDK/build/tools/make_standalone_toolchain.py \ --arch arm --api 21 --install-dir /tmp/my-android-toolchain
- arch 안드로이드 목표 아키텍처
- api 지원할 API 레벨(하위)
- install-dir 툴체인 생성할 위치
툴체인 생성 스크립트는 Android/Sdk/ndk-bundle/build/tools에 위치한다. 이 글의 목표 아키텍처는 x86이므로 아래와 같이 툴체인을 생성한다.
1 2$ cd Android/Sdk/ndk-bundle/build/tools $ python make_standalone_toolchain.py --arch x86 --api 21 --stl libc++ --install-dir /tmp/android-x86-toolchain
- --stl libc++ OpenBLAS를 x86 아키텍처에 맞게 빌드할 때 libc++ 라이브러리를 정적으로 링크하기 위해서 옵션을 추가했다(무한 삽질의 결과로)
OpenBLAS 빌드하기
앞에서 생성한 x86 툴체인을 PATH에 추가한다.
1$ export PATH=/tmp/android-x86-toolchain/bin:$PATH
make 파일을 실행한다.
1$ make TARGET=NEHALEM HOSTCC=gcc CC=i686-linux-android-clang NOFORTRAN=1 libs
- TARGET 안드로이드 목표 아키텍처 TargetList.txt 파일에서 확인할 수 있다
- HOSTCC 로컬 CC
- CC 안드로이드 목표 아키텍처 CC 앞에서 생성한 툴체인에 위치(/tmp/android-x86-toolchain/bin)
설치한다.
1 2 3 4 5 6 7 8 9 10 11 12 13$ make PREFIX=/home/itrocks/Libs/OpenBlas/x86-android install make -j 8 -f Makefile.install install make[1]: Entering directory `/home/itrocks/Downloads/OpenBLAS' Generating openblas_config.h in /home/itrocks/Libs/OpenBlas/x86-android/include Generating f77blas.h in /home/itrocks/Libs/OpenBlas/x86-android/include Generating cblas.h in /home/itrocks/Libs/OpenBlas/x86-android/include Copying LAPACKE header files to /home/itrocks/Libs/OpenBlas/x86-android/include Copying the static library to /home/itrocks/Libs/OpenBlas/x86-android/lib Copying the shared library to /home/itrocks/Libs/OpenBlas/x86-android/lib install: cannot stat ‘libopenblas_nehalemp-r0.2.20.dev.so’: No such file or directory make[1]: *** [install] Error 1 make[1]: Leaving directory `/home/itrocks/Downloads/OpenBLAS' make: *** [install] Error 2
에러가 나는데 so 라이브러리를 copy 하는 부분에서 발생한다. 어제(2017-04-11) Make.install 파일 부분이 변경되었는데, 목표가 ANDROID 플랫폼인 경우에도 so 파일을 copy 하도록 변경되었다. 현재 버그가 있는 상태인데, MXNet을 빌드하는데는 문제가 없다.
MXNet for Android 빌드하기
클론한 mxnet 프로젝트로 이동 후, 빌드 환경을 설정한다.
1 2 3 4$ cd amalgamation $ export PATH=/tmp/android-x86-toolchain/bin:$PATH $ export CC=i686-linux-android-clang $ export CXX=i686-linux-android-clang++
[참고로]
gcc / g++ 대신 clang/clang++을 사용했는데, 이 역시 삽질과 구글링의 결과다. 해당 플랫폼에 이해가 없어 구글링한 내용을 아래에 붙여둔다.
"GCC deprecation: This release ends active support for GCC. GCC is not removed from the NDK just yet, but will no longer receive backports. As some parts of gnustl are still incompatible with Clang, GCC won't be entirely removed until after libc++ has become stable enough to be the default." (https://developer.android.com/ndk/downloads/revision_history.html)
make를 실행하기 전에 Makefie 파일을 수정한다. 먼저 앞에서 빌드한 OpenBLAS 경로를 변경한다.
1 2 3 4 5# Change this to path or specify in make command ifndef OPENBLAS_ROOT #export OPENBLAS_ROOT=/usr/local/opt/openblas export OPENBLAS_ROOT=/home/itrocks/Libs/OpenBlas/x86-android endif
mxnet_predict-all.cc 파일을 열어서 fopen64(..) 호출을 fopen(..)으로 변경한다(2군데).
1 2# fp = fopen64(fname, flag.c_str()); fp = fopen(fname, flag.c_str());
Makefile의 링크 단계에서 libstc++d을 정적으로 사용하도록 -static-libstdc++을 추가한다.
1 2# LDFLAGS+= -Wl,--no-warn-mismatch -lm_hard LDFLAGS+= -Wl -static-libstdc++
이 또한 구글링한 결과이며 아래와 같다.
"Similarly, you can specify --stl=libc++ to copy the LLVM libc++ headers and libraries. Unlike gnustl and stlport, you do not need to explicitly pass -lc++_shared to use the shared library. The shared library will be used by default unless building a static executable. To force the use of the static library, pass -static-libstdc++ when linking. This behavior matches that of a normal host toolchain." (https://developer.android.com/ndk/guides/standalone_toolchain.html)
빌드를 진행한다.
1$ make ANDROID=1
완료되면 jni_libmxnet_predict.so 파일이 생성된다.
이미지 분류 안드로이드 App
이 장에서는 MXNet으로 학습한 res-152 모델을 WhatThis 앱에 탑재한다. 그리고 이를 위해 앞에서 x86 아키텍처에 맞게 빌드한 jni_libmxnet_predict.so 사용하며, 이를 통해 x86 AVD에서 에뮬레이션하는 방법을 설명한다. APK로 설치하려면 WhatThis에 포함된 armeabi/libmxnet_predict.so을 그대로 사용하면 된다.
라이브러리 추가하기
jniLibs/에 x86/ 디렉토리를 생성한 후, 앞에서 빌드한 jni_libmxnet_predict.so 파일을 libmxnet_predict.so라는 이름으로 추가한다.
그림. x86 so 라이브러리 추가
모델 추가하기
프로젝트의 res/raw 디렉토리에 포함된 파일은 모두 삭제한 후, 앞에서 다운로드한 res-152 모델을 res/raw 디렉토리로 아래와 같이 이름을 변경하여 복사한다.
그림. res-152 모델 파일 추가
파일명에 대한 resource 명이 변경되었으므로 해당 모델을 로드하는 WhatsApplication.java 파일을 열어 onCreate(..) 메서드를 아래와 같이 수정한다.
1 2 3 4 5 6 7 8 9 10 11 12@Override public void onCreate() { super.onCreate(); final byte[] symbol = readRawFile(this, R.raw.resnet_new_symbol); final byte[] params = readRawFile(this, R.raw.resnet_new); final Predictor.Device device = new Predictor.Device(Predictor.Device.Type.CPU, 0); final int[] shape = {1, 3, 224, 224}; final String key = "data"; final Predictor.InputNode node = new Predictor.InputNode(key, shape); predictor = new Predictor(symbol, params, device, new Predictor.InputNode[]{node}); dict = readRawTextFile(this, R.raw.synset); }
그리고 mean 파일도 사용하지 않으므로 MXNetUtils.java 파일을 열어서 아래와 같이 변경한다.
1 2 3float mean_b = 0.0f; float mean_g = 0.0f; float mean_r = 0.0f;
실행하기
프로젝트를 앞에서 생성한 x86 AVD를 이용하여 에뮬레이터를 실행한다.
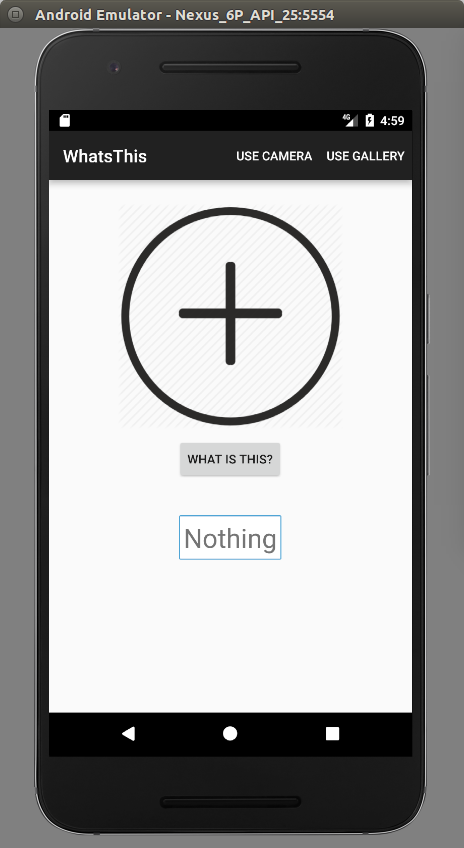
그림. WhatsThis 에뮬레이터 실행 화면
중앙의 "+" 버튼을 클릭하여 사용할 이미지를 선택한다. 카메라로 새로 찍고 싶으면 "USE CAMERA"를 선택한 후 "+"를 선택한다.
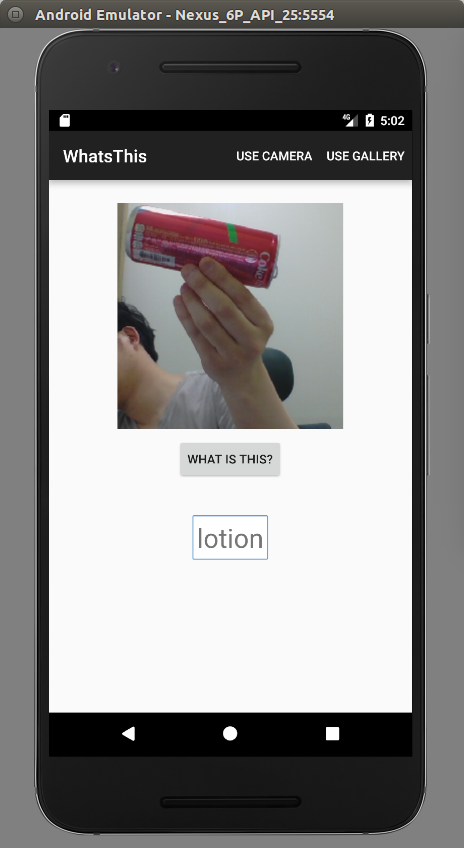
그림. 이미지에 대한 예측 결과 보기
코드에 대한 간단한 설명
JNI 호출을 위한 자바 클래스는 org.dmlc.mxnet.Predictor.java에 위치하며, 예측을 위한 메서드는 forward(..) 메서드다.
1 2 3 4public void forward(String key, float[] input) { if (this.handle == 0) return; nativeForward(this.handle, key, input); }
- key 입력 데이터의 key값이다 앞의 res-152 모델에서는 "data"를 사용했다
- input 예측할 이미지에 대한 배열
새로운 Bitmap 이미지를 flot[] 배열로 변환 후 forward 메서드를 호출하면 예측값을 반환받는다. MXNetUtils.java에 유틸리티 메서드로 정의되어 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25public static String identifyImage(final Bitmap bitmap) { ByteBuffer byteBuffer = ByteBuffer.allocate(bitmap.getByteCount()); bitmap.copyPixelsToBuffer(byteBuffer); byte[] bytes = byteBuffer.array(); float[] colors = new float[bytes.length / 4 * 3]; float mean_b = 0.0f; float mean_g = 0.0f; float mean_r = 0.0f; for (int i = 0; i < bytes.length; i += 4) { int j = i / 4; colors[0 * 224 * 224 + j] = (float)(((int)(bytes[i + 0])) & 0xFF) - mean_r; colors[1 * 224 * 224 + j] = (float)(((int)(bytes[i + 1])) & 0xFF) - mean_g; colors[2 * 224 * 224 + j] = (float)(((int)(bytes[i + 2])) & 0xFF) - mean_b; } Predictor predictor = WhatsApplication.getPredictor(); predictor.forward("data", colors); final float[] result = predictor.getOutput(0); int index = 0; for (int i = 0; i < result.length; ++i) { if (result[index] < result[i]) index = i; } String tag = WhatsApplication.getName(index); String [] arr = tag.split(" ", 2); return arr[1]; }
생각해 볼 것들
모바일 기기에서는 학습된 모델을 기반으로 단순히 예측만 할 뿐이지만, 아직 컴퓨팅 자원이 많이 모자르다. 아래는 Deep Learning in a Single File for Smart Devices에서 Nexus5에서 측정한 성능 결과다.

그림. Nexus5에서 모델별 성능 측정 결과
(출처: Deep Learning in a Single File for Smart Devices)
즉 모델이 복잡해질수록 정확도는 높아지지만 처리 시간은 증가한다. 모바일 서비스의 경우 실시간 서비스여야 하므로 최소한 1초 이내의 응답을 보장할 수 있어야 한다. 위의 경우에는 50% 정도의 정확도가 최선이다. 따라서 모바일에 예측 서비스를 탑재하는 경우 "성능-응답속도" 사이의 trade-off가 적절하도록 모델을 구성하고 학습할 수 있어야 한다.
참고자료
- TensorFlow Mobile
- Torch-7 for Android
- Torch7 Library for iOS
- [빅데이터]아마존이 선택한 딥러닝 플랫폼 MXNet
- MXNet
- MXNet: A Scalable Deep Learning Framework
- Programming Models for Deep Learning
- Tutorials > Python > Basics > CPU/GPU Array Manipulation
- Tutorials > Python > Basics > Neural Network Graphs
- Tutorials > Python > Basics > Training and Inference with Module
- Tutorials > Python > Basics > Data Loading
- Tutorials > Python > Basics > Image IO
- Tutorials > Python > Computer Vision > Handwritten Digit Classification
- Tutorials > Python > Computer Vision > Image Classification
- Tutorials > HowTo > Predict with pre-trained models
- MXNet Amalgamation
- Supercharging Android Apps With TensorFlow
- Install Android Studio
- Android NDK
- Standalone Toolchains
- Github > Leliana / WhatsThis
- How to build OpenBLAS for Android
- Deep Learning in a Single File for Smart Devices