Presto, Zeppelin을 이용한 초간단 BI 시스템 구축 사례(1)

최근 데이터 저장, 처리 관련 다양한 솔루션과 오픈 소스가 나타나면서 다양한 모습으로 데이터 처리 시스템을 구축할 수 있게 되었다. 이번 글에서는 6개월 정도 작업을 통해 현재 운영 중인 서비스에 적용한 Presto, Zeppelin를 이용하여 간단한 BI 체계를 구축했던 경험에 대해 공유하고자 한다. 이 글은 두 개의 글로 구성되어 있으며 첫 번째 글에서는 요청 사항 및 아키텍처/솔루션 선정 과정에 대해 살펴보고, 두 번째 글에서는 실제 시스템을 적용하면서 요청 사항을 맞추기 위해 기존 오픈 소스 솔루션에 추가한 기능에 대해 살펴 볼 것이다. 이 글은 다음 발표 내용에 대한 세부 설명 성격의 글이다.
http://www.slideshare.net/babokim/presto-zeppelin-bi
Presto는 페이스북에서 Interactive Analysis 를 위한 솔루션으로 개발한 SQL 실행 엔진이다. Hadoop(hdfs) 등과 같은 대용량 저장소에 저장된 데이터를 분산 환경에서 SQL을 이용하여 데이터를 처리하는 솔루션이다. 이런 솔루션에서 가장 많이 알려지고 많이 사용하는 솔루션은 Hive 이다. Hive 역시 페이스북에서 만들었으며, 페이스북에서는 대략 2008년부터 Hive 를 이용하여 대용량 BI 체계를 구축하였지만 분석가들이 Query를 실행하고 결과를 보고, 다시 Query를 수정해서 확인하고 하는 형태의 작업에는 적합하지 않았다. Query를 실행하고 결과를 확인하는데 최소 수십 초에서 수분 정도 시간이 소요되다 보니 사고의 흐름이 끊기고, 분석 업무의 생산성이 떨어질 수 밖에 없었다. Hive와 같이 편리한 SQL을 이용하면서 수초 또는 수 십초 이내에 응답을 받기 위한 시스템이 필요 했는데 이런 요청 사항에 부합되도록 만든 것이 Presto 이다.
초기에는 "Approximate Aggregation" 이라는 개념으로 성능을 높이기 위해 정확한 결과는 아니지만 대략의 결과만 정해진 시간 내에 반환하는 솔루션으로 조명을 받았지만 이 기능 때문에 초기에는 오해를 받기도 했다. Presto는 질의의 정확한 결과는 얻을 수 어렵다는 오해였는데, 초기에는 어땠는지 몰라도 지금은 정확한 결과를 반환하는 것이 기본 기능이고 추가로 정해진 시간까지만 실행하고 결과를 반환하거나, 정해진 에러율 내의 정확도로만 데이터를 반환하는 모드 등을 지원하고 있다.
또한, Presto는 Connector 또는 Plugin 라는 개념으로 Hive 뿐만 아니라 Cassandra, Kafka, Mongodb, Mysql, Postgresql, Redis 등의 기본 Plugin을 이용하여 다양한 저장소에 저장된 데이터를 SQL 을 이용하여 조회할 수 있다.
Zeppelin은 한국의 NFLab이라는 회사에서 개발하여 Apache top level 프로젝트로 최근 승인 받은 오픈소스 솔루션으로, Notebook 이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, Query 등을 실행하고 결과를 웹에 나타내는 솔루션이다. Notebook의 개념을 모를 경우 단순 글로는 설명하기 어려운데, 간단한 화면을 보면 다음과 같다.
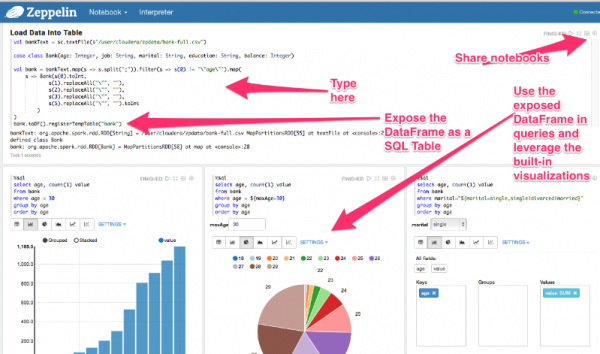
(이미지: https://www.linkedin.com/pulse/notebook-geeks-love-story-craig-lukasik)
위 그림은 언뜻 보면 Dashboard 같지만 실제로는 Dashboard라기 보다는 분석의 처리 흐름이라고 볼 수도 있다.
Zeppelin 역시 분석가의 분석 업무의 흐름을 하나의 Notebook에서 여러 개의 Paragraph 으로 표현하게 함으로써 분석가가 데이터와 로직을 interactive하게 작업할 수 있게 하는 도구이다. 예를 들어 hdfs에서 데이터를 읽어 와서, 특정 필드를 substring 하고, 그 다음에 DB에 저장된 데이터를 조회하여 group by, count를 조회하고, 이 두 조합으로 나온 데이터를 다시 spark 머신 러닝 API를 이용하여 추천을 수행하고 이런 식의 분석 흐름을 그대로 웹 UI에서 따라할 수 있도록 한 것이다.
Zeppelin에서 특정 솔루션의 기능을 실행할 수 있도록 해주는 것을 Interpreter라고 하는데 기본 구성에서 alluxio, angular, cassandra, elasticsearch, flink, hbase, hive, ignite, jdbc, kylin, lens, md, phoenix, psql, sh, spark, tajo 등을 지원한다. md interpreter를 이용하면 특정 Paragraph에 보기 좋은 매뉴얼을 작성할 수도 있고 sh interpreter를 이용하면 기본적으로 제공하지 않는 외부 솔루션으로부터 데이터를 가져와 처리할 수 도 있다.
Presto, Zeppelin이 데이터 분석가에게 Interactive 하게 분석 처리를 지원할 목적으로 하고 있기 때문에 이런 요구사항이 필요한 경우 적합한 조합이라고 할 수 있다. 물론 Zeppelin은 Spark과의 조합으로 많이 사용하고 있지만 이 경우 분석가가 Spark API와 Scala에 대한 지식이 있어야 하며, 그전에 프로그램에 대한 지식이 있어야 하기 때문에 일반 분석가를 위한 용도라기 보다는 Power 분석가를 위한 조합이라고 할 수 있다.
이 글에서는 개발자가 아닌 Data를 필요로 하는 현업 담당자를 위한 간단한 BI 시스템을 Presto와 Zeppelin으로 어떻게 구성 했는지에 대해 설명한다.
사용자는 어떤 기능, 어떤 시스템을 원하는가?
데이터 분석 시스템을 구성하기 위해서는 워낙 많은 솔루션이 존재하기 때문에 시스템의 구성 자체도 요청 사항에 따라 완전히 다른 시스템 구성이 필요합니다. 따라서 정확한 요청 사항을 확인하고 그 요청 사항에 부합되는 아키텍처, 솔루션을 선정하는 것이 가장 중요한 단계 중의 하나라고 할 수 있다.
(주: 일반적으로는 요구사항이라는 용어를 많이 사용하는데, 필자에게는 왠지 나에게 강제한다는 느낌이 있어서 조금 더 존중의 의미가 담겨 있는 듯한 요청 사항이라는 용어로 바꾸어 보았다.)
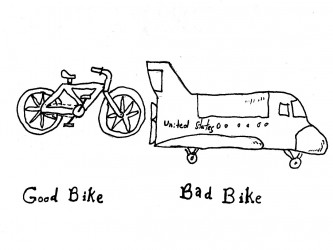
(이미지: http://www.brainlazy.com/article/random-nonsense/over-engineered/)
너무 많은 솔루션과 이들 솔루션이 제공하는 많은 기능을 사용하다 보면 자칫 요청 사항 대비 너무 복잡하고 불필요한 시스템을 만들고 있는 경우가 많다. 위 그림에서 보는 것처럼 사용자는 좋은 자전거를 원했는데 개발팀은 비행기를 만들고 있을 수도 있습니다. 비행기가 빠르고, 더 멀리 갈 수도 있지만 요금도 비싸고, 좁은 골목길에서는 다닐 수 없는 등 실제 사용자가 원했던 기능을 제공하지 못할 수도 있다.
사용자는 주로 다음과 같은 사항이 시스템을 통해서 해결 또는 처리 되었으면 좋겠다고 하였다.
- 데이터를 필요로 하는 사람이 직접 데이터를 볼 수 있으면 좋겠어요.
- 개발자들 너무 바빠서 부탁하기에 눈치 보여요.
- 여러 데이터를 조합해서 볼 수 있으면 좋겠어요.
- 전체 데이터를 볼 수 있으면 좋겠어요.
- 쉽고 빨랐으면 좋겠어요.
- 무엇보다도 Data 보안이 가장 중요해요.
다음과 같은 사항은 중요하지 않거나 당분간은 필요 없을 것 같다.
- 멋진 챠트나 그래프는 있으면 좋지만 아직 필요 없어요.
- 엑셀이면 충분해요.
- 실시간으로 분석할 필요는 없지만 점차 필요하겠죠.
위 요청 사항을 정리해보면 머신러닝 등과 같은 개발자 수준의 분석 보다는 현재는 서비스 운영 및 새로운 기능, 기능 변경에 대한 효과 분석 등을 위한 지표(KPI)를 위한 데이터 처리 또는 새로운 기능 기획을 위한 데이터 조회에 대한 요청 사항이 더 강하다고 할 수 있다. 물론 머신러닝 등을 접목하여 서비스에 새로운 기능을 추가하는 것이 서비스가 발전하고 사용자에게 좋은 경험을 제공하겠지만 그것을 하기 위해서는 데이터 검증 또는 현재의 데이터를 모양새를 더 자세하게 보는 것이 우선이라고 생각하였다. 즉, 사용자나 현재의 시스템에서 원하는 것은 Data Analytics 이라기 보다는 Data Exploration 이었다.

Data Exploration 의 가장 단순한 구성은 DB와 같은 저장소와 웹 UI 또는 테스크탑 UI에서 SQL을 이용하여 데이터를 조회하는 구성이라고 할 수 있다. 개발자들이 개발 시에나 현업 담당자가 데이터를 요청할 때 작업하는 구성도 이와 비슷하다.
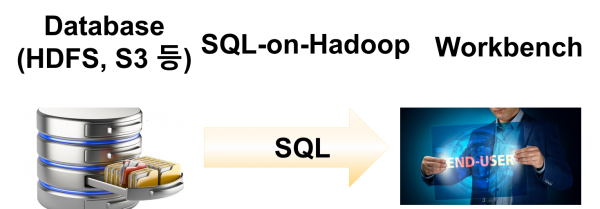
필자가 생각한 기본 아키텍처는 이런 구성을 대용량 데이터 처리하는 플랫폼으로 구성하면 가장 단순하면서도, 사용자의 요청 사항에 부합하는 시스템 구축이 가능할 것이라고 생각하고 이를 기본 아키텍처로 선정하였다.
데이터 저장
대용량 데이터 처리를 위해서는 로그와 같이 분석 대상이 되는 데이터 중 큰 데이터는 Hadoop이나 S3와 같은 분산 대용량 데이터 저장소에 저장되어 있어야 한다. 하지만 현실은 그렇지 않은 경우가 많다. 필자가 운영하는 서비스도 로그 데이터가 ElasticSearch에 저장되고 있었는데 ElasticSearch의 경우 Kibana와 결합할 경우 웹 화면에서 다양한 질의로 데이터를 그래픽하게 조회할 수 있는 장점이 있는 좋은 구성이라고 할 수 있다.

하지만 ElasticSearch에 저장된 로그 데이터는 여러 테이블을 조인하여 조회하기 어렵고, 많은 데이터에 대해서 질의를 실행하면 가끔 OutOfMemory 에러를 발생하거나 응답이 없는 경우도 가끔 발생하였다. 또한, JSON을 이용한 질의 언어 스타일도 사용자 친화적이지 않았다. 물론 SQL도 현업 사용자들이 보기에는 어렵기는 하지만 몇 가지 키워드/개념만 알면 다양하게 응용 가능한 질의 언어라고 할 수 있다.
따라서 간단한 BI를 구축하는 첫 번째 작업은 기존의 로그 저장소를 HDFS나 S3로 저장하게 하는 것부터 시작하였다.
로그 데이터를 S3에 저장하기 위해 Logstash를 선택했는데 이유는 단순하다. 기존 로그 저장 시스템에서 ElasticSearch로 저장하기 위해 이미 Logstash를 사용하고 있어 운영 경험을 보유하고 있기 때문이다. Kafka가 좀 더 일반적이기는 하지만 실시간 수집에 대한 요구사항이 없었기 때문에 한번에 여러 새로운 솔루션을 사용하기 보다는 기존에 사용했던 솔루션을 사용하기로 결정했다. 처음 시작은 Logstash로 시작했지만 지금은 Kafka로 옮겨가고 있는 중이다.
SQL on Hadoop
데이터가 준비 되었으면 데이터를 빠르게 처리할 수 있는 플랫폼이 필요하다. 데이터 처리 플랫폼도 다양한 선택 사항이 있는데 대략 다음과 같은 분류로 나눌 수 있다.
- Map/Reduce
- 전통적인 데이터 분산 처리 플랫폼으로 2004년 구글 논문으로 발표 되었으며 Hadoop MapReduce에 의해 오픈소스로 만들어 졌으며 빅데이터라는 붐을 만들게 된 개념이다.
- 발표될 당시 기존 분산/병렬 처리 프로그램 보다 쉽고 단순한 프로그램 모델, 컴퓨팅 중심이 아닌 데이터 중심의 처리, 일부 서버 장애 시에도 작업을 정상 처리 할 수 있는 기능 등을 이유로 단숨에 데이터 처리의 강자로 떠올랐다.
- 쉽다고는 하지만 잘 돌아가는 프로그램을 만들기 위해서는 내부 동작 매커니즘을 이해해야 하고 개발 후 코드 유지에도 많은 리소스가 필요하고, 점차 시간이 지나면서 새로 나오는 플랫폼 대비 성능에서 뒤쳐지는 어려움을 겪고 있다.
- Spark
- 처음 개발 목표는 머신러닝과 같이 하나의 입력 데이터에 대해 Iterative 한 작업을 메모리 기반으로 빠르게 처리하는 것을 목표로 하였다. 오픈 후 성능, API의 간편함 등으로 원래의 목표를 뛰어 넘어 Map/Reduce 의 많은 부분을 대체하고 있으며 현재 가장 선호하는 분산 컴퓨팅 플랫폼으로 성장하였다.
- SQL on Hadoop
- 용어 자체만 보면 Hadoop에 저장된 데이터를 SQL을 이용해서 처리한다 라는 의미인데, 실제로는 Hadoop 뿐만 아니라 다양한 저장소를 지원한다.
- 또한 이런 솔루션은 성능면에서도 기존의 Map/Reduce 를 이용할때 보다 작게는 2 ~ 3배에서 10배 이상으로 데이터를 처리하도록 디자인되어 있는 경우가 대부분이다.
- 따라서 단순히 SQL로 추상화 시킨 개념에 Interactive Analysis를 지원하는 솔루션이라고 할 수 있다.
이런 컴퓨팅 플랫폼 중에서 현재의 요청 사항인 현업 사용자도 직접 데이터를 Exploration 할 수 있는 도구가 필요했는데 Map/Reduce는 거의 불가능하고, Spark이 어느 정도 대안이 되겠지만 여전히 프로그램 지식이 필요하다. 따라서 현실적인 대안은 SQL이 가장 현실적인 대안이라고 판된되어 SQL-on-Hadoop으로 컴퓨팅 엔진을 선정하였다.
SQL-on-Hadoop은 최근 여러 개의 오픈 소스 솔루션이 경쟁하고 있으며 빅데이터 솔루션 업체들도 주력 상품으로 밀고 있는 솔루션 군 중의 하나이다. 이들 솔루션 업체들도 자사의 제품을 오픈 소스로 공개하고 있기도 하다. 필자가 알고 있는 대표적인 SQL on Hadopp 솔루션은 다음과 같다.
| 솔루션 | 특징 |
| Hive on M/R | SQL을 Hadoop Map/Reduce Job으로 변환하여 실행하기 때문에 MapReduce의 특징을 그대로 가져가고 있다. 안정적이지만 다른 솔루션에 비해 성능이 떨어진다. 최근에는 Hive on Tez 라고 MapReduce가 아닌 Tez를 컴퓨팅 엔진으로 사용하는 방법으로 개선하였다. |
| Presto | 페이스북에서 만들었으며 SQL을 이용하여 Interactive Analysis를 하기 위해 만들었으며, 다양한 저장소를 지원하고 Plugin을 쉽게 확장할 수 있도록 구성되어 있다. 데이터 처리 과정에서 발생하는 중간 데이터는 모두 메모리에서만 처리하도록 되어 있기 때문에 배치 작업 등에서는 어느 정도 제약이 있다. |
| Impala | Cloudera에서 만들었으며 최근 Apache 프로젝트에 합류하였다. 초기 SQL on Hadoop 붐을 일으킨 솔루션이라고 할 수 있다. 초기에는 Presto 와 같이 중간 데이터는 메모리만 사용하였지만 점차 개선되어 디스크를 사용하는 방식으로 바뀌었다. C++ 언어로 개발되어 있어 Connector의 추가 등에서 Presto, Tajo 등에 비해 유연하지 못하다. |
| Tajo | 한국 개발자들이 중심이 되어 개발하였으며, 초기 설계부터 중간 데이터를 In-Memory, On-Disk 모두 사용 가능한 구조로 되어 있어 Interactive 처리, Batch 처리 모두에서 사용 가능하다. |
| Drill | MapR이 개발하여 Apache 프로젝트에 합류한 솔루션으로 2015년까지 성능에 대한 의문점이 많았었다. 필자가 분석한 2015년 상반기까지 성능에 대한 자료 등을 제공하지 않았다. 최근 성능에 대한 자료도 여전히 찾기 어려운 것 같다.
Drill이 가장 강조하는 부분은 Schema free SQL 엔진이라는 것이다. 질의 실행 시 테이블이 아닌 from 절에 파일 명을 지정할 수도 있다. |
이런 솔루션 중 하나를 선정하기 위해서는 다양한 면을 검토 했다. 일반적으로는 성능 부분에 대해 민감하게 테스트를 수행하는데 필자의 경험으로는 Hive on M/R을 제외한 대부분의 솔루션은 어느 정도 성능을 보장해주고 있으며, 특정 질의/저장소/파일포맷 등에 따라 성능이 다르게 나타난다. 성능 테스트를 수행할 경우에는 실제 사용하고자 하는 데이터 포맷과 저장소를 이용하여 성능 테스트하는 것을 권장한다. 필자의 경우 성능 보다는 다음과 같은 기능 외적인 항목으로 1차 필터링을 하였다.
| 항목 | Hive | Presto | Impala | Tajo | Drill |
| 최근 기술인가? | X | O | O | O | O |
| 오픈된 커뮤니티를 운영하고 있는가? | O | O |
△ |
O |
△ |
| 내부 구조까지 잘 아는 지인이 있는가? | O | O | X | O | X |
이후 다음과 같은 기능적 요청 사항으로 다시 분석하였다.
| 기능 | Hive | Presto | Impala | Tajo | Drill |
| JSON 포맷 | O | O | O | O | O |
| 여러 저장소와 Join (hdfs, s3, mysql) | X | O | X | X
(최신 버전에서는 가능) |
O |
| 동시 질의 실행 지원 | X | O | O | O
(0.11 이후 버전 가능) |
O(문서상) |
| Ruby Client | 작업 필요 | O | odbc | 작업 필요 | ? |
| ANSI SQL | X | O | ? | O | ? |
| Hive 보다는 빨라야 함 | O | O | O | O | O |
| Memory limitation
(요구사항은 아님) |
Good | Bad | So so | Good | ? |
결론은 Presto를 선택하였다. 기능적으로 가장 중요했던 요청 사항은 JSON 포맷과 mysql 데이터와 로그 데이터의 직접 join 가능 여부였다. JSON 포맷의 경우에도 서비스 로그 저장이 request의 파라미터 정보를 JSON 형태로 저장하기 때문에 첫 번째 레벨에서는 스키마를 정의할 수 있지만 두 번째 레벨에서는 Map 타입과 같은 Schema-less 기능이 필요 했다. 즉 로그 데이터는 다음과 같이 되어 있다.
1{"path": "/companies/1000?query=test", "request_parameter": {"id": "100", "query": "test"}, …}
request_parameter 컬럼에는 path 마다 다른 parameter 값이 전송되어 특정 컬럼명을 사용하기 어렵다. Presto의 경우 위와 같은 로그 데이터는 다음과 같이 테이블 정의 시 Map type을 이용하고 질의 시에는 동적으로 Map의 키를 지정하여 데이터를 조회할 수 있다.
1 2 3 4-- Map 타입을 이용하여 테이블 생성 create table log (path varchar, request_parameter map<varchar, varchar>); -- SELECT map type select request_parameter['query'] from log group by request_parameter['id']
나머지 다른 기능들은 대부분 비슷하였는데 MySQL 지원, Ruby Client, 동시 질의 지원 등 실제 사용에 필요한 요청 사항 대비 Presto 가 가장 적합하다고 판단되어 SQL on Hadoop 엔진으로 Presto를 선정하였다.
SQL on Hadoop 이라고 하기에는 조금 애매하지만 대용량 데이터를 분산 환경에 SQL을 이용하여 처리하는 솔루션이라는 정의에서 보면 Spark SQL도 이 부류에 들어갈 수 있다. Spark SQL은 처음부터 비교 대상이 아니었는데 이유는 다음과 같다.
- https://www.quora.com/What-are-the-main-use-case-differences-between-Apache-Spark-SQL-and-Apache-Impala-incubating
- Presto, Impala 등은 데이터 분석가나 BI 시스템 등을 위해 설계되어 low-latency 질의나 동시 사용자 질의 처리 등을 원할하게 지원하지 않음
- 반면 Spark SQL은 개발자나 데이터 사이언티스트를 대상으로 설계 되었으며 BI 도구 등에는 잘 맞지 않는 솔루션
SQL Workbench 및 협업 도구로서의 Zeppelin
Zeppelin은 웹 기반 Notebook 을 중심으로 데이터 분석 업무를 수행하게 해주는 오픈소스 솔루션이다. 많은 회사에서는 주로 Spark을 이용하는 분석에 많이 사용한다. 실제 Zeppelin이 처음 나왔을 때에도 이 Spark을 이용할 수 있는 기능 때문에 많은 조명을 받았다.
SQL을 이용하여 실무자가 직접 질의 만들거나 실행하는 GUI 도구는 Zeppelin 이외에도 몇 가지 있다. Tadpole도 있고 Presto 전용인 Airbnb에서 만든 airpal 이라는 솔루션도 있다. SQL workbench의 기능만으로 보면 이들 기능이 Zeppelin의 기능보다는 훨씬 좋다. 심지어 Zeppelin은 기본 Interpreter로 Presto를 지원하지 않는다. 이런 조건에서도 Zeppelin 을 선택한 이유는 SQL을 잘 모르는 실무자와 개발자 사이의 협업 도구로서의 Zeppelin 기능을 높게 보았기 때문이다. Zeppelin의 Notebook은 서버에 저장되고 특정 사용자가 변경하거나 질의를 실행시키면 변경 사항 또는 질의 진행 상황, 질의 결과가 바로 다른 사용자의 브라우저에도 자동 반영되는 기능을 가지고 있다.
처음 이런 시스템을 구축했을 때 고민했던 것은 “과연 실무자가 SQL을 잘 사용할 수 있을까?” 였다. 물론 다 잘 사용할 수는 없겠지만 데이터를 봐야 하고 KPI 를 관리해야 하는 업무를 수행해야 하는 담당자는 최소한 사용할 수 있어야 했다. 그리고 업무와 학습 병행하는 것도 어렵다고 판단하였다. 대안은 실제 업무를 수행하면서 조금씩 학습 곡선을 그려 나가기로 했다. 장기적으로 접근하면서 다음과 같은 프로세스로 현업 담당자의 SQL 사용 능력을 향상 시켰다.
- 특정 팀에서 필요 데이터가 있으면 개발팀에 요청
- 이전에는 결과만 전달하였지만 해당 팀 또는 데이터 요청자의 Notebook 생성
- 해당 Notebook에 개발자가 SQL 작성(일부 변수 값은 Zeppelin의 변수 바인딩 기능 이용하여 동적 입력 가능하도록 설정)
- SQL 까지만 전달하고 실제 실행은 현업 담당자가 실행
- 이후 이와 유사한 데이터 요청의 경우 현업 담당자가 기존 SQL을 복사하여 새로운 Paragraph에 복사한 후 SQL을 조금 수정하여 작업
- 수정 후 문제가 발생할 경우 개발자에게 메시지로 알림
- 문제 발생한 부분은 개발자가 온라인에서 수정
- 현업 담당자는 수정된 부분 확인하면서 SQL 사용 학습
이런 방식에 가장 최적화된 솔루션이 Zeppelin이라고 생각되어 Zeppelin을 선정하여 사용하기로 하였다.
완성된 시스템 구성
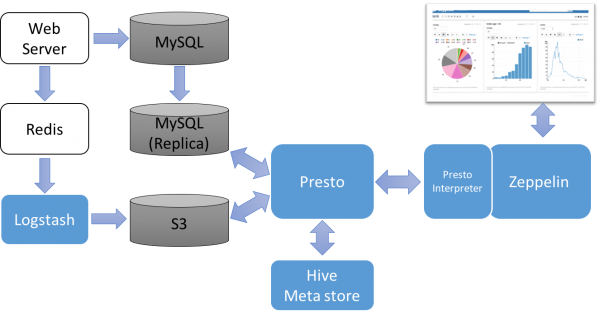
시스템 구축 후 기대 효과는?
시스템 구축 및 데이터 업무 처리 방식을 위와 같이 수 개월 진행한 결과 다음과 같은 효과를 얻었다.
- 데이터 조회 관련 시스템 관리자 기능 개발이 거의 없어짐
- 기존에는 서비스 개발 후 KPI를 보기 위해서는 별도의 작업이 필요했는데 별도 작업이 없어짐
- 회의 중에도 필요한 데이터 바로 확인 가능
- 개발 팀으로 데이터 요청이 줄어들어 개발에 집중할 수 있음
- 다른 팀의 데이터 요청 중 일부는 SQL 사용 가능한 다른 담당자가 대신 처리도 해줌
- 추천 등 조금 더 서비스와 밀접한 분석을 수행할 수 있는 체계가 구성됨
첫번째 글을 마무리하며
지금까지 실무자가 로그 데이터와 운영 데이터를 직접 다루면서 KPI 등의 지표와 서비스 기획, 개선 등이 필요한 데이터를 Exploration 하기 위한 BI 시스템을 구성하기 위한 준비 단계를 소개하였다.
BI 시스템의 일반적인 구성은 데이터를 처리하여 Data Mart를 구성하는 OLAP 도구와 Data Mart를 저장하는 DB, Data Mart에 저장된 데이터를 쉽게 조회하고 Drill down 할 수 있는 기능을 제공하는 UI 도구로 크게 구성된다. 전통적인 엔터프라이즈 시스템의 구성이라면 고가의 상용 솔루션을 이용할 수 있겠지만 스타트업의 특성상 오픈소스 중심으로 빠르게 시스템을 구축해야 하는 요청 사항을 중심으로 시스템 아키텍처 및 솔루션을 선정하였다.
전체 구성은 Spark과 같은 프로그램 언어를 사용하기 보다는 상대적으로 쉽고 표준인 SQL을 선택하였으며, SQL을 대용량 데이터 처리에서도 빠르게 수행할 수 있으며 MySQL 등 다른 저장소의 데이터와도 쉽게 Join이 지원 가능한 SQL-on-Hadoop 솔루션인 Preso 를 선정하였다. 사용자가 SQL을 실행하는 UI 도구로 Zeppelin을 선정하였으며 Zeppelin에서 Spark을 이용하는 것이 아니라 대부분은 Preso Query를 실행하고 Notebook 공유 기능을 이용하여 개발자와 실무자 간의 협업 도구로 활용하였다.
다음 글에서는 Presto, Zeppelin 을 이용하여 시스템을 구축하면서 이 두 솔루션의 기본 기능 이외에 실무 적용하면서 필요해서 자체 개발 또는 수정한 몇 가지 기능에 대해 소개하고자 한다.