Time series OLAP – Glue Architecture(5)

Druid - 어벤저스
계획을 세우지 못하는 것은 실패를 계획하는 것이다 - 에피존스
람다 아키텍처는 데이터 처리 아키텍처로 대용량 데이터에 대한 배치 처리와 스트림 처리 방법을 활용하여 처리하기 위해 설계된 데이터 프로세싱 아키텍처이다.
아래의 아키텍처에서 수집된 레코드는 목적에 따라 배치와 실시간 처리 시스템으로 병렬적으로 제공되고 적재된 데이터는 필요 시 데이터를 질의 할 수 있다.
람다의 기본적인 아키텍처는 배치 레이어, 실시간스트리밍 스피드 레이어, 서빙 레이어로 구성된다.
[참고 : https://en.wikipedia.org/wiki/Lambda_architecture]
배치 레이어
대용량 데이터 처리를 위해 분산 처리 시스템을 사용하여 데이터를 처리한다. 배치 레이어에서는 에러가 발생하는 경우 재연산등을 수행하여 데이터의 처리 정확도를 높인다. 배치 레이어에 대표적인 예로는 Apache Hadoop이다. 아래의 도식에서는 Kafka cluster로 부터 input_topic을 Storm과 Hadoop으로 각각 처리하고 Serving DB로 적재하는 프로세스를 보여준다. 수집 데이터는 Kafka로 일원화 하고 Velocity 제약 혹은 응용에 따라 실시간 혹은 배치로 데이터를 처리하게 된다. 실시간인 경우는 대부분 이벤트 감지 및 데이터 필터링등으로 사용되며 배치 처리는 주기적 단위의 벌크 처리를 통해 통계데이터를 생성하는 등의 작업을 수행한다.

https://www.oreilly.com/ideas/questioning-the-lambda-architecture
스피드 레이어
스피드 레이어에서는 주로 데이터 스트림에 대한 처리(연속된 데이터의 처리) 등을 담당한다. 최신 데이터에 대한 빠른 처리를 보장해야 하며 latency(지연 시간)을 최소화 하는것을 목표로 한다. 스피드 레이어에 대표적인 예로는 Apache Storm, Apache Spark Streaming, Flink 등이 있다. 스트리밍으로 처리된 결과 output등은 빠른 데이터 적재 및 질의 속도 보장를 위해 NoSQL에 저장되기도 한다.
서빙 레이어
배치와 스피드의 Output에 대해 ad-hoc query(임의의 질의) 등의 데이터를 질의 하는 레이어이다. Druid의 경우 broker를 통해 배치와 스피드 레이어에 대한 통합 질의를 제공한다. 앞에서 언급한 것처럼 스피드 레이어의 output등은 NoSQL(Cassandra, Hbase) 등에 저장하기도 한다. 위의 도식에서 App은 서빙 레이어를 통해 speed_table과 batch_table에 질의를 수행한다.
Druid의 Lambda Architecture
일반적으로 람다 아키텍처는 실시간/배치 처리 및 서빙과 관련하여 서로 다른 기술들을 혼용해야 하는 경우가 많은데, Druid는 내부 모듈에서 배치와 실시간에 대한 처리 인터페이스 및 Broker를 통한 통합 질의를 지원한다. 다음은 배치 레이어에서의 데이터 Ingestion 및 질의에 대한 flow이다.
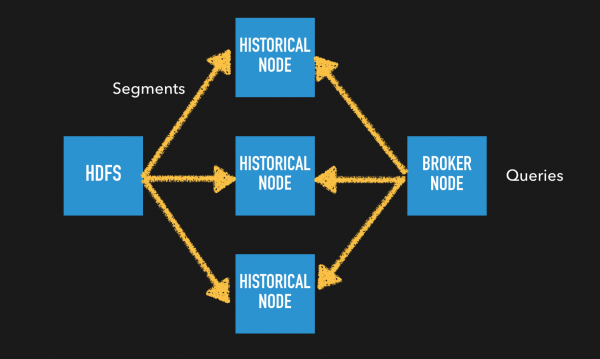
Batch Ingestion
기존 파일 시스템(HDFS/S3 등)에서 batch ingestion을 수행하여 druid에 segment를 생성한다. Broker node가 서빙 레이어를 담당하며 질의 요청시 해당 segment를 가지고 있는 Historical Node로 부터 결과 set을 받아 merge하여 client에게 전달한다.
다음은 real-time 데이터 ingestion 및 질의에 대한 flow이다.
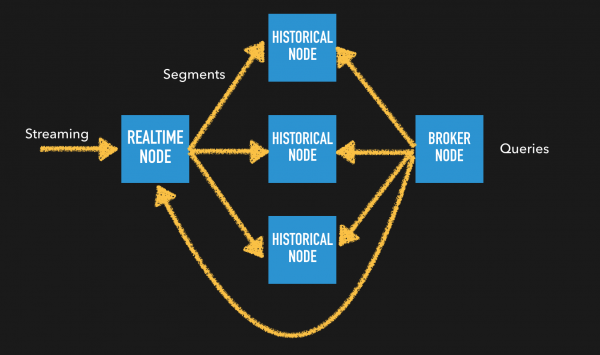
Real-time Ingestion
실시간으로 feeding되는 데이터를 Druid의 Real-Time task가 indexing하여 Broker node로 부터 들어온 질의에 대해서는 바로 응답을 주고, 일정 기간이 지난 segment는 Historical Node에서 결과를 return하게 된다. Druid에서 이런 구조가 가능한 이유는 time에 대한 segment를 분리하여 저장하기 때문이다. Broker에서 요청된 쿼리에 대한 결과 셋에 대해 최신의 데이터는 Real-Time task에서 오래된 데이터는 Historical Node에서 쿼리 결과를 각각 리턴하고 broker가 merge하여 최종 결과셋을 client에 전달한다.
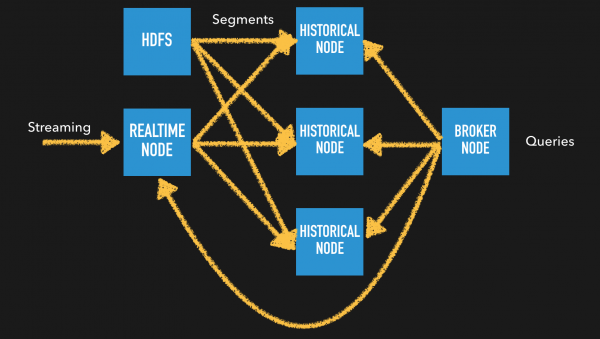
Lambda Architecture
위의 도식은 배치와 실시간 처리가 혼재된 경우이다. 단, 이 경우는 저장되는 Segment 단위(Granularity)가 동일한 경우(내부 테스트 결과 granularity가 동일 하지 않아도 상관없다. 예를 들어 granularity가 기존 배치 segment가 DAY 기준이였다가 실시간에서 HOUR단위로 segment가 생성된다고 하면 기존 DAY기준 segment는 해당일에 00시로 간주된다.) 에 위와 같은 구조가 가능하다. HDFS에서 Batch Ingestion을 통해 주기적으로 데이터를 적재하고 최신의 데이터는 스트리밍 방식으로 Real-time task가 담당한다. 이 또한, Real-time task에서 일정 기간이 지나면 Historical Node로 segment는 hand-off 된다.
Glue Architecture
Druid의 실시간 데이터 수집에서 전처리(Pre-processing)가 필요한 경우 - 현재까지는 Druid에 바로 적재할 수 있는 데이터 타입이 flatten JSON, CSV, TSV 등으로 제한적이다. Nested JSON데이터 또는 가공이 필요한 경우 또는 Stream데이터의 조인 등 전처리가 필요할 수 있다. 이때는 아래 도식과 같이 input 데이터 소스를 Kafka에 두고 Samza, Storm, Spark Streaming, Flink 등 별도의 Stream Processor를 둘 수 있다.
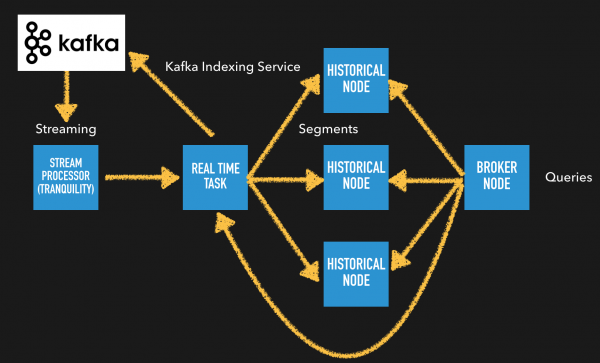
Glue Architecture
위의 도식에서처럼 Kafka를 통해 Stream Processor를 별도 구동하여 전처리를 수행하고 Tranquility라이브러리를 통해 Druid에 적재하거나 Stream Processor를 통해 처리된 결과 셋을 다시 Kafka에 넣고 Kafka Indexing Service를 통해 실시간으로 데이터를 수집할 수 있다. Druid는 다른 Streaming기술과 유연하게 엮일 수 있도록 Tranquility라이브러리를 제공한다. 또한, 이미 정제된 데이터가 Kafka에 적재된 경우 Kafka Indexing Service를 통해 Kafka의 데이터를 Ingestion하는 방식을 취하고 있다. 이때, 유입된 데이터는 전처리후 Kafka에서 Camus를 통해 HDFS로 적재한 후 주기적으로 Batch Ingestion을 시도할 수도 있다.
다음 글에서는 Druid를 Production에 적용시 고려해야 할 사항과 개인적으로 경험한 문제상황에 대한 Trouble Shooting 에 대해 살펴볼 예정이다.
연재 순서는 : Druid 입문(1) -> 실시간 Ingestion(2) -> Batch Ingestion(3) -> Segment deep dive(4) -> Glue Architecture(5) -> Trouble Shooting(6)
TO BE CONTINUED