개발자가 배우는 R : 4강, 데이터프레임 가공하기

개요
이번 포스팅에는 R에서 가장 많이 쓰이는 데이터프레임을 가공하는 방법을 알아본다. 이를 위해 데이터프레임을 조작하는 방법과 관련된 외부 패키지 reshape 사용법을 알아본다.
코드중심의 설명이기 때문에 본문 보다는 코드의 주석이 집중적으로 추가되어 있으니 참고 바란다.
데이터프레임 조작하기
데이터프레임 예제 #1 : leadership
임의로 leadership 객체를 만들어 데이터프레임 조작을 알아보자.
leadership 데이터프레임 생성
우선 객체를 아래와 같은 코드로 생성 해보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17> manager <- c(1, 2, 3, 4, 5) > date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09") > gender <- c("M", "F", "F", "M", "F") > age <- c(32, 45, 25, 39, 99) > q1 <- c(5, 3, 3, 3, 2) > q2 <- c(4, 5, 5, 3, 2) > q3 <- c(5, 2, 5, 4, 1) > q4 <- c(5, 5, 5, NA, 2) > q5 <- c(5, 5, 2, NA, 1) > leadership <- data.frame(manager, date, gender, age, q1, q2, q3, q4, q5, stringsAsFactors = FALSE) > leadership manager date gender age q1 q2 q3 q4 q5 1 1 10/24/08 M 32 5 4 5 5 5 2 2 10/28/08 F 45 3 5 2 5 5 3 3 10/1/08 F 25 3 5 5 5 2 4 4 10/12/08 M 39 3 3 4 NA NA 5 5 5/1/09 F 99 2 2 1 2 1
데이터 프레임 열 추가하기
1 2 3 4 5 6 7 8 9 10 11> leadership$agecat[leadership$age > 75] <- "Elder" # 새로 agecat 열을 만드는데 leadership의 나이가 75보다 크면 Elder를 넣는다. > leadership$agecat[leadership$age > 45 & # &를 붙이면 라인을 이어서 다음 라인에 명령을 추가로 입력 할 수 있다. + leadership$age <= 75] <- "Middle Aged" # leadership의 나이가 45보다 크고 75살 보다 작거나 같으면 Middle Aged를 넣는다. > leadership$agecat[leadership$age <= 45] <- "Young" # 나이가 45보다 작거나 같으면 Young을 넣는다. > leadership # leadership을 출력해보면 agecat이 나이에 따라 값이 생겼다. manager date gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 M 32 5 4 5 5 5 Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 4 4 10/12/08 M 39 3 3 4 NA NA Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder
변수명 불러오기 및 바꾸기
1 2 3 4 5 6 7 8 9 10 11> names(leadership) # 데이터 프레임 변수명 불러오기 [1] "manager" "date" "gender" "age" "q1" "q2" "q3" [8] "q4" "q5" "agecat" > names(leadership)[2] <- "testDate" # 2번째 열의 변수명 바꾸기 > leadership manager testDate gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 M 32 5 4 5 5 5 Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 4 4 10/12/08 M 39 3 3 4 NA NA Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder
데이터프레임 예제 #2 : newdata
leadership 객체에서 NA 데이터 처리를 처리한 newdata 데이터프레임을 만든다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21> leadership # 현재 leadership에는 4번째 행이 NA값을 가지고 있다. manager testDate gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 M 32 5 4 5 5 5 Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 4 4 10/12/08 M 39 3 3 4 NA NA Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder > is.na(leadership[, 6:10]) # is로 시작하는 함수는 무엇인지 아닌지 검사하는 함수로 na값인지 아닌지를 bollean으로 출력한다. q2 q3 q4 q5 agecat [1,] FALSE FALSE FALSE FALSE FALSE [2,] FALSE FALSE FALSE FALSE FALSE [3,] FALSE FALSE FALSE FALSE FALSE [4,] FALSE FALSE TRUE TRUE FALSE [5,] FALSE FALSE FALSE FALSE FALSE > newdata <- na.omit(leadership) # na값을 버리고 데이터를 만든다. > newdata manager testDate gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 M 32 5 4 5 5 5 Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder
is함수와 as 함수 알아보기
간단히 설명하자면 is로 시작하는 함수는 무엇인가를 검사하는 함수고 as로 시작하는 함수는 변환을 시키는 함수이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16> a <- c(1,2,3) > a [1] 1 2 3 > is.numeric(a) [1] TRUE > is.vector(a) [1] TRUE > a <- as.character(a) # a를 숫자형 벡터에서 문자형 벡터로 변환함 > a [1] "1" "2" "3" > is.numeric(a) [1] FALSE > is.vector(a) [1] TRUE > is.character(a) [1] TRUE
데이터 프레임 정렬
1 2 3 4 5 6> newdata manager testDate gender age q1 q2 q3 q4 q5 agecat 1 1 10/24/08 M 32 5 4 5 5 5 Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder
아래와 같이 정렬을 시킬수 있는데 이해하는데 주의할 점은 값 자체를 정렬시키는 것이 아니라 보여주는 결과만 정렬하여 보여준다. 엑셀처럼 기존 데이터가 바뀌지 않고 보유줄때만 정렬이 바뀐다고 생각하면 된다. 그 증거가 index번호가 바뀌지 않는 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16> newdata <- leadership[order(leadership$age),] # 나이순으로 정렬을 시킴 > newdata manager testDate gender age q1 q2 q3 q4 q5 agecat 3 3 10/1/08 F 25 3 5 5 5 2 Young 1 1 10/24/08 M 32 5 4 5 5 5 Young 4 4 10/12/08 M 39 3 3 4 NA NA Young 2 2 10/28/08 F 45 3 5 2 5 5 Young 5 5 5/1/09 F 99 2 2 1 2 1 Elder > newdata <- leadership[order(leadership$gender, -leadership$age),] # 2가지 조건의 정렬을 파라미터로 순서대로 입력하면 된다. 내림차순은 -를 붙이면 딘다. > newdata manager testDate gender age q1 q2 q3 q4 q5 agecat 5 5 5/1/09 F 99 2 2 1 2 1 Elder 2 2 10/28/08 F 45 3 5 2 5 5 Young 3 3 10/1/08 F 25 3 5 5 5 2 Young 4 4 10/12/08 M 39 3 3 4 NA NA Young 1 1 10/24/08 M 32 5 4 5 5 5 Young
데이터프레임 예제객체 #3 : mtcars
R에는 내장되어 있거나 패키지 설치시 같이 설치되는 많은 샘플 데이터들이 존재한다. 그리고 이 데이터들은 대부분 데이터프레임 형식을 취하고 있다. 이중에서 차종별 정보를 담은 mtcars를 살펴보자.
R의 샘플데이터 정보
mtcars를 알아보기 전에 하나 소개하자면 R에서 기본 제공되는 예제 데이터 목록은 아래의 명령어로 알아 볼 수 있다.
1> data()
mtcars 정보
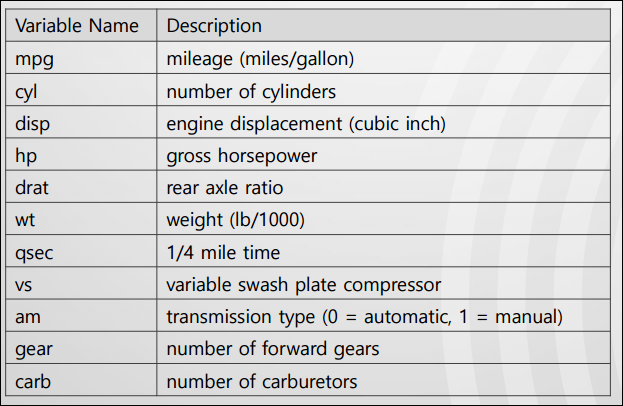
mtcars는 아래와 같은 도표의 정보를 담고 있다.
mtcars 커맨드 확인해 보기
R에서 아래와 같이 커맨드를 통해 확인해 볼 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34> mtcars mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4 Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3 Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3 Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3 Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4 Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4 Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4 Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1 Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1 Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1 Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2 AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2 Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4 Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2 Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2 Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6 Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8 Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
mtcars 관련 help 조회
mtcars에 대한 정보는 아래의 명령어로 조회해 볼 수 있다.
1> help(mtcars)
head 명령
데이터는 상위 n개만 확인 할 때는 head 명령어를 쓰면 된다.
1 2 3 4 5 6 7 8 9 10> head(mtcars, n=6) mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1 > class(mtcars) # 제공하는 데이터셋이 무엇인지 확인해보면 데이터프레임임을 알 수 있다. [1] "data.frame"
데이터프레임 전치(Transpose)
데이터 프레임의 일부를 행렬처럼 전치 시킬 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14> cars <- mtcars[1:5, 1:4] > cars mpg cyl disp hp Mazda RX4 21.0 6 160 110 Mazda RX4 Wag 21.0 6 160 110 Datsun 710 22.8 4 108 93 Hornet 4 Drive 21.4 6 258 110 Hornet Sportabout 18.7 8 360 175 > t(cars) # 행렬을 전치 시킨다. Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout mpg 21 21 22.8 21.4 18.7 cyl 6 6 4.0 6.0 8.0 disp 160 160 108.0 258.0 360.0 hp 110 110 93.0 110.0 175.0
Aggregate 함수
데이터프레임을 다룰 때 많이 쓰는 유용한 함수인 Aggregate를 알아보자.
문법은 x는 대상, by는 어떤것을 기준으로 그룹핑 할 것인지, FUN은 함수이다.
1aggregate(x, by, FUN)
실제로 예제를 보면 실린더와 기어값을 기준으로 그룹핑일 한 뒤 mtcars 데이터의 평균값을 계산한다. 주의할 점은 na값은 삭제하는데 mean함수에 대한 옵션이므로 평균을 구할 대상이 되는 데이터의 na값 삭제 여부를 의미한다.
명령어의 + 표시는 다음줄에서 이어서 명령어를 입력할때 나타나는 기호이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21> aggdata <- aggregate(mtcars, by=list(mtcars$cyl, mtcars$gear), + FUN=mean, na.rm=TRUE) > aggdata Group.1 Group.2 mpg cyl disp hp drat wt qsec vs 1 4 3 21.500 4 120.1000 97.0000 3.700000 2.465000 20.0100 1.0 2 6 3 19.750 6 241.5000 107.5000 2.920000 3.337500 19.8300 1.0 3 8 3 15.050 8 357.6167 194.1667 3.120833 4.104083 17.1425 0.0 4 4 4 26.925 4 102.6250 76.0000 4.110000 2.378125 19.6125 1.0 5 6 4 19.750 6 163.8000 116.5000 3.910000 3.093750 17.6700 0.5 6 4 5 28.200 4 107.7000 102.0000 4.100000 1.826500 16.8000 0.5 7 6 5 19.700 6 145.0000 175.0000 3.620000 2.770000 15.5000 0.0 8 8 5 15.400 8 326.0000 299.5000 3.880000 3.370000 14.5500 0.0 am gear carb 1 0.00 3 1.000000 2 0.00 3 1.000000 3 0.00 3 3.083333 4 0.75 4 1.500000 5 0.50 4 4.000000 6 1.00 5 2.000000 7 1.00 5 6.000000 8 1.00 5 6.000000
reshape 패키지
R에서 데이터프레임 조작 시 많이 사용하는 reshape 패키지를 설치, 사용하는 방법을 알아보자.
reshape 패키지 설치
아래와 같은 명령어로 reshape를 설치한다.
1> install.packages("reshape")
reshape 패키지 사용
reshape 라이브러리를 선택한다.
1> library(reshape)
Melt 함수
데이터 프레임을 다룰때 데이터 구조를 행의 키값을 기준으로 나머지를 변수화 하여 담아버리는 것을 melt 또는 melting한다고 표현한다. 한국어로 의역하자면 데이터를 입맛에 맞게끔 녹인다고 볼 수 있다.
예제 데이터 프레임 준비하기 : mydata
1 2 3 4 5 6 7 8 9 10 11> id <- c(1,1,2,2) > time <- c(1, 2, 1, 2) > x1 <- c(5, 3, 6, 2) > x2 <- c(6, 5, 1, 4) > mydata <- data.frame(id, time, x1, x2) > mydata id time x1 x2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4
melt 적용
mydata를 melt하여 x1, x2 칼럼으로 나타냈던 데이터셋을 variable, value 2개로 직렬화하였다. 키값은 id, time의 조합(combination)이 키값이고 기존의 x1, x2 칼럼은 변수화되어 key-value 형태로 저장된다.
melt의 장점은 칼럼이 얼마 없을때 보다 칼럼이 굉장히 많을때나 각 칼럼 값을 변수로 직렬화 하여 데이터를 조작할 때 편리하다.
1 2 3 4 5 6 7 8 9 10 11> md <- melt(mydata, id=(c("id", "time"))) > md id time variable value 1 1 1 x1 5 2 1 2 x1 3 3 2 1 x1 6 4 2 2 x1 2 5 1 1 x2 6 6 1 2 x2 5 7 2 1 x2 1 8 2 2 x2 4
Cast 함수
cast의 기본 문법은 아래와 같다.
md는 melt된 데이터, formular는 원하는 결과, FUN에는 적용할 함수를 선택한다.
1newdata <- cast(md, formula, FUN)
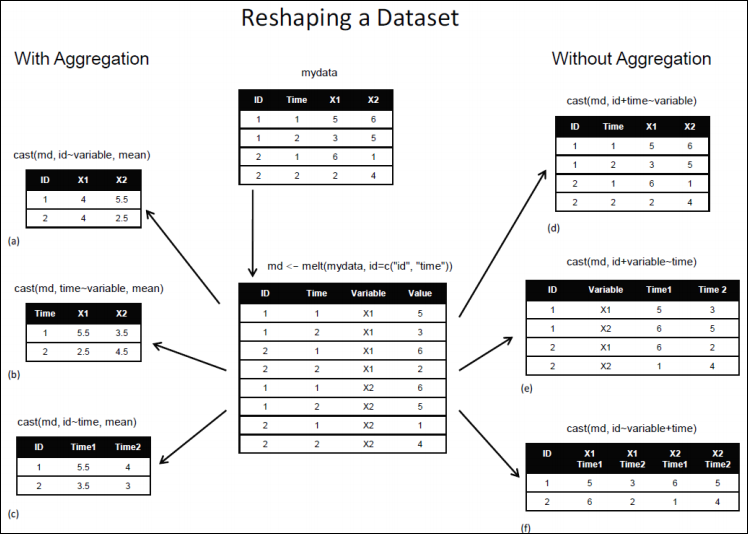
cast 함수 사용 도식
cast 함수는 아래의 그림이 이해가 훨씬 빠를것이다.
물결 표시 앞쪽은 행으로 사용할 값을 정하는데 여러개일때 +로 연결한다.
물결표시 뒤쪽은 열로 사용할 값을 정하고 여러개일때 마찬가지로 +로 연결한다.
FUN에 함수를 지정하면 왼쪽과 같이 평균값 들을 구할 수 있고,