멜론 빅데이터 이야기

멜론의 빅데이터 도입 시 고려했던 점과 시스템을 소개하는 글로 데이터를 수집, 분석 그리고 결과를 서비스하기까지의 과정에서 사용되는 오픈 소스도 소개합니다.
조금이나마 빅데이터 시스템 도입 시, 도움이 되었으면 좋겠습니다.
소개
2011년 10월 가을, 멜론은 MLCP(Music Life Connected Platform) 프로젝트를 시작했습니다. 프로젝트 핵심은 사용자의 10년간의 소비 이력을 분석하여 아티스트와 기획사 등의 이해 관계자에게 정보를 제공하고, 이를 활용해 새로운 콘텐츠를 마케팅할 수 있는 플랫폼입니다. 물론, 사용자에게 양질의 콘텐츠를 제공하는 것은 기본이고요.
사업이 진행되면서, IT 개발팀에서도 고민이 시작되었습니다. Oracle DB에 저장된 데이터를 Java 배치를 통해 분석하고, 그 결과를 Oracle DB에 저장해 서비스하는 아주 기본적인 아키텍처였고, 사용자의 이력 데이터는 용량 문제로 1년 이상 저장할 수 없었습니다.
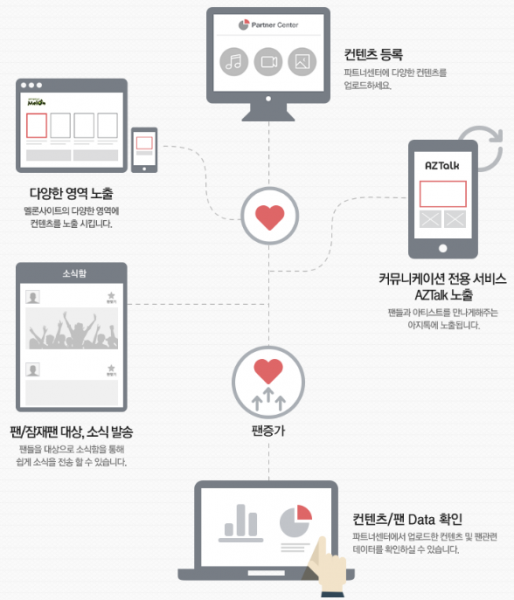
[Melon MLCP 콘텐츠 흐름]
빅데이터 시스템 도입
기존 Java 배치와 Oracle DB를 이용한 분석 애플리케이션의 한계, 대량 데이터를 보관 서비스할 대용량 저장소, 분석 알고리즘(기계학습)의 필요로 빅데이터 시스템 도입을 적극적으로 검토하기 시작했습니다. 검토 끝에 오픈 소스 기반의 하둡 에코 시스템, 상용 솔루션(Netezza, Greenplum, Exadata) 마지막으로 SK 플래닛의 SPADE라는 솔루션을 찾을 수 있었습니다. 지금은 많은 부분 상황이 좋아졌지만 오픈 소스를 선택할 경우, 인력과 안정성에 문제가 있고, 상용 솔루션은 비용의 문제가 있었습니다. 결국, 앞으로의 서비스 성장 가능성과 비용을 생각했을 때, 오픈 소스로 방향을 잡고 이를 해결하기 위해 내부 엔지니어 육성과 빅데이터 시스템을 구축하고 기술지원이 가능한 파트너사를 만났습니다. 개인적인 생각은 빅데이터 시스템 도입의 주요 키는 기술 내재화와 꼭 빅데이터 시스템이 필요한 서비스라고 생각합니다. 지금은 더욱 많은 솔루션이 있어서 선택이 넓어졌지만 절대 기술 내재화 없이는 한계가 존재할 수밖에 없고, 빅데이터가 필요하지 않은 서비스에 기술적 호기심 또는 서비스 발전 예측만으로는 빅데이터 시스템 도입에 성공할 수 없다고 생각합니다.
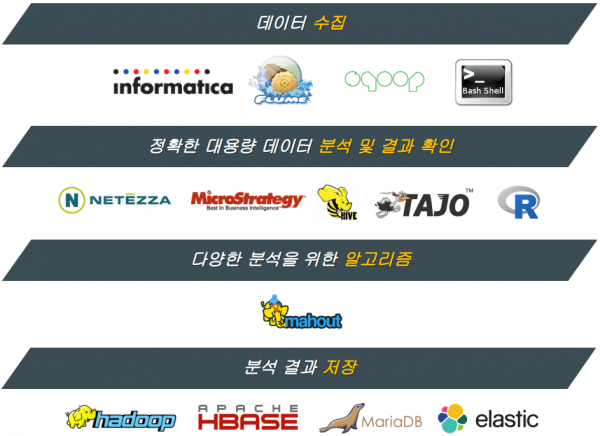
[2015까지의 Melon Data Platform]
데이터 처리 과정
데이터를 처리하는 과정은 크게 수집, 분석 그리고 서비스 세 단계로 이뤄지고 있습니다.
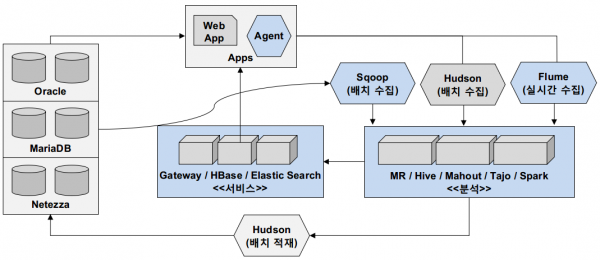
[Melon의 데이터 처리 과정: 수집-분석-서비스]
수집은 Flume을 이용한 실시간 수집과 Hudson을 이용한 배치 수집으로 나뉘며, 배치 수집은 Sqoop을 이용한 DB 수집과 Shell Script를 이용한 데이터 수집으로 또 나뉩니다. 이렇게 수집된 데이터는 분석 클러스터에 저장됩니다. Sqoop은 매시간 증분의 데이터를 가져오며, 최한시에 데이터 보정이 필요한 테이블에 한해서 전체 데이터를 가져옵니다. 이때 반드시 direct mode로 가져와 데이터를 병렬로 균등하게 가져올 수 있게 해야 합니다. Flume에서 수집하는 데이터는 1시간마다 Shell 스크립트(scp)로 재수집하여 장애로 인한 데이터 유실을 대비하며, 5초 단위 배치로 수집 Flume Agent에 전송합니다.
분석은 유실 허용과 서비스 신속성 여부에 따라 실시간 또는 배치 분석을 하고 있으며 분석 클러스터에서 용도에 맞게 MapReduce, Hive, Mahout, Tajo, Spark, 실시간 분석 애플리케이션에 의해 분석됩니다. 주로 Hive를 이용하여 서비스 분석을 많이 하며, 성능 또는 특정 알고리즘에 의해 분석이 필요한 경우 MapReduce와 Mahout을 이용합니다. Tajo의 경우에는 데이터 분석가들이 빠르게 데이터를 확인하는 경우와 신속성이 중요한 서비스들(예: 마케팅 분석 플랫폼)에서도 사용되고 있습니다. Spark 역시 Melon의 많은 서비스에서 사용되지는 않지만 Contents Based 추천과 같은 곳에서 사용되고 있습니다. 주로 SQL 기반의 분석 플랫폼을 유지하기 위해 많은 부분 노력하고 있습니다.
서비스는 분석된 결과를 다른 서비스에 제공하는 것을 말하며, 주로 온라인 서비스와 통계 시스템이 이에 해당합니다. 온라인 서비스는 최대한 MySQL을 이용해 제공합니다. 4천만건 이상의 데이터 또는 실시간으로 데이터를 서비스에 제공하기 위해서는 HBase를 사용합니다만 기존 서비스 데이터와의 JOIN과 Index 등의 한계로 최대한 한 사용을 지양하고 있습니다. 물론 서비스 중에는 HBase의 데이터 아키텍처가 더 유용한 경우에는 MySQL을 사용하지 않습니다(예: 채팅과 타임라인형 데이터).
Melon에서도 준 실시간으로 데이터를 사용자에게 제공해야 하는 경우가 있습니다. 이때는 Reactor 기반의 내부에서 개발한 실시간 처리 애플리케이션을 이용합니다. 수집에서부터 서비스에 제공되기까지 15초 정도에 처리할 수 있습니다. Spark Streaming 도입도 검토했지만, 개발 및 운영 어려움과 무엇보다 Melon은 Spark Streaming까지 도입할 만큼 대량의 실시간 처리 서비스는 아직 없습니다. 물론 곧 이런 분류의 서비스를 위해 새로운 빅데이터 플랫폼을 구축 중이지만 글 만이 아닌 정말 구축이 돼 운영되면 다시 소개해 드리겠습니다.
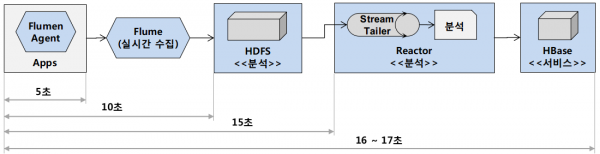
[Melon 준 실시간 처리 과정]
빅데이터 운영
빅데이터를 운영하면서 몇 가지 고려 사항을 공유하고자 합니다.
첫째, 간단한 연산도 튜닝하면 큰 성능 향상이 있을 수 있습니다. 예를 들어 데이터의 형 변환, 실수 연산 최적화, 객체의 재사용과 같이요. 데이터 레코드당 0.00001초라도 절약하더라도 100억건의 레코드를 처리한다면, 10,000초를 대략 절약할 수 있지요. 그러니 Spark, MapReduce, SQL on Hadoop을 사용하더라도 데이터 처리량이 많은 경우에는 최대한 효율적으로 개발해야 합니다.
둘째, 네트워크 사용량을 항상 감시해야 합니다. 효율적으로 클러스터의 규모가 큰 경우 네트워크가 효율적으로 구성 되었는지(Network Topology), 대량의 데이터 복제로 다른 분석 작업이 영향을 받지는 않는지(Bandwidth Throttling) 모니터링을 해야 합니다. 또한, 네트워크 구성 시 가능한 10G로 구성해 네트워크로 인한 분석 지연을 최소화해야 합니다. 40G는 아니더라도요. ^^
셋째, 적당한 클러스터 부하입니다. 분석 작업이 과도하게 몰리면 시스템 장애(디스크, 장비 온도 상승 등)가 수시로 발생하며, 오히려 적절히 배분한 경우보다 늦게 작업이 끝나는 경우(리소스 경합)가 많습니다.
그 밖에도 하둡 배포판 업그레이드 시의 기능 변경으로 인해 기존 로직의 오류 발생, 분석 작업 특성에 맞는 Job 튜닝, 잦은 H/W 고장을 대비한 모니터링 등 여러 가지 고려 사항이 있었습니다.
결론
짧게나마 Melon의 빅데이터 이야기를 마칩니다. 지금은 여러 빅데이터 클러스터 간의 데이터 교환이 많아져서 이러한 Data Flow를 잘 관리할 수 있고, 실시간성을 더 높이기 위한 아키텍처로 진화 중입니다. 기회가 된다면 내년 초쯤에 공유할 수 있을 것으로 예상합니다.
그리고 여기 소개된 내용 중에 질문 혹은 기타 의견이 있는 경우 댓글로 남겨주시면 적극 답변 드리겠습니다.