Presto, Zeppelin을 이용한 초간단 BI 시스템 구축 사례(2)

이번 글은 "Presto, Zeppelin을 이용한 초간단 BI 시스템 구축 사례(1)" 에 대한 세부 기술적인 내용에 대한 글입니다. 지난 글에서는 사용자들의 요청사항을 기반으로 Presto, Zeppelin을 이용하여 대용량 데이터를 분석할 때 사용자가 직접 SQL을 사용할 수 있는 시스템을 만든 이유와 솔루션 선정에 대해 설명하였습니다. 첫번째 글와 이번 글은 다음 발표자료에 대한 세부 설명이라고 할 수 있습니다.
http://www.slideshare.net/babokim/presto-zeppelin-bi
Presto와 Zeppelin의 기본 기능만으로도 충분히 사용 가능한 시스템을 구축 할 수 있지만, 현업의 기능적/기술적 요청 사항을 만족시키기에는 부족한 부분이 있어 몇가지 수정하여 시스템을 구축하였습니다. 이 글에서는 각 수정 사항에 대해서 세부적으로 살펴보도록 하겠습니다.
Presto는 분산 SQL 실행 엔진이기 때문에 코드의 복잡도가 높아서 주로 Zeppelin 위주로 수정하였습니다. Zeppelin의 추가, 수정한 사항은 대략 다음과 같습니다.
- Presto Interpreter
- Presto Query Kill, Progress 조회 기능
- 시스템 리소스를 많이 사용하는 질의 실행 제한
- Notebook 생성, 수정, 샐행 권한
- Zeppelin 특정 기능(Interpreter 설정, Configuration 설정 등)에 대한 접근 제한
- Presto Query 실행 시 Catalog, Table, Column 단위의 접근 제한
수정한 기능 중 대부분은 개발자가 아닌 일반 사용자가 SQL을 수행하기 때문에 발생할 수 있는 문제를 방지하는 기능과 보안과 관련된 기능이었습니다. 그럼 각 변경 사항에 대해 세부적으로 하나씩 살펴 보도록 하겠습니다.
Presto Interpreter for Zeppelin
Presto는 Java8 이상에서만 실행됩니다. 반면 Zeppelin은 Java7을 기본 Java 버전으로 사용하고 있습니다. 검색해 보면 이미 Presto Interpreter는 만들어져 있지만 Zeppelin의 소스에는 반영되어 있지 않습니다. 이 Interpreter가 아직 Zeppelin의 코드에 반영 되지 않은 이유도 Java의 버전 이슈 때문입니다. Presto Interpreter는 다음 github repostiory에서 확인할 수 있습니다.
https://github.com/danielhaviv/incubator-zeppelin
이 버전의 구현은 Presto JDBC를 이용하여 Zeppelin에서 Presto로 Query를 실행하게 하는 구조 입니다. 이렇게 구현하면 Interpreter 개발은 편하지만 질의 Progress나 Kill 등의 기능을 제대로 구현하기 어렵습니다. 물론 JDBC에도 cancel() 과 같이 질의 취소 API가 있지만 Presto의 JDBC 구현에서는 다음 코드와 같이 지원하고 있지 않습니다.
1 2 3 4 5 6@Override public void cancel() throws SQLException { throw new SQLFeatureNotSupportedException("cancel"); }
일반 사용자가 SQL을 직접 실행하는 경우 질의 취소 기능은 아주 중요한 기능입니다. 특히 대용량 데이터 대상으로의 질의인 경우 질의 실행이 수분 또는 수십분 실행될 수 있기 때문에 잘못된 질의라고 판단되면 바로 질의 실행을 취소하여 Presto 클러스터의 자원을 낭비하지 않도록 해야 합니다. 이런 이유로 인해 기존에 구현되어 있는 Interpreter를 사용하기 어려웠으며 직접 개발을 결정하게 되었습니다.
새로 개발한 Presto Interpreter는 Presto의 REST API와 일부 Client 라이브러리를 이용하여 구현되었기 때문에 필요한 대부분의 기능을 구현할 수 있었습니다. 개발된 코드는 다음 github repository에서 확인할 수 있습니다.
https://github.com/babokim/incubator-zeppelin
https://github.com/babokim/zeppelin/tree/presto_acl_20160809
(최근 0.6 버전과 merge된 branch)
이렇게 직접 Presto Interpreter 를 구현하면서 원래 목표했던 질의 Kill, Progress 상황 뿐만 아니라 몇가지 부가 기능도 같이 추가하였습니다. 이 부분은 이글 아래에 계속 설명이 되어 있습니다. 다음 코드는 구현한 Interpreter 중 Presto Client Connection을 가져오는 부분에 대한 구현 일부 입니다. ClientSession이 Presto client 라이브러리 클래스 중 하나 입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21private ClientSession getClientSession(String userId) throws Exception { synchronized (prestoSessions) { ClientSession prestoSession = prestoSessions.get(userId); if (prestoSession == null) { prestoSession = new ClientSession( prestoServer, getProperty(PRESTOSERVER_USER), "presto-zeppelin-" + userId, getProperty(PRESTOSERVER_CATALOG), getProperty(PRESTOSERVER_SCHEMA), TimeZone.getDefault().getID(), Locale.getDefault(), ImmutableMap.<String, String>of(), null, false, new Duration(10, TimeUnit.SECONDS)); prestoSessions.put(userId, prestoSession); } return prestoSession; } }
Progress 정보 조회와 Query Kill 기능은 다음과 같이 구현되어 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36@Override public int getProgress(InterpreterContext context) { ParagraphTask task = getParagraphTask(context); if (!task.reportProgress.get() || task.sqlQueryResult == null) { return 0; } StatementStats stats = task.sqlQueryResult.getStats(); if (stats.getTotalSplits() == 0) { return 0; } else { double p = (double) stats.getCompletedSplits() / (double) stats.getTotalSplits(); return (int) (p * 100.0); } } @Override public void cancel(InterpreterContext context) { ParagraphTask task = getParagraphTask(context); try { if (task.planStatement == null && task.sqlStatement == null) { return; } logger.info("Kill query '" + task.getQueryResultId() + "'"); ResponseHandler handler = StringResponseHandler.createStringResponseHandler(); Request request = prepareDelete().setUri( uriBuilderFrom(prestoServer).replacePath("/v1/query/" + task.getQueryResultId()).build()).build(); try { httpClient.execute(request, handler); task.close(); } catch (Exception e) { logger.error("Can not kill query " + task.getQueryResultId(), e); } } finally { removeParagraph(context); } }
Progress 구현은 Query의 입력 데이터의 전체 Split(분산/병렬 처리를 수행하는 각 Task의 입력 데이터 정보 단위) 갯수와 현재까지 처리한 Split의 갯수 정보를 이용하여 계산하고 있는데, 정확한 진행 상황을 알 수 없습니다. 위와 같이 계산하면 SQL 처리 시 첫번째 단계인 Table SCAN 단계에 대한 진행 상태만 나타나고 Group by, Order by 등 다음 Phase에 대한 진행 상태는 알 수가 어렵습니다. 대략의 진행 상화 정보는 알 수 있기 때문에 이 질의가 오래 걸리고 있는지 금방 완료될 질의인지 사용자가 판단할 수 있기 때문에, 오래 걸리는 작업의 경우 Filter 조건을 잘못주었는지 확인하여 질의를 취소하는 등을 위해 유용한 정보로 활용할 수 있습니다.
테이블에 대한 권한 관리 기능
시스템 구축 시 가장 중요한 요청사항 중의 하나가 Catalog, Table, Column 에 대한 권한 관리 였습니다. 서비스가 여러 나라에 오픈되어 있고 각 국가별로 운영 조직이 존재합니다. 국가별 관리자는 해당 국가의 데이터만 볼 수 있도록 해야 하고, 개발자가 아닌 일반 사용자는 사용자 테이블 등과 같이 민감한 테이블의 일부 컬럼은 조회할 수 없어야 합니다. 권한 관리가 잘되어야 개발자가 아닌 일반 사용자에게 데이터를 공개할 수 있기 때문에 권한 관리 기능은 시스템 오픈을 위한 핵심 요청 사항이었습니다.
이런 보안 기능을 만족시키는 데이터베이스 솔루션은 많지 않습니다. Oracle, MySQL 등도 특정 테이블에 대해 컬럼 단위 권한을 제어하는 기능은 제공하지 않습니다. 대신 View를 만들고 View에 권한을 부여함으로써 컬럼 단위로 제어 가능합니다. Hive 역시 테이블에는 권한 관리가 가능하지만, 테이블의 컬럼 단위로 권한을 제어할 수 없으며, View도 권한 관리를 할 수 없습니다.
이런 상황에서도 쉽게 권한 관리 기능을 구현할 수 있었는데, 내부적으로 구축한 시스템의 경우 다음과 같은 제약 조건 때문입니다.
- 사용자는 MySQL, Hive, Kafka 등 각 스토리지에 직접 질의를 실행하지 않고 반드시 Presto를 이용하여 질의한다.
- 몇명의 시스템 관리자를 제외한 모든 사용자는 Presto에 질의를 수행하기 위해서는 반드시 Zeppelin을 이용해야 한다.
이 제약 조건때문에 Zeppelin의 Presto Interpreter에 권한 관리 기능 추가하면 모든 권한을 한군데에서 관리할 수 있으며, 비교적 쉽게 개발할 수 있다고 판단하였습니다. Presto에 기능을 넣을 수도 있지만 수정의 범위가 많고, 코드의 복잡도가 훨씬 높아 집니다. 그리고 Presto 오픈소스 커뮤니티에서도 권한 관리 기능을 구현하고 있기 때문에 저희 요청 사항에 맞는 기능을 별로도 만들 경우 Pull Request를 받아 주지 않을 가능성이 많다고 생각했습니다. Presto Interpreter는 직접 개발한 기능이기 때문에 코드 수정도 쉽게 할 수 있다고 판단하여 Presto Interpreter에 추가하기로 결정하였습니다.
새로 만든 권한 관리 기능은 다음과 같은 특징을 가지고 있습니다.
- Catalog, Schema, Table, Column 단위로 관리 가능
- 테이블의 Read/Write에 대한 권한은 Schema 단위로 관리
- Operation(insert, select 등) 별로 권한 관리는 하지 않음
다음은 몇가지 접근 제어 설정에 대한 예입니다. "dev"는 개발자 group, "emp"는 일반 사용자 group 입니다. 예제의 구성은 다음과 같은 권한에 대한 설정 값입니다.
- 개발자(dev) 그룹
- Hive의 access_log database(Presto에서는 Schema라는 개념)에는 read 권한
- access_log databse에는 log 관련 데이터 저장되어 있고 이 데이터는 수집기를 통해 저장되기 때문에 write 기능은 필요 없음
- Hive의 working database에는 read/write 권한 모두
- 임시 테이블 또는 질의 결과를 저장해서 재 사용하는 경우 결과 테이블 저장소
- 실제 운영 데이터가 저장되어 있는 MySQL은 read 권한
- 특정 테이블은 접근 제한(Facebook access token 테이블 등)
- Hive의 access_log database(Presto에서는 Schema라는 개념)에는 read 권한
- 일반 사용자(emp) 그룹
- Hive의 access_log database(Presto에서는 Schema라는 개념)에는 read 권한
- Hive의 working database에는 read 권한
- 일반 사용자 중 데이터 분석 팀의 경우 Wirte 권한 부여(emp_writer)
- 실제 운영 데이터가 저장되어 있는 MySQL은 read 권한
- 특정 테이블만 read 권한
- 특정 테이블 중 일부 컬름은 접근 제한
- Users 테이블은 id 만 접근 허용
다음은 위 설정 요청 사항에 대한 실제 설정 파일 내용입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42################################################################## # 개발자 권한 설정 ################################################################## # 개발자는 hive catalog의 access_log schema(hive에서는 database)에 read 접근 가능, write 기능은 부여하지 않음 # access_log 에는 원본 로그가 저장되어 있기 때문에 insert, delete 권한은 필요 없음 dev.hive.access_log=read # 개발자에게는 모든 테이블에 대해 권한 부여(read only) dev.hive.access_log.*=allow # 개발자는 hive catalog의 working schema에는 read/write 가능 # working schema는 중간 작업용 테이블 또는 결과 테이블 생성용 schema dev.hive.working=read, write dev.hive.working.*=allow # 개발자는 운영 mysql replica db에 read 접근 가능 # 'popit'는 mysql database name dev.mysql.popit=read # 개발자는 mysql 의 모든 테이블에 접근 가능 dev.mysql.popit.*=allow # 개발자라 하더라도 페이스북 로그인 토큰 등의 테이블에는 접근 불가 # 테이블이 많은 경우 전체 허용 후에 특정 테이블에 대해서만 deny 처리 dev.mysql.popit.oauth_tokens=deny ################################################################## # 일반 사용자 권한 설정 ################################################################## # 일반 사용자는 hive catalog의 access_log schema(hive에서는 database)에 read 접근 가능 # access_log 에는 원본 로그가 저장되어 있기 때문에 insert, delete 권한은 필요 없음 emp.hive.access_log=read # 일반 사용자에게 모든 테이블에 대해 권한 부여(read only) emp.hive.access_log.*=allow # 일반 사용자는 hive catalog의 working schema에는 read 가능 # 개발자가 만든 임시용 테이블 또는 분석 결과 테이블에 읽기만 가능 emp.hive.working=read emp.hive.working.*=allow # 일반 사용자는 운영 mysql replica db에 read 접근 가능 # 'popit'는 mysql database name emp.mysql.popit=read # 일반 사용자는 mysql 의 특정 테이블에만 접근 가능(테이블 권한 설정) emp.mysql.popit.articles=allow emp.mysql.popit.users=allow emp.mysql.popit.codes=allow # 일반 사용자는 users 테이블 중 특정 컬럼에만 접근 가능(컬럼 권한 설정) # id는 단순 sequence(실제 사용자 id가 아님, 다른 테이블 join을 위해 필요) emp.mysql.popit.users.id,created_at,updated_at=allow
이런 권한 관리 기능 구현 시 가장 중요한 요소는 질의를 파싱하여 Catalog, Schema, Table, Column 으로 분리하는 것입니다. Presto 내부에 기능을 구현하면 이 기능의 구현은 Presto 내부의 Parser를 이용하면 쉽게 구현할 수 있습니다. 하지만 Presto 외부에서는 별도의 Parser를 만들거나 Presto 소스 코드에서 Parser 부분만 발췌를 해야 하는데 이것도 쉬운 작업은 아닙니다.
몇가지 방안을 찾아본 결과, Presto의 질의 실행 계획 정보를 이용하는 것이 가장 간단하면서도 효율적인 방법이라 생각했습니다. 사용자가 SQL을 Zeppelin에 입력하면 Preso Interpreter는 SQL에 explain을 추가하여 Presto 서버로부터 실행계획을 받아 옵니다. 실행 계획은 문자열로 되어 있기 때문에 이 문자열의 적절하게 파싱하면 Catalog, Schema, Table, Column을 분리할 수 있습니다. 이렇게 분리한 정보와 앞의 권한 설정 정보를 비교하여 접근 가능 여부를 판단하고 있습니다.
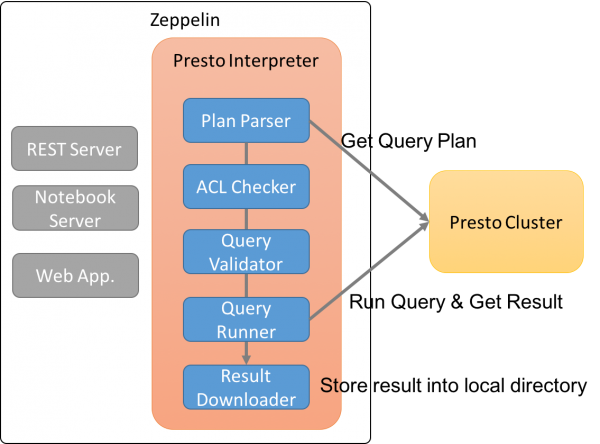
이런 구현은 꼼수라고 할 수 있는데, 실용적으로 빠르게 적용하기에는 가장 적합한 방법이라 생각합니다. github 래포지토리에 전체 구현 코드가 있습니다.
Zeppelin 의 일부 기능 권한 제어
Zeppelin은 웹 화면을 통해 Notebook의 생성, 수정, 실행, Interpreter 설정, Zeppelin Server 자체의 환경 설정 등의 기능을 수행할 수 있습니다. 일반 사용자가 이런 기능을 수행할 권한을 가지게 되면 다양한 문제가 발생할 수 있기 때문에 일부 기능에 대해 제약을 줘야 합니다.
현재 사용하고 있는 Zeppelin 0.6 버전(실제로는 0.6이 아닌 마스터 브랜치 버전으로 2016.05 버전)에서는 Apache Shiro 기반의 Authentication을 제공하고 있습니다, 그리고 로그인한 사용자의 사용자명, 그룹 등을 이용하여 Notebook의 권한 관리(Read, Writer)를 설정할 수 있습니다. 저희 내부 요청 사항에서는 이런 제약 조건 이외에 다음과 같은 제약 조건이 필요하여 Zeppelin 기능을 일부 수정하여 사용하고 있습니다.
- Notebook 생성
- 일반 사용자는 Notebook은 생성할 수 없습니다. Notebook은 개발자가 생성한 후 Owner를 해당 사용자로 지정해 줍니다.
- 설정 기능 제약
- 관리자만 Interpreter 설정, Zeppelin Server 설정 가능
Query 검증
일반 사용자가 SQL을 만들기 때문에 Presto의 서버 리소스를 모두 사용하는 질의를 실행할 수도 있습니다. 따라서 질의에 대한 검증이 필요한데 주로 다음 사항에 대해서 실행 제약을 두었습니다.
- 용량이 큰 Fact 테이블(주로 로그 테이블)은 일자로 파티션되어 있으며, SQL의 where 절에 파티션 컬럼은 반드시 존재해야 함
- where 절의 파티션 컬럼은 최종 select 절뿐만 아니라, subquery, inline view 등의 where 절에도 존재해야 함
- 모든 select 질의는 반드시 limit 절을 가지고 있어야 함
- max limit 에 대한 제약도 있음
- insert into ... select, create as select 문에서는 제약이 없음
1 2 3 4 5 6 7 8 9 10--다음 질의 실행은 경고와 함께 실행이 안됨 select * from hive.access_log.logs where path like '%id=1234%' --다음 질의는 정상 실행 --access_date 컬럼은 파티션 컬럼 --limit 절은 반드시 포함되어야 함 select * from hive.access_log.logs where path like '%id=1234%' and access_date = '20160701' limit 10000
이런 제약 조건을 검증하기 위해 앞의 권한 관리와 동일하게 SQL의 실행 계획을 이용하여 쉽게 구현하였습니다.
결과 데이터 다운로드 기능
현재 사용하고 있는 Zeppelin 0.6 버전은 Paragraph의 결과 데이터 다운로드 기능을 제공하지 않습니다. 사용자는 결과 데이터를 다운로드하여 엑셀 등으로 2차 가공하는 방식을 많이 사용하기 때문에 이 기능은 반드시 필요한 기능이었습니다.
다운로드 기능이 없는 경우 Paragraph에 SQL의 결과 데이터 모두를 나타내야 하는데 데이터가 수만건 이상이 되면 브라우저가 멈추거나 성능이 저하되어 너무 느려 사용하기 어렵게 됩니다. 그리고 Paragraph 결과 데이터를 Copy&Paste하는 경우 Excel Cell이나 Row 등이 깨질 수도 있습니다. 이런 불편함을 해소하기 위해 다음과 같은 방법으로 다운로드 기능을 구현하였습니다.
- limit 절의 값과 상관없이 Paragraph 결과에는 1000개의 row만 저장
- row가 1000개 이상인 경우 Zeppelin 서버의 특정 디렉토리에 Paragraph ID를 파일명으로 하는 파일을 생성하여 CVS 파일 포맷으로 저장
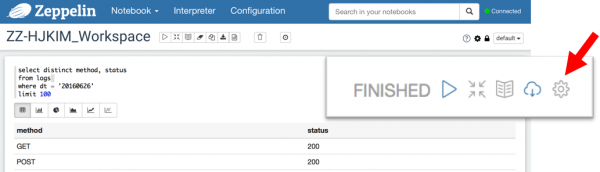
- 아래 화면과 같이 Zeppelin에 새로 추가한 "다운로드" 버튼을 클릭하면 서버에 파일이 있으면 파일은 다운로드 하고, 파일이 없으면 Paragraph 결과를 다운로드.
- 서버에 저장된 파일은 Paragraph가 다시 실행되면 Overwrite 되고, 정해진 주기로 자동 삭제.
1, 2편에 걸쳐 현재 운영하고 있는 잡플래닛 서비스를 위한 매우 심플한 버전의 대용량 데이터 BI 시스템 구성을 확인해 보았습니다. 시스템은 한번에 다 만들어진것이 아니라 사용하면서 조금씩 개선하는 형태로 진행되어 6개월 정도 진행되어 지금의 모양을 갖추게 되었습니다.
이 시스템이 잘 만들어진 시스템이라고 할 수는 없지만 현재 가용한 개발 리소스와 사용자가 필요로 하는 기능에 최적화된 시스템이라고 할 수 있습니다. 오픈 소스를 최대한 활용하면서, 오픈 소스에서 제공하지 않는 기능에 대해서는 적극적으로 개선하면서 시스템을 구축하였습니다. 이 시스템을 기반으로 하여 최근에는 실시간 데이터 수집을 위해 Kafka와 연동하고 있으며, Presto에서 직접 Kafka의 Topic에 대해 SQL을 실행할 수 있도록 구성하였습니다. 아직 복잡한 분석에 대한 처리는 하고 있지 못하지만 이 시스템을 기반으로 점점 확장하면서 실제 서비스와 연동하는 분석 기능을 추가할 예정입니다.
시스템을 구축 하면서 수정되거나 개선된 내용을 오픈 소스에 다시 Contribution 하고 싶었지만 영어 표현력의 부족과 게으름으로 인해 적극적으로 활동을 하지는 못했습니다. 수정된 사항은 Github에 공개되어 있으니 필요하신 분은 참고하시기 바랍니다.