보안과 빅데이터

전에 빅데이터가 네트워크 보안 분야에는 별로 도움이 안 된다는 얘기를 했었는데, 그 이유를 알아보자. 다음은 엘라스틱서치로 구현한 Snort 로그 대시보드. 전세계에서 다양한 공격(?)이 시도되고 있음을 보여준다. 뭔가 있어 보이고, 보안이 통합 관리되는 듯한 느낌은 덤.
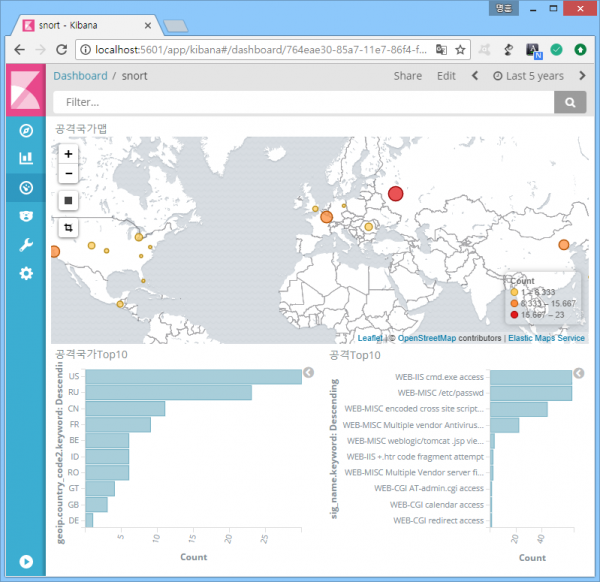
그런데 그 느낌을 과연 믿어도 되는 걸까? 사실 해당 로그가 전부 진짜 공격이라면 이런 대시보드를 보고 있을 필요가 없다. 로그가 발생하는 족족 차단해버리면 그만. 하지만 현실에서는 로그가 발생할 때마다 그 내용을 열람하는 과정이 반드시 뒤따라야 한다. 왜 그래야 할까? 다음은 'cmd.exe'란 문자열이 존재하는 웹요청 트래픽을 탐지하는 snort 룰.
alert tcp any any -> any 80 (msg:"WEB-IIS cmd.exe access"; content:"cmd.exe"; http_uri; sid:1002;)
해당 룰의 탐지 결과는 다음과 같다.
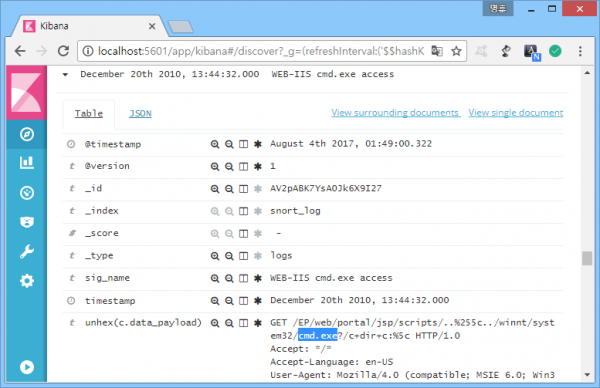
정탐
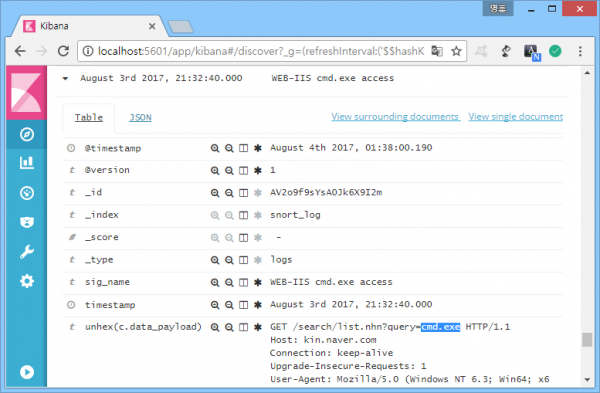
오탐
첫 번째 그림은 웹서버의 시스템 명령어 접근을 시도하는 공격, 두 번째는 'cmd.exe'란 문자열이 단순히 검색어로 사용된 경우. 로그를 까보지 않으면 아무런 의미도 부여할 수 없는 보안장비의 특징을 잘 보여준다. 부정확한 룰의 극단적 사례로 보이지만 의외로 보안관제 현장에서 가장 흔한 사례.
왜 이런 상황이 발생할까?
많은 이유가 있겠지만 일단 제조사들은 공격 패턴과 조금이라도 비슷하면 탐지하게끔 룰을 셋팅하려는 경향을 가지고 있다. 미탐, 즉 공격을 탐지하지 못했다는 고객 클레임이 발생하면 매우 피곤해지기 때문.
룰 정확도가 낮아지는 두 번째 이유는 장비가 어떤 환경에서 쓰일지 모르기 때문이다. 최종 검사할 트래픽의 특성을 모르는 상태에서 미탐을 방지하려면, 최대한 넓은 범위를 검사해야 하기 때문에, 결국 최대한 단순하고 범용적인 패턴을 사용할 수 밖에.
문제는 그런 셋팅 덕에 미탐 가능성은 줄겠지만, 반대로 오탐 가능성은 커진다는 것이다. 공격을 탐지해도 오탐 홍수에 묻히기 쉽다는 뜻. 결국 패턴매칭을 효과적으로 사용하는 방법은 검사 대상 트래픽의 특성이 반영된 룰 커스터마이징뿐이다.
해당 룰을 예로 들면, 소개된 로그만을 근거로 했을 때, 'cmd.exe' 이후 'dir'이란 문자열이 이어지는 트래픽만을 탐지하도록 수정하는 식.
alert tcp any any -> any 80 (msg:"WEB-IIS cmd.exe access"; content:"cmd.exe"; http_uri; content:"dir"; distance:0; sid:1002;)
하지만 이런 문제점은 기술 종주국인 미국에서조차 좀처럼 공론화되지 않고 있다. 나는 그 이유가 1차적으로 SIEM(Security Information and Event Management)의 성급한 대중화에 있다고 본다.
"(IDS 등) 기존 보안솔루션이 정상화되어야만 이들의 정보를 취합하는 ESM이 정상화될 수 있음에도, 정보를 화려하게 통합해주는 ESM에 사용자들이 매료되면서 정작 ESM에 정보를 제공해주는 보안솔루션의 정확도에 관한 관심이 사라져버린 것이다. 만약 ESM이 없었다면 IDS, IPS, 웹방화벽 등의 보안솔루션 벤더들은 지금보다 더 거센 사용자의 개선 요구를 받게 되었을 것이다." - IDS와 보안관제의 완성 (452페이지)
SIEM으로 시작하더니 ESM(Enterprise Security Management)은 또 뭘까? 그냥 같은 말이다. 포장지가 달라졌다고 보면 됨. SIEM의 유래는 1980년대에 등장한 NMS(Network Management System). NMS의 목적은 시스템의 상태 확인. 시스템이 죽었나, 살았나 또는 자원 사용량 등의 정보를 모아서 보여주는 것이 NMS의 목적이다.
 NMS 대시보드
NMS 대시보드이때 시스템의 업/다운, 자원 사용량 등의 정보는 명백한 사실, 즉 의심할 필요가 없는 정보라는 사실에 주목할 필요가 있다. 정보 발생 자체에 의미가 있기 때문에, 결과적으로 대시보드만 보고 있어도 전체 현황을 파악할 수 있다는 얘기. 그러나 이미 확인했듯이, 1990년대 후반에 등장한 IDS 등의 패턴매칭 보안장비는 로그의 내용 열람을 통해 실제 공격 여부를 확인해야만 의미를 부여할 수 있다.
성격이 전혀 다른 NMS
그런데 이런 개념의 차이가 잘 알려지지 않고 있다. 성격이 전혀 다른 NMS의 개념이 보안 분야로 전해지는 바람에 문제점이 드러나지 않고 있는 것이다. 그러나 문제점이 드러나지 않았다고 해서 문제를 모르는 것은 아니다. 2009년, 전 안랩 CEO 김홍선씨는 이런 얘기를 했다.
CEO급에서 이런 식견을 보였다는 것은, 사실상 업계 관계자라면 다 알고 있는 문제라는 얘기. 그런데 왜 개선이 안 될까? 이것 역시 이런저런 이유가 있겠지만, 가장 큰 이유는 사용자의 니즈가 크지 않아서가 아닐까 싶다. 물론 이때 사용자는 주로 윗분들(..) 그렇다고 그분들 잘못이라고 할 수도 없다. 잘못 꿴 첫단추 때문에 발생한 문제. 그리고 이제는 그 상황에 익숙해져버린 게 문제.

해법은?
방법은 패턴매칭 로그와 일반로그 분석을 분리, 병행하는 것이다. ('보안관제와 빅데이터의 접목'에서 이미 다 한 얘기. 어쩌다 보니 재활용이 자꾸 느네요. ^^;)
먼저 패턴매칭
투표 결과를 알고 싶을 때 제일 먼저 할 일은 투표 한 사람과 안 한 사람을 구분하는 것이다. 정확성을 보장할 수 없는 패턴매칭 로그 가지고 통계니, 관계 분석이니 힘 빼지 말자는 얘기. 다음은 힘만 빠지게 만드는 사례.

- 보안로그끼리의 상관분을 통해서 보안로그의 정확도를 높이겠다는 것. 그런데 패턴매칭 정확도가 보장이 된다면 상관분석이 필요 없음. 왜? 정확하니깐.
- 반대로 정확도 보장이 안 된다면 오탐끼리 상관분석을 하게 됨. 영원히 빠져나올 수 없는 닭과 달걀의 딜레마에 빠짐.

- 공격 로그가 발생했을 때 피해 시스템에서 에러 로그가 발생하면 공격이라는 식의, 보안/일반로그 간 상관분석. 이게 성공하려면 공격일 때만 에러 로그가 발생한다는 전제가 필요.
- 그러나 (보안로그의 오탐 가능성은 무시하고라도) 에러로그는 공격이 아닐 때도 얼마든지 발생. 확실한 기준이 없음.
패턴매칭 로그는 그저 정확도를 높이는 데만 집중하면 만사형통.
그리고 일반로그
시스템, 웹 등의 일반로그는 쉽다. 발생 사실이 그대로 기록된, 의심할 필요가 없는 로그이기 때문에 원하는 상태의 숫자만 세면 된다. 다음은 몇 가지 예시.
예시는 노가다로 시작해서 노가다로 끝나지만 빅데이터로 무장한 SIEM을 이용한다면 수월하지 않을까? 이런 시도들이 늘어나면서 쌓인 데이터와 경험은 보안 알파고의 밑거름이 되어 줄테고. 결국 패턴매칭 로그와 일반로그에 대한 분석 병행, 그리고 상호보완이 가능한 체계를 구축해야 한다. 그게 안 되면 '알려진 공격'과 '알려지지 않은 공격'이라는 두 마리 토끼는 영영(..)


그런데 누가 하나?
보통 시스템이 늘어나고, 업무가 늘어나도 사람은 잘 안 늘어난다. 사람은 그대론데 일이 늘면 역량은 자연스럽게 분산되기 마련. 이것도 적당히, 저것도 적당히가 되기 십상이란 얘기.
 일이 늘어도 다 하게 돼 있다. 내용이 좀 부실해질 뿐
일이 늘어도 다 하게 돼 있다. 내용이 좀 부실해질 뿐이런 사태를 막기 위해 필요한 건 전담 인력과 조직. 이왕 재활용하는 거 마지막으로 한 번 더.
"빅데이터 분석이 성공하기 위해서는 패턴매칭을 이용하는 전통적 보안관제와 빅데이터를 이용한 보안관제가 병행과 상호보완이 가능한 체계를 구축해야 하며, 그러기 위해서는 전담 인력과 조직이 반드시 필요하다. 사실 나는 기회가 있을 때마다 빅데이터에 대한 부정적인 의견을 피력했었던, 빅데이터 회의론자다. 하지만 그럼에도 많은 정보보안 현장에 빅데이터가 구현되기를 희망한다. 솔루션과 데이터는 많을수록 좋다. 감당할 수 있는 인력과 조직만 있다면."
다음은 Snort 데이터베이스를 엘라스틱서치로 연동해주는 Logstash 설정. 패턴매칭 로그 대시보드를 아무리 잘 꾸며봐야 별 의미는 없지만, 그래도 윗분들이 좋아하시니깐. 예쁘게 꾸며진 대시보드를 바라보고 있으면 왠지 일 다 한 것 같은 기분도 들고(..)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37input { #데이터베이스 연동을 위한 jdbc 플러그인 jdbc { jdbc_driver_library => "C:\ELK\mysql-connector-java-5.1.42\mysql-connector-java-5.1.42-bin.jar" jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_connection_string => "jdbc:mysql://localhost/snort" jdbc_user => "user" jdbc_password => "password" #로그 중복 전송을 막기 위한 기준 필드(tracking_column)로 timestamp가 아닌 필드 사용 use_column_value => true #tracking_column으로 로그 일련번호 필드 지정 tracking_column => cid #데이터 타입 지정 tracking_column_type => "numeric" #마지막으로 읽은 로그 무시, 같은 로그로 반복 테스트할 때 필수 clean_run => true #1분 단위 실행(분, 시, 일, 월, 요일) schedule => "* * * * *" #실행 쿼리문 statement => "select a.cid, a.timestamp, b.sig_name, inet_ntoa(c.ip_src), inet_ntoa(c.ip_dst), unhex(d.data_payload) from event a, signature b, iphdr c, data d where date_format(a.timestamp, '%Y') = '2010' and a.signature = b.sig_id and a.sid = c.sid and a.cid = c.cid and a.sid = d.sid and a.cid = d.cid and a.cid > :sql_last_value" } } filter { #출발지 IP에 지리 정보 매핑 geoip { source => "inet_ntoa(c.ip_src)" } } output { elasticsearch { hosts => "localhost:9200" #지도 위치를 표시해주는 'geoip.location' 필드 타입이 'geo_point'인 기본 매핑을 사용하기 위해 'logstash'로 시작하는 인덱스명 사용. #'logstash'를 붙이지 않으면 'geoip.location' 필드 타입이 숫자로 바뀌면서 지도 표시가 안 되기 때문에 별도로 매핑을 만들어줘야 함. index => "logstash-snort_log" } stdout { codec => rubydebug } }
참고로 데이터베이스 연동을 안 하는 Snort는 경보와 패킷 페이로드를 따로 저장하는데, 두 개의 로그를 하나로 합쳐서 엘라스틱서치로 연동하는 방법은 모르겠다. ㅡㅡ^