#엑소사랑하자 - OpenFace로 우리 오빠들 얼굴 인식하기

페이스북에 친구들의 사진을 등록하면, 친구 얼굴을 인식하여 이름을 자동으로 태그해준다. 페이스북 얼굴 인식 기술의 정확도는 97.35%정도라고 하는데, 이 정도 수준이면 안면 인식 장애가 있는 나 같은 사람보다도 뛰어나다.
(그림 출처: Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning)
이 글에서는 딥러닝 기반의 얼굴 인식 라이브러리인 OpenFace를 사용하여 엑소 오빠들 사진에서 멤버들의 얼굴을 인식해서 이름을 자동으로 태그하는 방법을 소개한다.
들어가기 전에...
한 달전, CNN(Convolutional Neural Network) 관련 글을 구글링하던 중 미디엄에서 Adam Geitgey가 쓴 "Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks"라는 글을 발견했다. Part3이라는 제목에 이끌려 나머지 토픽들도 훑다가, Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning라는 글이 눈에 띄었다. 딥러닝에 관심을 가지면서 찾아본 논문들은 이론적인 부분에 치중되어 있어 나로써는 구현이 쉽지 않았고, 실질적인 예제들은 MNIST 숫자 필기체를 인식하는 예제를 따라하는 정도의 수준이었다. 하지만 이 글은 얼굴 인식을 위한 관련 도구 설치부터 예측까지의 전체 흐름을 이해하기 쉽게 설명했다. 관심이 있는 분은 Adam Geitgey이 쓴 나머지 딥러닝 씨리즈도 읽어보기를 권한다.
Demo: 엑소 오빠 얼굴 인식기
설명하기에 앞서, 동작하는 모습을 먼저 보여주고자 한다. 데모 사이트에 접속하여, 엑소 사진을 업로드 한다. 사진 업로드가 완료되면, 사진에 포함된 엑소 멤버들 얼굴을 인식하여 그 결과를 우측에 표시한다. 데모 시스템에서는 인식률이 75%(0.75)이상인 경우에만 멤버 인식 결과에 표시하였다.

그림. 엑소 사진을 업로드하면, 인식된 얼굴의 이름과 인식률을 오른쪽에 표시한다.
학습에 사용한 엑소 사진의 개수와 품질에 따라 정확도가 달라질 수 있다. 이 글에서는 각 멤버당 200~300개 정도의 사진을 학습에 사용했으며, 탈퇴한 멤버는 학습에서 제외했다. 학습 및 평가를 위해서는 엑소 얼굴을 익혀둘 필요가 있어 엑소 멤버 소개를 하지 않을 수 없다. 장이씽(Zhang Yixing)님은 레이(Lay)님이며, 도경수(Do Kyung-soo)님은 디오(D.O.)님이다. 이 중 루한(Lu Han), 크리스(Kris Wu), 타오(Tao)는 탈퇴 멤버이며 학습 대상에서 제외했다.
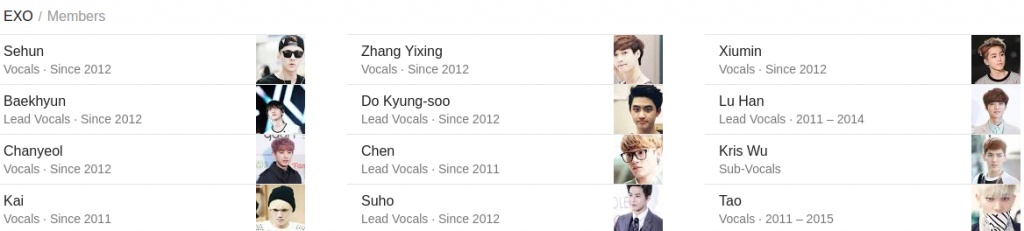
그림. 엑소 멤버 소개 (출처: 구글 검색)
데모 시스템인 ras-ulghul 프로젝트 소스 코드는 github에서 내려받을 수 있다(데모 사이트는 임시적으로만 운영될 예정이다).
얼굴 이름 인식 파이프라인
사진에서 얼굴 이름을 인식을 위한 과정은 아래와 같다.
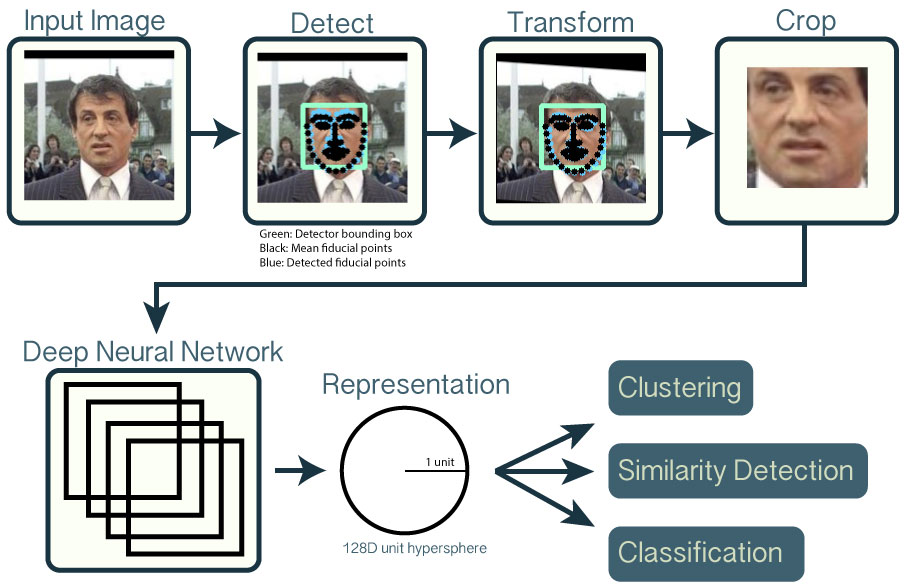
그림. 얼굴 이름 인식 파이프라인(출처: 오픈페이스 소개)
인식(Detect)
입력 이미지에서 얼굴을 찾는 단계다. dlib 또는 OpenCV를 통해 기학습된 모델을 사용하여 얼굴을 인식한다. 이 예제에서는 HOG(Histogram of Oriented) 알고리즘을 사용한 모델을 사용했다.
변환(Transform) & 자르기(Crop)
입력 이미지에서 인식된 얼굴 이미지를 이미지 분류기 학습에 사용할 수 있도록 표준화하는 단계다.

그림. 시우민님의 정면사진과 측면사진.
예를 들어 위의 사진처럼 동일한 사람이더라도 정면과 측면에서 보는 모습은 다르다. 컴퓨터가 동일한 사람으로 분류하도록 학습하기 위해서는 눈/코/입이 사진의 동일한 위치로 오도록 변환해야 한다. 사진에서 눈/코/입 등을 찾는 알고리즘을 얼굴 특징점 추정(face landmark estimation)이라고 부른다. 얼굴 특징점이 인식되면, 특징점이 사진의 동일 위치에 오도록 변환한다. 이 예제에서는 특징점 추정을 위해서 dlib face pose 추정 알고리즘을 사용했고, OpenCV의 아핀 변환 알고리즘을 사용하여 얼굴을 동일 위치로 이동시켰다.
수치화(Representation)
변환된 얼굴 사진을 기학습된 DNN(Deep Neural Network) 모델을 기반으로 수치화하는 단계다. 앞선 과정을 통해 입력 사진에서 얼굴을 찾아서 변환했다면, 이들 사진을 수치화해서 분류 모델을 만든다.
DNN 모델 vs. 분류 모델
기학습된 DNN 모델과, 엑소 사진에서 이름을 식별하기 위한 모델을 구분지어 이해해야 한다.
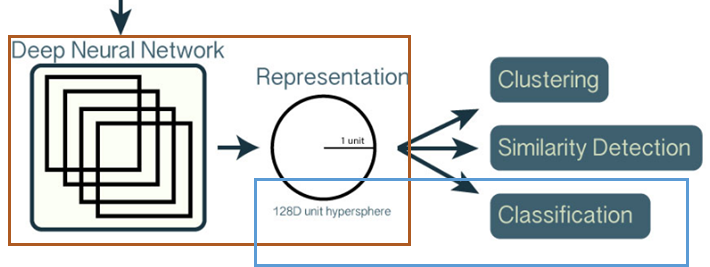
그림. DNN 모델 vs. 분류 모델(출처: 오픈페이스 소개)
DNN 모델
DNN 모델은 입력 이미지를 128차원을 숫자값으로 변환할 수 있는 모델이다. MNIST 필기체 인식 문제의 경우 CNN(Convolutional Neural Network)을 바탕으로 입력 사진을 0에서 9까지의 결과로 분류한다. 반면에 이 경우에는 CNN을 바탕으로 입력 사진을 128 차원을 결과값으로 수치화한다.
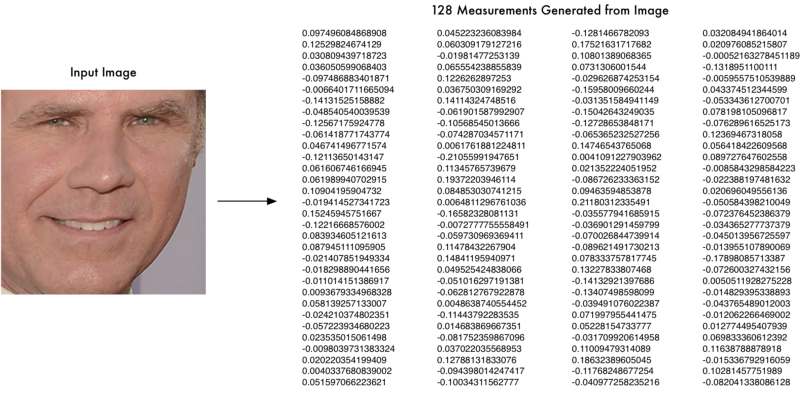
그림. DNN 임베딩(출처: Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning)
이처럼 입력 데이터를 고차원의 벡터로 수치화하는 기법을 임베딩(embedding)이라고 부르며, Word2Vec 알고리즘에서 텍스트 단어를 벡터로 임베딩하는 기법을 사용해봤다면 느낌이 올 것이다. OpenFace에서는 2015년 구글이 발표한 triplet 학습 알고리즘을 적용하여 DNN 모델을 학습했다. DNN 모델 학습이 끝나면, 임의의 입력 이미지를 수치값으로 임베딩할 수 있다.
얼굴 이미지를 128차원의 수치값으로 임베딩하도록 학습시키려면 대량의 데이터와 높은 성능의 컴퓨팅 자원을 필요로 한다. OpenFace의 경우 NVidia Tesla K40 GPU를 기반으로 학습하는데 하루가 걸렸다. 이 예제에서는 OpenFace에서 학습시킨 DNN 모델을 사용하여, 엑소 얼굴 분류 모델을 구현한다. 이미지를 직접 학습하여 DNN 모델을 생성하고자 한다면, OpenFace의 Training new neural network models을 참고한다.
분류 모델
분류 모델은 128차원의 숫자값을 입력으로 사용하여, 엑소 멤버로 분류할 수 있는 모델이다. 일반적인 분류 학습 알고리즘을 사용할 수 있으며, 이 예제에서는 SVM(Support Vector Machine)을 사용하며, 파이썬의 머신러닝 도구인 scikit-learn을 사용한다 .
분류(classification)
엑소 멤버별로 이미지 폴더를 구성하여, 멤버 얼굴 분류기를 학습시킨다. 이때 각 멤버별로 200~300개의 이미지를 사용했으며, 이미지는 OpenFace에서 기학습한 DNN 모델을 사용하여 128차원의 수치값으로 임베딩한 후, SVM의 입력값으로 사용했다.
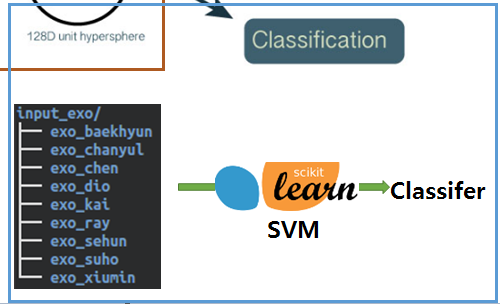
그림. 엑소 멤버 이미지의 임베딩 값을 SVM을 이용하여 분류기를 학습
설치하기
이제 실제로 라이브러리와 관련 도구들을 설치하여 실행해 볼 차례다. OpenFace는 도커(Docker) 이미지를 제공하므로, 도커 이미지를 다운받아 바로 실행해볼 수도 있다. 여기에서는 관련 모듈을 차례대로 설치하려고 한다. 이 예제에서는 아래와 같은 디렉토리 구조로 설치한다.
1 2 3 4 5 6 7 8 9$ pwd /home/ubuntu/OpenFace $ tree . -L 1 . ├── dlib-18.16 ├── opencv-2.4.11 ├── openface └── torch 4 directories, 0 files
의존 라이브러리 설치하기
관련 도구 설치에 필요한 모듈들을 설치한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16$ sudo apt-get update $ sudo apt-get install -y curl $ sudo apt-get install -y git $ sudo apt-get install -y graphicsmagick $ sudo apt-get install -y python-dev $ sudo apt-get install -y python-pip $ sudo apt-get install -y python-numpy $ sudo apt-get install -y python-nose $ sudo apt-get install -y python-scipy $ sudo apt-get install -y python-pandas $ sudo apt-get install -y python-protobuf $ sudo apt-get install -y wget $ sudo apt-get install -y zip $ sudo apt-get install -y unzip $ sudo apt-get install -y cmake $ sudo apt-get install -y libboost-all-dev
opencv 설치하기
얼굴인식 및 변환을 위해 OpenCV를 설치한다.
1 2 3 4 5 6 7 8$ wget https://github.com/Itseez/opencv/archive/2.4.11.zip $ unzip 2.4.11.zip $ cd opencv-2.4.11 $ mkdir release $ cd release $ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local .. $ make $ sudo make install
dlib 설치하기
얼굴인식 및 변환을 위해 dlib을 설치한다.
1 2 3 4 5 6 7 8 9 10$ wget https://github.com/davisking/dlib/releases/download/v18.16/dlib-18.16.tar.bz2 $ bzip2 -d dlib-18.16.tar.bz2 $ tar -xvf dlib-18.16.tar $ cd dlib-18.16/ $ cd python_examples/ $ mkdir build $ cd build $ cmake ../../tools/python $ cmake --build . --config Release $ sudo cp dlib.so /usr/local/lib/python2.7/dist-packages/
torch 설치하기
변환된 얼굴 이미지를 기학습된 DNN 모델을 바탕으로 128차원 값으로 임베딩하기 위해, torch와 관련 모듈을 설치한다.
1 2 3 4 5 6$ git clone https://github.com/torch/distro.git --recursive $ cd torch/ $ ./install-deps $ ./install.sh $ source ~/.bashrc $ for NAME in dpnn nn optim optnet csvigo cutorch cunn fblualib torchx tds; do luarocks install $NAME; done
OpenFace 설치하기
OpenFace를 설치하고, 기학습된 DNN 모델, 관련 모듈을 추가로 설치한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40$ git clone https://github.com/cmusatyalab/openface.git --recursive $ cd openface $ tree models/ models/ ├── dlib │ ├── mean.csv │ └── std.csv ├── get-models.sh └── openface ├── nn2.def.lua ├── nn4.def.lua ├── nn4.small1.def.lua ├── nn4.small2.def.lua ├── resnet1.def.lua ├── vgg-face.def.lua └── vgg-face.small1.def.lua 2 directories, 10 files $ ./models/get-models.sh $ tree models/ models/ ├── dlib │ ├── mean.csv │ ├── shape_predictor_68_face_landmarks.dat │ └── std.csv ├── get-models.sh └── openface ├── celeb-classifier.nn4.small2.v1.pkl ├── nn2.def.lua ├── nn4.def.lua ├── nn4.small1.def.lua ├── nn4.small2.def.lua ├── nn4.small2.v1.t7 ├── resnet1.def.lua ├── vgg-face.def.lua └── vgg-face.small1.def.lua 2 directories, 13 files $ sudo pip2 install -r requirements.txt $ sudo python2 setup.py install $ sudo pip2 install -r demos/web/requirements.txt $ sudo pip2 install -r training/requirements.txt
학습하기
학습하기 위해서는 각 멤버별 이미지 데이터가 필요하다. 관련 이미지는 socurites/ras-ulghul 깃허브 프로젝트의 src/main/resources/input_exo에서 다운로드할 수 있다. SVM으로 분류기를 학습하기에 앞서, 입력 이미지를 수치값으로 임베딩해야 한다. 먼저 입력 이미지에서 얼굴을 인식한 후, 눈과 코가 중앙에 오도록 변환한다.
1 2$ cd /home/ubuntu/OpenFace/openface $ ./util/align-dlib.py /home/ubuntu/artist_faces/input_001 align outerEyesAndNose /home/ubuntu/artist_faces/model/aligned-images_exo/ --size 96
변환이 끝나면 아래와 같이, algined-images-exo/ 디렉토리에 변환된 얼굴 사진이 저장된다.
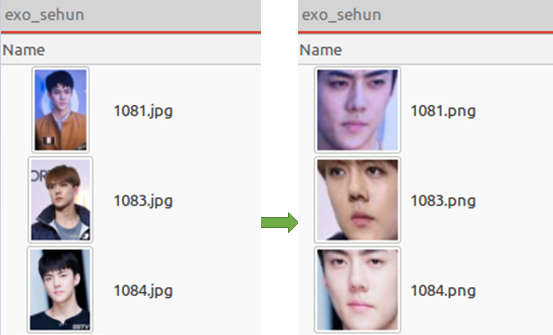
그림. dlib과 OpenCV를 이용해 얼굴을 식별한 후 아핀 변환 적용
변환된 각각의 이미지를OpenFace에서 기학습한 DNN 모델을 사용하여 128차원의 수치값으로 임베딩한다.
1$ ./batch-represent/main.lua -outDir /home/ubuntu/artist_faces/model/generated-embeddings-exo/ -data /home/ubuntu/artist_faces/model/aligned-images_exo/
임베딩이 완료되면 generated-embeddings-exo/ 디렉토리에 labels.csv와 reps.csv 파일이 생성된다.(참고로 aligned-images_exo/ 디렉토리에는 임베딩 때 사용한 캐싱 파일(cache.t7) 파일이 생성된다. 학습을 위한 이미지가 추가되더라도 캐싱 파일을 지우지 않으면 학습이 되지 않으므로, 캐싱 파일을 지워야 한다.)
임베딩된 입력값을 사용하여 분류기를 학습시킨다.
1$ ./demos/classifier.py train /home/ubuntu/artist_faces/model/generated-embeddings-exo/
학습이 끝나면 generated-embeddings-exo/ 디렉토리에 classifiers.pkl이라는 이름의 모델 파일이 생성된다.
예측하기
엑소 이미지에 등장한 멤버 이름을 인식한다. 사진에 여러 멤버가 있는 경우에는 --multi 옵션을 추가한다.
1 2 3 4 5 6 7 8$ ./demos/classifier.py infer /home/ubuntu/artist_faces/model/generated-embeddings-exo/classifier.pkl /home/ubuntu/artist_faces/evaulation/exo/t11.jpg --multi /usr/local/lib/python2.7/dist-packages/sklearn/lda.py:4: DeprecationWarning: lda.LDA has been moved to discriminant_analysis.LinearDiscriminantAnalysis in 0.17 and will be removed in 0.19 "in 0.17 and will be removed in 0.19", DeprecationWarning) === /home/ubuntu/artist_faces/evaulation/exo/t11.jpg === List of faces in image from left to right Predict exo_xiumin @ x=311 with 1.00 confidence. Predict exo_suho @ x=500 with 0.42 confidence. Predict exo_dio @ x=741 with 0.97 confidence.

그림. 시우민님과 디오님을 높은 정확도로 인식. 정확도는 낮지만, 박지우님을 수호님으로 잘못 인식
보는 바와 같이 사진에 등장한 얼굴은 모두 분류하게 된다. 따라서 상용 서비스라면 정확도(confidence)를 기준으로 인식 정확도가 낮은 분류값은 무시해야 한다.
OpenFace 성능
OpenFace는 현재 4종류의 모델을 제공하며, 각 모델은 사용한 파라미터 수와 얼굴 변환에 사용한 속성 등이 서로 다르다. OpenFace에서 각 모델별로 성능 벤치마킹한 자료는 다음과 같다.
| 모델 | alignment
landmarkIndices |
runtime
(CPU/ms) |
runtime
(GPU/ms) |
accucarcy | AUC |
| nn4.v1 |
INNER_EYES _AND_BOTTOM_LIP |
75.67 ± 19.97 |
21.96 ± 6.71 |
0.7612 ± 0.0189 |
0.853 |
| nn4.v2 |
OUTER_EYES _AND_NOSE |
82.74 ± 19.96 |
20.82 ± 6.03 |
0.9157 ± 0.0152 |
0.966 |
| nn4.small.v1 |
OUTER_EYES _AND_NOSE |
69.58 ± 16.17 |
15.90 ± 5.18 |
0.9210 ± 0.0160 |
0.973 |
| nn4.small2.v1
(default) |
OUTER_EYES
_AND_NOSE |
58.9 ± 15.36 | 13.72 ± 4.64 | 0.9292 ± 0.0134 | 0.973 |
| FaceNet Paper
(Reference) |
- | - | - | 0.9963 ± 0.009 | - |
기본 모델인 nn4.small2.v1의 경우 사람과 큰 차이가 없을 정도다.
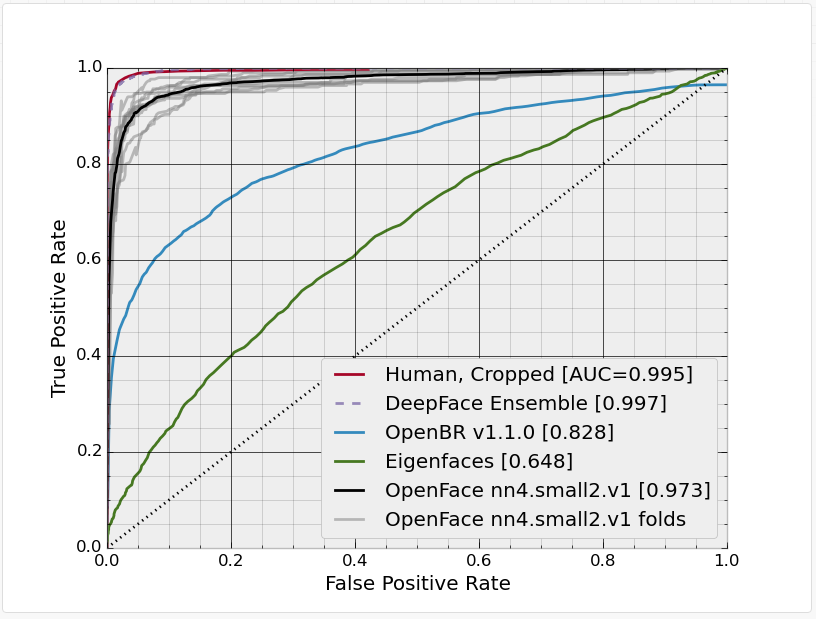
그림. OpenFace의 nn4.small2.v1 모델의 ROC 곡선 (출처: OpenFace, Models and Accuracies)
덧붙여서
앞서 말했듯 이 예제는 OpenFace에서 학습한 DNN 모델을 사용하여 특정 유형의 분류기를 개발하는 예제다. 만약 자신의 도메인에 맞게 DNN 모델을 직접학습해야 한다면 Training new neural network models을 참고한다.
최근 딥러닝 학습을 위한 도구가 많이 공개되고 있지만 거의 모두 파이썬을 기반으로 한다. 자바 개발자라면 Deeplearing4J가 도움이 된다. 딥러닝 관련 블로그를 운영하시는 최근우님이 한글화 작업을 하고 계시며, 한글로 번역된 글도 더러 있다.
딥러닝 관련 도구들은 학습을 위한 API만을 제공하며, 학습된 모델을 상용환경에서 어떻게 배포하고 서비스할지에 대한 고려는 거의 없다. DeepDetect는 모델을 학습하는 API 뿐만 아니라, 학습된 모델을 바로 상용에서 HTTP로 서비스할 수 있는 서버까지 제공한다. DeepDetect와 Elasticsearch를 사용하여 이미지를 자동 태깅하는 예제에 대해서는 본인이 쓴 "딥러닝(Deep Learning) using DeepDetect"가 도움이 될 수도 있다.
참고자료
- Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification
- OpenFace, Free and open source face recognition with deep neural networks
- 데모사이트: EXO OPPA Face Recognizer
- OpenFace, Training a Classifier
- Dlib 18.6 released: Make your own object detector!
- OpenCV, Face Detection using Haar Cascades
- Dlib, Real-Time Face Pose Estimation
- OpenCV, Affine Trasformations
- 다크프로그래머, [영상 Geometry #3] 2D 변환(Transformations), 3.3 Affine Transformation
- Deeplearning4J, Word2Vec
- FaceNet: A Unified Embedding for Face Recognition and Clustering
- OpenFace, Training new neural network models
- scikit-learn, Support Vector Machines
- OpenFace, Setup
- socurites/ras-ulghul github project
- OpenFace, Models and Accuracies
- Deeplearing4J 사이트
- 최근우님 블로그
- DeepDetect 사이트
- 딥러닝(Deep Learning) using DeepDetect