파이썬으로 티스토리 백업 유틸리티 만들기

배경
티스토리를 사용한 지 10년이 넘다 보니 글도 제법 쌓였고, 백업도 한번 받고 싶은데, 백업 기능이 없다. (없었다.) 백업 기능을 만들어 달라고 문의도 해봤는데, 안 만들어준다. 구글링을 해보니 티스토리 백업 유틸리티가 제법 많이 나오기는 하는 데 사용하기가 조금 애매하던 차에 이번에 고등학교 로봇동아리 학생들을 대상으로 '개발자에 대한 궁금증'에 대한 강연을 할 일이 생겼는데, 길지 않은 코드로 동작하고 실제 용도가 있는 예제로 보여줄 겸 해서 티스토리가 제공하는 Open API로 간단히 구현해보기로 했다.
다 만들고 보니 백업 기능이 생겼네...? 티스토리 관리 메뉴에 '블로그 백업'이 생겼다. 사용해보니 압축 파일로 잘 백업해준다. 다만, 어떤 게시글은 파일명이 게시물 제목으로 잘 되어 있고, 어떤 게시글은 게시글 번호로 되어 있다.
기능 정의
내가 필요한 기능은 심플하다. 게시물의 정보를 게시물 당 하나의 파일로 다운로드하고, 내가 해당 게시물에 올렸던 이미지를 같은 게시물 제목과 같은 네이밍으로 다운로드하는 것이다. 나중에 게시물의 텍스트만 필요하다면 받아 놓은 파일에서 파싱하는 유틸리티를 그때 만들면 될 테니, 지금은 이것으로 족하다.
만들어보자.
이 글과 코드에서 Open API를 Python으로 어떻게 사용하는지 확인해 볼 수 있을 것이다. 이 글에서 등장하는 {}는 작업자가 채워야 하는 변수 위치를 뜻한다. 예를 들어서 본인의 App ID가 'abc123'이라고 할 때, client_id={App ID}는 client_id=abc123으로 치환되어야 한다는 것을 뜻한다.
이 글에서 설명하는 TISTORY Open API를 사용하여 Python으로 구현한 간단한 백업 유틸리티의 전체 코드는 github에 있다.
외부 모듈은 requests만 사용했고, 사용한 모듈의 설치 관련 설명은 하지 않는다. 여기를 참고 바란다.
코드가 단순하고 간략해서 코드의 부연 설명은 하지 않지만, 코드의 블록에서 사용한 기능에 대한 문서 링크를 주석으로 명시했다.
티스토리 Open API 사용을 위한 앱 등록
TISTORY Open API를 사용하려면 아래의 앱 등록 과정과 Access Token 발급 과정을 거쳐야 한다.
앱 등록 URL : https://www.tistory.com/guide/api/manage/register
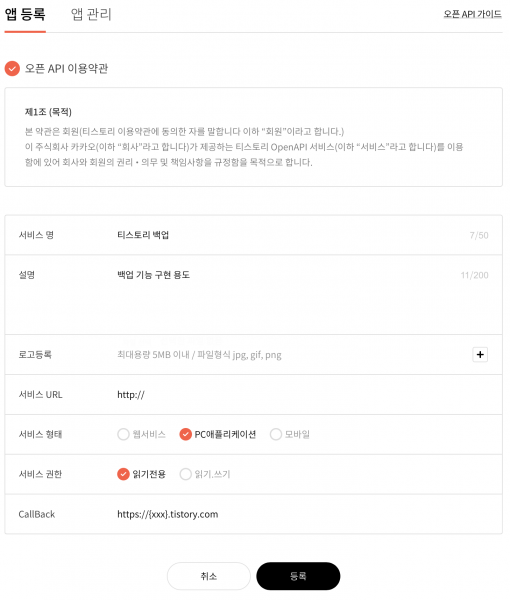
커멘드 형태로 단발성으로 사용할 것이므로 위와 같이 서비스 형태는 pc로 설정하고, CallBack 항목의 {xxx}는 각자 본인의 티스토리 URL xxx.tistory.com에서 xxx 부분으로 치환해서 등록한다. 서비스 URL은 생략해도 된다.
앱 등록 후 '앱 관리' 탭에서 등록된 내용을 확인한다.
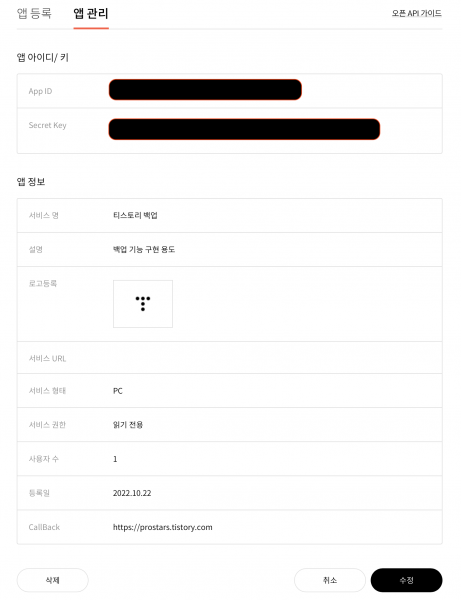
등록 후 발급된 App ID, Secret Key 확인한다.
참고로 CallBack에 등록된 https://prostars.tistory.com 은 필자의 블로그 URL이다. 각자 자신의 티스토리 블로그 URL로 앱 등록을 해야 한다.
인증 요청 및 Authentication code 발급
티스토리 Open API Authentication Code 방식 : https://tistory.github.io/document-tistory-apis/auth/authorization_code.html
브라우저에서 티스토리에 로그인한 상태에서 새로운 탭을 열고, 아래의 형식으로 URL을 구성하고 {App ID}는 앱 등록 후 발급된 App ID로 치환하고, {CallBack}은 각자 자신의 티스토리 블로그 URL로 치환하고, 웹 페이지에 접근한다.
1https://www.tistory.com/oauth/authorize?client_id={App ID}&redirect_uri={CallBack}&response_type=code&state=SomeValue
위의 URL에서 App ID, CallBack 위치에 치환한 값이 모두 유효하다면, 아래와 같은 페이지로 리다이렉션 된다.
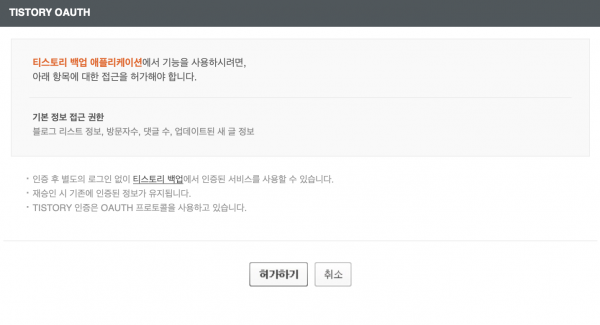
'티스토리 백업 애플리케이션'이라고 명시된 이유는 위에서 앱 등록을 할 때 '서비스명'으로 '티스토리 백업'이라고 설정했기 때문이다.
'허가하기'를 클릭하면 아래와 같은 URL로 다시 리다이렉션 된다.
1{CallBack}?code={Authorization Code}&state=SomeValue
리다이렉션 된 URL에서 {Authorization Code} 부분의 값이 Authorization Code로 Access Token을 발급받는데 필요하다. 문서에 명시되어 있듯이 Authorization Code는 1시간 이내에만 사용할 수 있으며 재사용할 수 없다.
Access Token 발급
이제부터 curl을 사용한다. 아래와 같은 get 요청으로 Access Token을 발급받는다. {App ID}는 앱 등록 후 발급된 App ID로 치환하고, {Secret Key}는 앱 관리 페이지의 Secret Key로 치환하고, {CallBack}은 각자 자신의 티스토리 블로그 URL로 치환하고, {Authorization Code}는 위에서 발급받은 Authorization Code로 치환한다.
1curl "https://www.tistory.com/oauth/access_token?client_id={App ID}&client_secret={Secret Key}&redirect_uri={CallBack}&code={Authorization Code}&grant_type=authorization_code"
요청에 성공하면, 아래와 같은 값을 응답으로 받는다.
1access_token={Access Token}
Access Token을 발급받았다면, 이제 각자 자신의 티스토리 블로그에 대해서 티스토리 Oepn Api를 사용할 수 있다.
아래와 같이 블로그 정보를 조회할 수 있다.
블로그 정보
블로그 정보 API : https://tistory.github.io/document-tistory-apis/apis/v1/blog/list.html
백업 유틸리티에서 사용하지는 않을 API지만, 가장 단순하니 블로그 정보 API로 테스트해 보자.
아래와 같은 get 요청으로 블로그 정보를 조회한다. {Access Token}은 위에서 발급받은 Access Token으로 치환한다. ouput에는 json 또는 xml을 설정하여 응답 형식을 지정할 수 있는데, 이 글에서는 계속 json 형식을 사용한다.
1curl "https://www.tistory.com/apis/blog/info?access_token={Access Token}&output=json"
조회에 성공하면 {"tistory":{"status":"200","item":{"id":...} 형식의 응답을 받을 수 있다.
글 목록 구하기
글 목록 API : https://tistory.github.io/document-tistory-apis/apis/v1/post/list.html
이제 백업 유틸리티에서 직접 사용할 API 2개 중에서 첫 번째로 글 목록 구하기를 테스트해 보자.
아래와 같은 get 요청으로 글 목록을 조회한다. {Access Token}은 위에서 발급받은 Access Token으로 치환하고, {Blog Name}은 각자 본인의 티스토리 블로그 주소 xxx.tistory.com에서 xxx로 치환한다. page는 1로 설정했다.
1curl "https://www.tistory.com/apis/post/list?access_token={Access Token}&output=json&blogName={Blog Name}&page=1"
조회에 성공하면 조회에 성공하면 {"tistory":{"status":"200","item":{"url":...} 형식의 응답을 받을 수 있다.
마지막 페이지 번호 구하기
전체 페이지 카운트는 별도로 제공되지 않으니 계산해야 한다. 글 목록 구하기 요청으로 받은 응답에서 tistory/item/totalCount에 전체 글 개수, tistory/item/count에 요청한 페이지가 가진 글 개수가 들어있고, totalCount / count 에서 나머지가 있다면 totalCount / count 몫에 1을 더한 값이, 나머지가 없다면 그냥 몫이 마지막 페이지 번호를 의미한다.
글 읽기
글 읽기 API : https://tistory.github.io/document-tistory-apis/apis/v1/post/read.html
위의 글 목록 요청으로 받은 응답에서 tistory/item/posts 배열의 크기는 tistory/item/count가 가진 값과 같다.
예를 들어서 위의 page=1 요청의 응답에서 tistory/item/count 가 10이라면 첫 번째 페이지의 첫 Post ID는 tistory/item/posts[0]/id에 들어있다.
아래와 같이 get 요청으로 게시글의 정보를 조회한다. {Access Token}은 위에서 발급받은 Access Token으로 치환하고, {Blog Name}은 각자 본인의 티스토리 블로그 주소 xxx.tistory.com에서 xxx로 치환하고, {Post ID}는 tistory/item/posts에서 첫 번째 id 값으로 치환한다.
1curl "https://www.tistory.com/apis/post/read?access_token={Access Token}&output=json&blogName={Blog Name}&postId={Post ID}"
조회에 성공하면 {"tistory":{"status":"200","item":{"url":...} 형식의 응답을 받을 수 있다.
코드 구성
코드의 블록에서 사용한 기능에 대한 문서 링크를 주석으로 명시해두었다. 코드가 단순하고 간략해서 코드의 세부 설명은 하지 않는다. 전체 코드는 위에서 언급한 것처럼 git에 있다.
tistory_apis.py 파일에는 글 목록 구하기 API와 글 읽기 API에 필요한 파라미터를 각각 클래스로 묶어두었다.
backup_tistory.py 파일에 실제 Open API를 사용해서 정보를 조회하고 받은 결과를 파일로 저장하는 로직이 있다.
argparse를 사용해서 커맨드 라인 옵션을 처리한다.
아무런 옵션 없이 실행하면 다음과 같이 출력된다.
1 2 3$ python backup_tistory.py usage: backup_tistory.py [-h] -t ACCESS_TOKEN -n BLOG_NAME [-f {title,id}] backup_tistory.py: error: the following arguments are required: -t/--access_token, -n/--blog_name
-h 옵션을 사용하면, 도움말이 출력된다.
1 2 3 4 5 6 7$ python backup_tistory.py -h usage: backup_tistory.py [-h] -t ACCESS_TOKEN -n BLOG_NAME [-f {title,id}] optional arguments: -h, --help show this help message and exit -t ACCESS_TOKEN, --access_token ACCESS_TOKEN -n BLOG_NAME, --blog_name BLOG_NAME -f {title,id}, --filename_type {title,id}
아래의 커맨드 라인 옵션에서 {Access Token}은 위에서 발급받은 Access Token으로 치환하고, {Blog Name}은 각자 본인의 티스토리 블로그 주소 xxx.tistory.com에서 xxx로 치환하고 실행하면, 각자 자신의 블로그 게시글 전체 백업이 실행된다.
1 2 3 4 5 6 7 8 9 10$ python backup_tistory.py -t {Access Token} -n {Blog Name} downloaded(1/308) post to posts/그런 깨달음은 없다.json downloaded(2/308) post to posts/안드로이드 뜻밖의 역사.json downloaded(3/308) post to posts/고차 함수로 의존성 줄이기.json ... downloaded(87/308) post to posts/IntelliJ 의 JShell Console 을 활용하자.json downloaded images/IntelliJ 의 JShell Console 을 활용하자_0.png downloaded images/IntelliJ 의 JShell Console 을 활용하자_1.png downloaded images/IntelliJ 의 JShell Console 을 활용하자_2.png ...
curl로 테스트했던 Open API를 파이썬에서 사용할 때는 requests 모듈의 get() 함수를 사용한다.
1 2 3 4 5 6 7 8 9params_for_post_list = tistory_apis.ParamsForPostList(access_token=ACCESS_TOKEN, blog_name=BLOG_NAME, output=OUTPUT_TYPE, page=1) response = requests.get(url=tistory_apis.BLOG_POST_LIST, params=params_for_post_list.get_params()) json_result = response.json() COUNT = int(json_result['tistory']['item']['count']) TOTAL_COUNT = int(json_result['tistory']['item']['totalCount']) END_PAGE = TOTAL_COUNT // COUNT + 1
위의 코드는 첫 번째 페이지의 글 목록을 조회하고 받은 응답 중에서 페이지 정보를 사용하여 마지막 페이지를 구하고 있다.
그다음 코드 블록인 아래의 코드는 전제 글의 Post ID를 total_post_ids에 모은다.
1 2 3 4 5 6 7total_post_ids = [] for page in range(1, END_PAGE + 1): params_for_post_list.page = page response = requests.get(url=tistory_apis.BLOG_POST_LIST, params=params_for_post_list.get_params()) json_result = response.json() post_ids = [item['id'] for item in json_result['tistory']['item']['posts']] total_post_ids += post_ids
게시글에 포함된 이미지 파일의 URL을 추출하기 위해서 HTML 라이브러리를 사용해서 파싱하지 않고, 단순하게 처리하기 위해 아래와 같이 정규식을 사용해서 문자열에서 직접 추출한다. 정규식에 관해 설명은 하지 않는다. 관련 자료의 링크는 코드에 주석으로 달아두었다.
1 2 3 4REX_URL = re.compile(pattern="img src=[\"'](http.*?)[\"']") REPLACE_TABLE = { '/': '_' }
위의 코드에서 REPLACE_TABLE은 파일명에 사용할 수 없는 문자가 게시글 제목으로 사용되었을 때 해당 문자를 다른 문자로 치환하도록 설정하는 치환 테이블이다. 등록된 '/'는 MacOS에서 파일명에 사용할 수 없는 문자인데, 필자의 블로그 게시글 중 몇 개가 글 제목에 '/'를 포함하고 있어서 '/'를 '_'로 치환하도록 등록했다.
위에서 모아둔 total_post_ids에 들어있는 Post ID를 글 읽기 API에 적용해서 모든 게시글을 각각 조회하면서 파일로 저장한다. 이때, 게시글에 포함된 이미지가 있는지 정규식으로 확인하고 있다면, 이미지를 다운로드한다.
1 2 3 4 5 6 7 8 9 10 11 12 13content = json_result['tistory']['item']['content'] image_url_list = REX_URL.findall(content) for idx in range(len(image_url_list)): image_file_name = f"{post_file_name}_{idx}" try: urllib.request.urlretrieve(url=image_url_list[idx], filename=f"images/{image_file_name}") file_ext = imghdr.what(f"images/{image_file_name}") os.rename(f"images/{image_file_name}", f"images/{image_file_name}.{file_ext}") print(f"downloaded images/{image_file_name}.{file_ext}") except: downloaded_failed_list.append((post_file_name, image_url_list[idx])) for post_file_name, image_url in downloaded_failed_list: print(f"image download failed : {post_file_name} - {image_url}")
위의 코드에서 imghdr.what()를 사용해서 이미지 파일의 확장자를 추출하고, 저장할 때 명시적으로 붙이는 이유는 티스토리에서 어떤 이유에선가 게시글에 포함된 이미지 파일명에서 파일 확장자를 삭제하고 URL을 구성한 케이스가 있기 때문이다. 그리고, 어떤 이유로든 이미지 다운로드에 실패하면 예외 처리하고 실패한 목록을 나중에 출력하기 위해 수집한다. total_post_ids의 모든 Post ID에 대한 백업이 끝나면 수집했던 이미지 다운로드 실패 목록을 모두 출력하고 종료한다.
예상보다 글이 많이 길어졌는데, 조금이나마 도움이 되었기를 바란다.
(원글 : https://prostars.net/331)