일반로그 분석은 정말 쉬울까?(feat. Elasticsearch)

다음은 윈도우 웹로그 수집 및 정리를 위한 Logstash 설정.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32input { file { path => "d:/ex.log" type => "weblog" start_position => "beginning" #sincedb_path => "/dev/null" codec => plain { charset => "CP949" } } } filter { # '#'으로 시작하는, 로그 설명은 수집 안함 if [message] =~ "^#" { drop {} } # 로그 필드 정규화 grok { match => { "message" => "(?<timestamp>^.{19})\s\S+\s\S+\s(?<method>\S+)\s(?<w_path>\S*\/)(?<file>\S*)\s(?<var>\S+?)(\s|(\|.+\|)(?<error>\S+)\s)(?<dport>\S+)\s\S\s(?<sip>\S+)\s(?<agent>\S+)\s(?<status>\S+).+" } } # 'file' 필드에서 확장자를 별도 필드(ext)로 추출 grok { match => { "file" => ".+\.(?<ext>.+)" } } date { match => [ "timestamp", "yyyy-MM-dd HH:mm:ss" ] } geoip { source => "sip" } } output { elasticsearch { hosts => [ "localhost:9200" ] index => "logstash-weblog" } #stdout { codec => rubydebug } }
다음은 grok 필터에 사용된 정규표현식. 자세한 설명은 여기 참고.
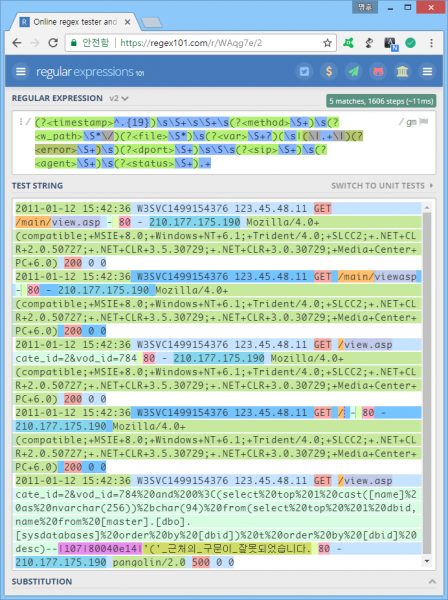
로그 수집 결과는 다음과 같다. 로그를 구성하는 여러 정보들이 일목요연하게 정규화됐음을 알 수 있다.
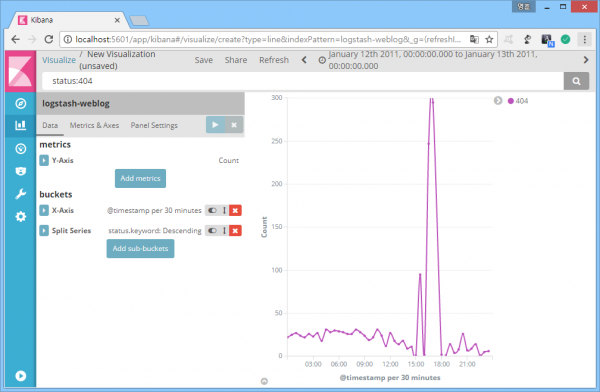
보안 관점에서 어떤 필드 상태의 숫자를 세면 될까? 예전 삽질을 떠올려보자. 그때 제일 먼저 분석을 시도했던 대상은 사용자의 요청에 대한 웹서버 응답코드 상태였다. 응답코드 필드는 'status'. 다음은 없는 페이지를 요청한 사용자에게 보내는 응답코드 404의 발생 추이.
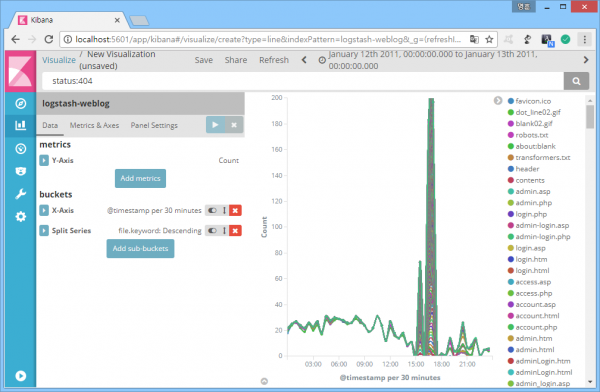
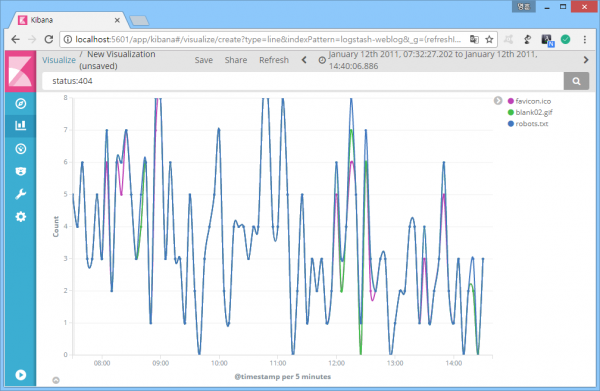
특정 시간대에 404 응답코드의 대량 발생이 확인됐다. 어떤 페이지에 접근하는 과정에서 발생했을까? 페이지 정보 필드는 'file'. 다음은 404 응답코드를 발생시킨 파일 발생 추이.
다음은 404 응답코드가 급증하기 전 발생 추이. 차이가 뚜렷하다.
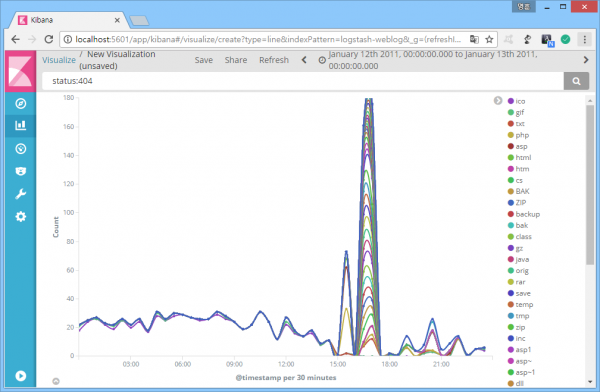
전체 현황 파악을 좀 더 쉽게 할 수 있는 방법은 없을까? '파일'에서 '파일 확장자'로 검사 범위를 넓히면 된다. 높이 올라갈수록 경치가 좋아지는 법. '파일 확장자' 필드는 'ext'이다. 다음은 404 응답코드를 발생시킨 파일 확장자 발생 추이.
다음은 404 응답코드가 급증하기 전 발생 추이.
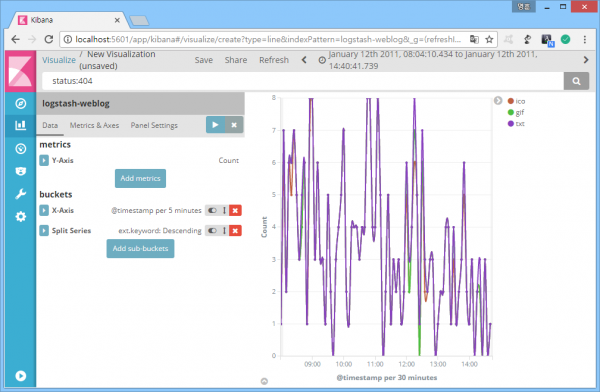
'BAK', 'backup' 등의 확장자를 갖는 파일은 개발 과정에서 남은 임시 파일일 가능성이 높으며, 정상 서비스 과정에서 사용자에게 제공될 가능성은 거의 없다. 웹서버 취약점 스캔 시도라는 얘기.
404 응답코드의 발생 추이, 그리고 해당 코드가 발생한 파일 확장자의 발생 추이 확인을 통해 이상징후 포착에 성공했다. 이 두가지 상태를 동시에 확인다면 분석 작업이 조금 더 편해질 것이다.
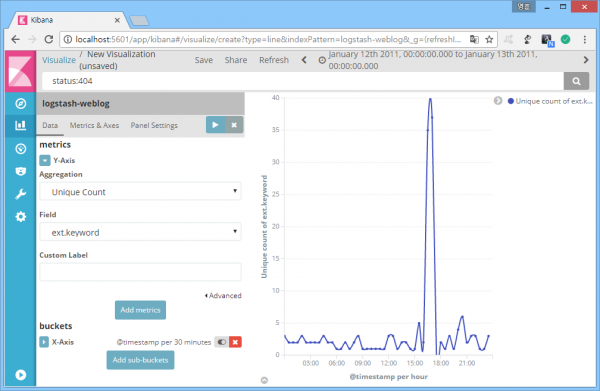
결론
일반로그의 이상징후 분석은 쉽다. 원하는 상태의 숫자만 세면 되니깐. 물론 그전에 로그의 구조와 의미를 정확하게 파악해야 한다는 전제조건이 필수임은 두말하면 잔소리.