RNN(Recurrent Neural Network)과 Torch로 발라드곡 작사하기

최근 RNN(Recurrent Neural Network) 관련 자료를 찾다가 안드레이 카패시(Andrej Karpathy)가 쓴 The Unreasonable Effectiveness of Recurrent Neural Networks라는 글을 보게 되었다. 복잡한 수식 때문에 딥러닝 in Torch 책을 쓸 때도 잠깐 포기했었는데, 이 글에서는 RNN에 대해 개념적으로 쉽게 풀이했으며 무엇보다 학습 및 샘플링 코드를 모두 자신의 깃허브 char-rnn 레파지토리에 공개해서 쉽게 따라해볼 수 있었다.
이 글에서는 The Unreasonable Effectiveness of Recurrent Neural Networks에서 설명하는 내용을 간단히 간추려서 설명한다. 또한 char-rnn 코드를 한글(utf-8)을 지원하도록 수정한 char-rnn-kor 코드를 소개한다. 그리고 char-rnn-kor를 사용하여 한글 발라드 가사를 학습하고, 학습된 모델을 바탕으로 발라드곡 가사 텍스트를 생성하는 방법을 따라해본다.
RNN(Recurrent Neural Network) 이란
RNN(Recurrent Neural Network)은 연속성이 있는 또는 시간적인 순서가 있는 데이터를 다루는 신경망이다. 기존의 피드 포워드(Feed Forward) 신경망은 하나의 입력 데이터를 하나의 출력 데이터로 매핑한다. 반면 RNN에서는 입력 데이터의 시퀀스(sequence)를 출력 데이터의 시퀀스(sequence)로 매핑한다. 아래 그림을 보자.
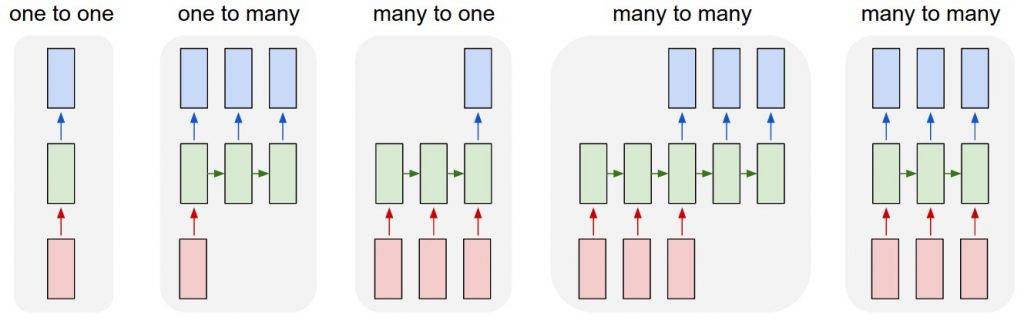
그림. 여러가지 RNN 모델
(출처:The Unreasonable Effectiveness of Recurrent Neural Networks)
첫 번째 one-to-one의 경우 기존의 피드 포워드(Feed Forward) 신경망이다. 빨간색 네모상자는 하나의 입력 데이터 또는 하나의 벡터로, Torch의 경우 하나의 Tensor 객체에 해당한다. 녹색 네모상자는 네트워크 모델이다. 파란색 네모상자는 하나의 출력 데이터 또는 하나의 벡터, Torch의 경우 하나의 Tensor 객체에 해당한다. 즉 one-to-one의 경우 하나의 입력 Tensor를 하나의 출력 Tensor로 매핑하게 된다.
네 번째 many-to-many의 경우가 일반적인 RNN 모델로, 입력의 시퀀스를 출력의 시퀀스로 매핑한다. 예를 들어 구글의 기계 번역(machine translation)의 경우, 입력 단어의 시퀀스를 번역 단어의 시퀀스로 매핑한다.
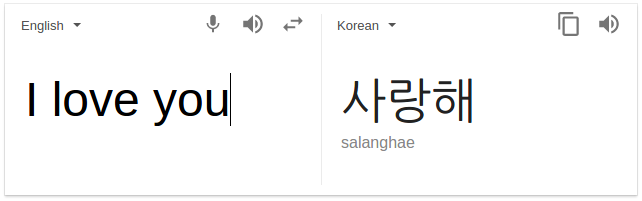
그림. 구글 기계 번역
위의 경우 입력 시퀀스는 ['I', 'love', 'you']이고, 출력 시퀀스는 ['사랑해']다.
코드로 풀어보면
RNN 모델을 코드로 풀어보면 다음과 같다. x는 입력 벡터이며, y는 출력 벡터다.
1 2rnn = RNN() y = rnn.step(x) # x is an input vector, y is the RNN's output vector
(출처:The Unreasonable Effectiveness of Recurrent Neural Networks)
RNN 모델의 출력 y는 현재 시점의 입력 x 뿐만 아니라, 이전 입력의 시퀀스에 영향을 받는다. 따라서 RNN에서는 이러한 내부 상태를 은닉 벡터(h)에 저장한다.
1 2 3 4 5 6 7 8class RNN: # ... def step(self, x): # update the hidden state self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x)) # compute the output vector y = np.dot(self.W_hy, self.h) return y
(출처:The Unreasonable Effectiveness of Recurrent Neural Networks)
내부의 상태는 self.h에 저장되며, 현재 시점의 은닉 벡터(h)는 아래의 요소를 통해 계산된다.
- x: 현재 시점의 입력
- W_xh: 입력층->은닉층으로의 파라미터 행렬
- h: 이전 시점까지의 은닉 벡터
- W_hh: 은닉층->은닉층으로의 파라미터 행렬
- tanh: 활성화 함수
수식으로 쓰면 아래와 같다.
![]()
출력 y는 은닉층->출력층으로의 파라미터 행렬 W_hy와 현재 시점의 내부 상태 h를 통해 계산된다.
문자 단위의 언어 모델
기계 번역과 같이 입력 데이터가 문자열이고 출력 데이터가 문자열인 경우, 문자간의 의존성 또는 문맥을 찾는 모델을 언어 모델(language model)이라고 부른다. 그리고 언어 모델에는 단어(word)를 기반으로 학습하는 모델과 문자(character)를 기반으로 학습하는 모델이 있다. 이 글에서는 RNN을 이용하여 문자 단위의 언어 모델을 학습하는 방법을 소개한다.
가장 간단한 예로 입력 데이터셋이 "hello"인 경우를 생각해 보자. 이 경우 문자 사전에는 ['h', 'e', 'l', 'o'] 네 단어로 구성된다. 그리고 개념적으로 학습의 목표는 다음과 같다.
- ['h']가 입력이라면, 다음 문자는 'e'여야 한다.
- ['h', 'e']가 입력이라면, 다음 문자는 'l'이어야 한다.
- ['h', 'e', 'l']이 입력이라면, 다음 문자는 'l'이어야 한다.
- ['h', 'e', 'l', 'l']이 입력이라면, 다음 문자는 'o'여야 한다
눈여겨 봐야할 부분은 2번 단계와 3번 단계의 예측 출력은 모두 'l'이지만, 바로 앞의 문자는 각각 'e'와 'l'로 서로 다르다. 따라서, 바로 앞의 문자만으로는 다음 문자를 예측할 수 없고, 이전 문자들의 시퀀스를 모두 이용해야 한다.
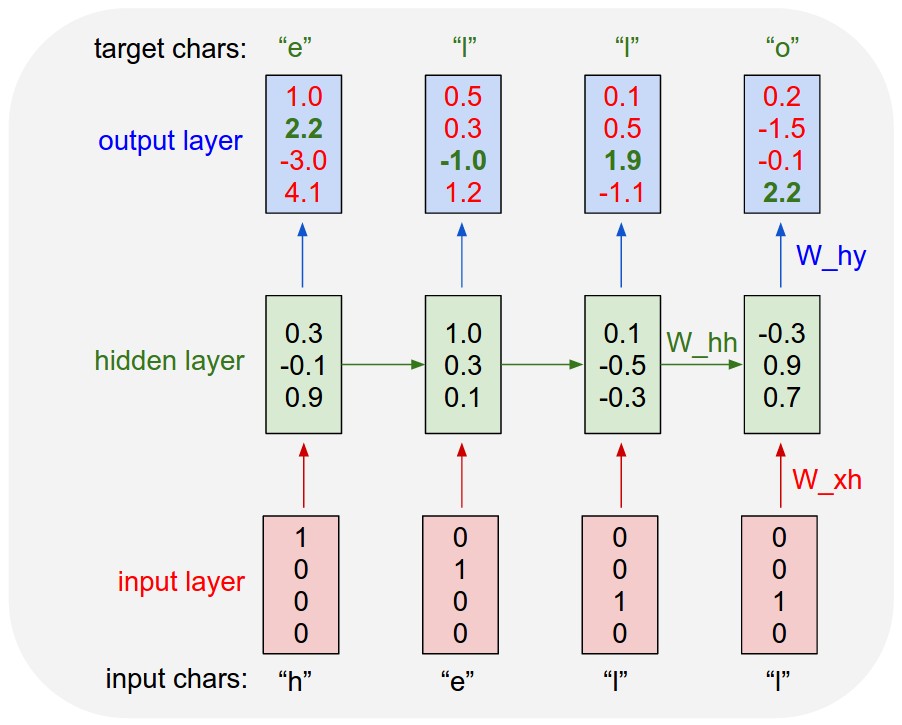
그림. 입력 시퀀스가 ['h', 'e', 'l', 'l']인 경우, 출력 시퀀스 ['e', 'l', 'l', 'o'] 학습하는 과정
(출처: The Unreasonable Effectiveness of Recurrent Neural Networks)
각 입력 단어는 크기가 4인 벡터로 만들 수 만든다. 벡터는 문자 사전 ['h', 'e', 'l', 'o']의 인덱스에 따라, 문자가 해당 사전의 인덱스와 일치하면 1 아니면 0인 값을 같는다. 예를 들어 문자 'e'는 두번째 인덱스가 1이며 나머지는 모두 0인 벡터다.
RNN의 step() 함수를 처음으로 통과시켜 출력 문자의 시퀀스의 값을 계산한다. 입력과 마찬가지로 출력에서도 문자 사전의 인덱스와 일치하는 원소의 값이 가장 높아야 한다. 예를 들어 문자 'e'의 경우 2번째 원소의 값이 나머지 인덱스의 원소 값보다 커야 한다. 따라서 다음 학습에서는 이들 값이 더 커지도록 파라미터 행렬을 back propagation 과정을 통해 업데이트한다. 예를 들어 다음 학습 에폭에서는 출력 시퀀스에서 문자 'e'의 2번째 원소의 값이 이전의 값 2.2보다 높은 2.3, 2.4 등의 값을 가지도록 학습시킨다.
흥미로운 예제들
The Unreasonable Effectiveness of Recurrent Neural Networks 글에서는 문자 단위의 RNN 모델을 이용하여 학습한 몇 가지 예제들을 보여준다.
세익스피어의 희곡
세익스피어의 희곡을 학습하여, 아래와 같이 새로운 희곡 스타일의 문자를 생성했다.

그림. 세익스피어 스타일로 생성한 새로운 희곡
(출처: The Unreasonable Effectiveness of Recurrent Neural Networks)
문자들의 시퀀스를 학습시켰을 뿐, 영어 문법과 희곡 스타일의 규칙이 어떻게 되는지는 알려주지 않았다. 그럼에도 영어 단어를 상당히 정확히 학습했고, 구두점과 띄어쓰기 등을 이해했다. 더 놀라운 점은 희곡이라는 특수한 스타일까지 그대로 흉내낸다는 점이다.
C 프로그램 코드
개발자로서 더욱 흥미로운 예제는 프로그램 코드에 대한 예다. 아래는 깃허브의 리눅스 레파지토리에 있는 프로그램 코드를 학습 후, RNN 모델이 생성한 텍스트 내용이다.
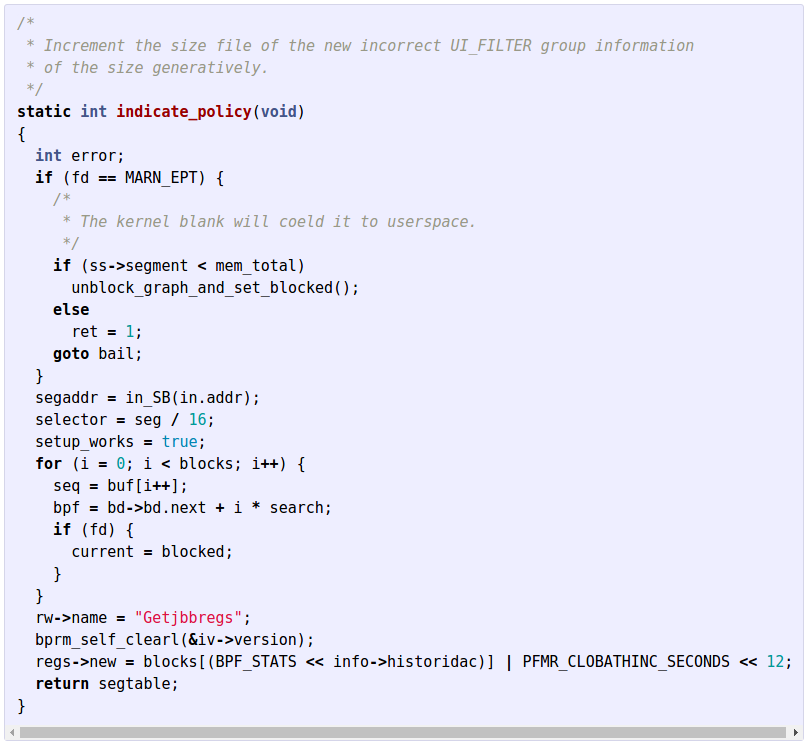
그림. 프로그램이 직접 짠 프로그램
(출처: The Unreasonable Effectiveness of Recurrent Neural Networks)
주석과 함수, 그리고 for 루프 등 C 언어의 기본 구분을 놀라울정도로 충실히 수행했다.
한글 학습하기: char-rnn-korean
안드레이 카패시(Andrej Karpathy)는 관련 코드를 모두 자신의 깃허브 char-rnn 레파지토리에 공개했고, 한글을 학습해 보았다. 하지만 Torch의 기반 언어인 Lua에서 문자는 모두 1바이트로 처리되며, 유니코드는 공식적으로 지원하지 않는다. 따라서 char-rnn 코드를 그대로 사용하면 한글 학습이 제대로 진행되지 않는다.
그래서 char-rnn에 한글(utf-8)을 지원하도록 코드를 일부 수정했고, 깃허버의 char-rnn-kor에 올려두었다. 이 프로젝트에서는 utf-8 지원 모듈인 luautf8을 이용하여 char-rnn이 한글 및 기타 유니코드 기반 언어에서 동작하도록 확장했다
한글 지원을 위한 주요 변경 내용
프로그램 코드 상의 변경 내용은 다음과 같다.
- util/CharKorSplitLMMinibatchLoader.lua util/CharSplitLMMinibatchLoader.lua 코드에서 데이터셋을 처리하는 부분에 utf-8을 지원하도록 변경 util/CharSplitLMMinibatchLoader.lua 코드에서 입력데이터셋을 ByteTensor에 저장하던 부분을 ShortTensor를 사용하도록 변경
- train_kor.lua train.lua 훈련 코드에서 CharSplitLMMinibatchLoader 대신 CharKorSplitLMMinibatchLoader을 사용하도록 변경
- sample_kor.lua sample.lua 샘플링 코드에서 primetext(생성할 텍스트의 앞부분)을 처리하는 코드에서 utf-8을 지원하도록 변경
또한 한글 데이터를 학습할 수 있도록 발라드 노래 가사 데이터셋을 'data/lyrics_ballad/input.txt'에 포함했고, 이미 학습된 모델은 'cv/lm_lstm_epoch50.00_1.2327.t7'에 추가했다.
샘플링
학습하기에 앞서, 이미 학습된 모델을 사용하여 새로운 발라드 노래 가사를 생성해 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20$ th sample_kor.lua cv/lm_lstm_epoch50.00_1.2327.t7 -gpuid -1 -length 200 -primetext '사랑은 ' -temperature 0.9 creating an lstm... seeding with 사랑은 -------------------------- 사랑은 언제나 그래 난 이직 못난 그대 떠나야 좋아 밤새 알는 고 없은 여기의 오랜 옛 땅을 수 없다면 광화문 말고 꽃리 네 우리 푸른 하늘아나 그대 웃음따라 내꿈을 따라 지친 시간은 멈추고 따스한 길에 쓸쓸히 너무 지워 버린 그 밤은 가슴에 묻혀서 내가 보낸 날 찾었던 너의 마음속으로 사랑한 거에 사랑이여 내게 감추고 있다고 나를 잃
샘플링에서 사용한 옵션은 다음과 같다.
- -gpuid -1 학습 과정에서 GPU가 아닌 CPU를 사용했다. GPU가 기본값이며, CPU를 이용하여 학습했다면 샘플링에서도 CPU를 사용해야 한다.
- -length 200 200 단어까지 문자를 생성한다.
- -primetext '사랑은 ' '사랑은 '으로 시작하는 문자열을 생성한다.
- -temperature 0.9 예측의 우연성. 낮을수록 원본 텍스트와 가까워지며, 높을수록 결과가 다양해지지만 문법 오류가 더 많이 포함된다.
학습하기
학습을 위한 명령은 아래와 같다.
1th train_kor.lua -data_dir data/lyrics_ballad -gpuid -1 -rnn_size 300 -num_layers 3 -dropout 0.4
학습에서 사용한 옵션은 다음과 같다.
- -data_dir data/lyrics_ballad 학습할 원본 텍스트를 포함하는 디렉토리
- -gpuid -1 CPU를 사용하여 학습
- -rnn_size 300 사용할 rnn 사이즈
- -num_layers 3 사용할 레이어 개수
- -drop_out 0.4 드롭아웃 확률
내 로컬 머신에서는 학습하는데 19시간 걸렸다. 옵션 및 관련 내용에 대해 더 자세히 알고 싶다면 char-rnn-kor을 참고한다.
Deprecated
참고로 저자는 자신의 깃허브 char-rnn 레파지토리의 코드에서 구현한 rnn보다는 더 멋진/적은/깔끔한/빠른 Torch 코드를 기반으로 char-rnn을 처음부터 다시 구현한 torch-rnn을 사용하기를 권한다. 그럼에도 저자의 코드는 rnn을 이해하고 공부하기에는 좋은 자료다.