이번에 정리하고자 하는 내용은 Akka stream을 사용할 때 message 손실의 위험을 줄일 수 있는 방법입니다. 그럼, Akka에 대해 먼저 간략히 정리해보도록 하겠습니다. Akka에 대해서는 다른 많은 블로그와 다양한 자료에서 익히 설명하고 있으므로, 간단히 개념만 훑어본 후 실제로 Akka stream을 활용하는 방법을 집중적으로 설명하겠습니다.
Akka
Akka는 Actor 를 근간으로 하는 high level의 application framework입니다. 주로 concurrent programming을 위해 사용되며, supervisor hierarchy를 통해 fault tolerant하게 원하는 개발을 할 수 있습니다. 'Fault tolerant'란, 시스템 동작 도중 발생하는 에러 등 예외적인 상황이 발생했을 때, 문제의 상황을 통제하여 스스로 직접 복구 또는 해결할 수 있는 구조를 갖추었다는 의미로 해석할 수 있습니다.
Actor
Actor 는 아래와 같은 특징을 가지고 있습니다.
- 간단한 추상화를 통해 distribution, concurrency, parallelism 을 위한 layer 를 제공
- Asynchronous, non-blocking 으로 구현되어진 높은 성능의 message driven 개발 모델을 제공
- Lighweight 한 event driven 으로 동작(1GB 의 메모리 위에서 수 백만의 actor 들이 동작 가능)
Akka와 Actor의 구현에 대해서는 훨씬 더 많은 설명이 필요하므로, 자세한 것은 다른 자료들을 참고해주시기 바랍니다. [
What is Akka?]
구현 하고자 하는 시스템
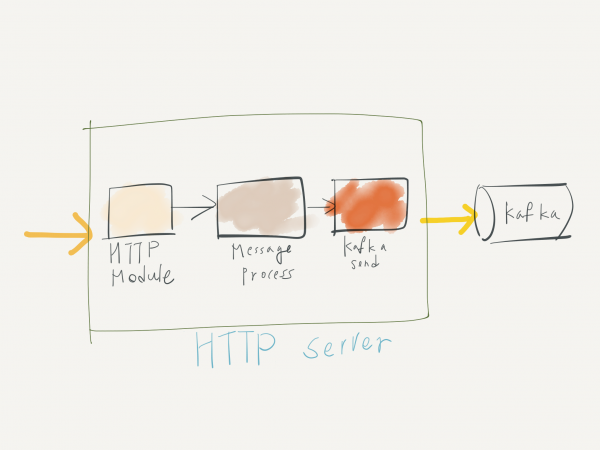
이 글의 작성 목적은 외부 또는 내부에서 생성되는 event, web log, application log 등의 데이터 수집을 원활하게 하기 위해서였습니다. 아래는 간략한 구성도입니다.
수집된 데이터를 전달받을 대상은, 최근 대용량 데이터 전송에 주로 사용되고 있는 distributed queue인 Apache Kafka입니다. 위에서 언급한 데이터를 전송하는 가장 쉬운 방법은 실제 데이터를 생산하는 주체, 또는 1차 수집 주체가 Kafka의 특정 Topic으로 바로 전송하는 것입니다. 이 경우 Kafka만이 관리의 대상이 되므로, 데이터를 수집하는 입장에서는 굉장히 편리한 선택일 수 있습니다.
Kafka direct 사용시 단점
하지만, 실제로 데이터를 수집하고 송신해야 하는 end client에게는 데이터 전송을 위해 Kafka의 client library dependency를 추가해야 하는 등 추가 작업이 발생하게 됩니다. 물론, end client에게는 데이터를 다음 단계로 안전하게 전달할 의무가 있습니다. 그렇다 하더라도 자신에게 익숙한 Protocol이 아닌 다른 수단을 활용해야 하는 것이 부담스러울 수 있습니다. 이러한 부담을 줄이기 위해 데이터를 수신하는 Gateway 역할의 Web application layer를 두고, 이 application이 Kafka로의 데이터 전송을 책임지도록 하는 방법을 적용하게 되었습니다.
단점 해결 방향
Gateway의 역할을 하는 web application은 일반적인 클라이언트들이 사용하는 HTTP protocol을 사용하는 것이 가장 적은 비용이 들 것이라고 판단했습니다. 이 Gateway에게는 이미 언급했듯이 클라이언트로부터 수신한 다양한 데이터를 Kafka로 안전하게 전달할 의무가 있으며, 또한 높은 성능 (low latency, high throughput, reliability, etc.)을 보장해야 할 의무도 있습니다. 이러한 web application이 제공해야 하는 기능에 가장 부합하는 것이 Akka 였고, 더불어 데이터의 흐름을 안정적으로 처리하기 위해 Akka stream을 활용하게 된 것입니다.
Akka stream 기본
Akka stream은 위에서 간략히 설명한 Akka의 특징을 기반으로 message를 안정적으로 처리하고 전달할 수 있도록 설계 및 구현되어 있습니다. <예제 1 - Akka stream 기본 예제> 아주 기본적인 Akka stream의 예시입니다. 아래 코드는 0부터 100까지의 Source data가 factorial을 계산하는 로직을 통해 특정한 파일에 write 되는 과정을 보여주고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import akka.stream._
import akka.stream.scaladsl._
import akka.NotUsed
import akka.actor.ActorSystem
import akka.util.ByteString
import scala.concurrent._
import java.nio.file.Paths
object Example {
/**
* Create actor system with name, "QuickStart"
*/
implicit val system = ActorSystem("QuickStart")
/**
* Stream 이 동작하도록 하는 Stream Execution Engine 의 factory 로
* Materializer 로 생성된 Engine 은 실제 stream 이 수행되도록 해주는 핵심입니다.
*/
implicit val materializer = ActorMaterializer()
/**
* Source 의 첫 번째 type Int 는 Source 가 emit 하게 될 data 의 type 을 의미합니다.
* 두 번째 type NotUsed 는 Source 가 부가적인 데이터를 의미합니다.
* 여기에선 1 ~ 100 의 Int 이외에 추가적인 데이터가 없으므로 NotUsed 를 사용하였습니다.
*/
val source: Source[Int, NotUsed] = Source(1 to 100)
/**
* 생성된 Source 아래 runForeach 로 실제 Source 에 대한 검증을 해볼 수 있습니다.
* Source 를 검증할 때, 위에서 생성한 amterializer 가 implicit 하게 사용됩니다.
*/
source.runForeach( i => println(_) )
/**
* 1 이라는 숫자로 factorial 계산을 시작해서 source 에서 emit 되는 1 에서 100 의 숫자를
* scan 하며 factorial 값을 만들어내는 과정을 나타내는 Source 를 만들어 냅니다.
*/
val factorials: Source[BigInt, NotUsed] = source.scan(BitInt(1))((acc, next) => acc * next)
// Sink 를 FileIO 로 선택하여 넘어온 값들이 저장될 수 있도록 처리
val fileSink = FileIO.toPath(Paths.get("factorials.txt")
val result: Future[IOResult] =
factorials
.map(num => ByteString(s"$num\n")) // factorials(Source) 에서 생성된 int stream 데이터를 ByteString 형태로 변환
.runWith(fileSink) // runWith 를 통해서 위에서 정의된 Flow 를 실제 실행해준다.
}
<예제 1 - Akka stream 기본>의 코드는 데이터의 흐름을 직관적으로 표현하고 있습니다. Source -> Processing -> Sink(write) 과정을 먼저 정의한 후, 정의한 flow를 실행시키는 형태입니다. Akka stream의 강점은 이와 같이 구성하고자 하는 대로 Stream을 옮길 수 있다는 점이라고 생각합니다. 이러한 강점은 Akka stream을 처음 접하는 개발자도 큰 어려움 없이 high level api를 사용할 수 있게 합니다. 위의 예제에서 사용된 Source와 Sink는 재사용 가능한 형태로 정의할 수 있습니다. 아래 코드를 보면, 위의 코드에서 File의 factorials (Source)를 통해 들어오는 Message stream이 File에 저장될 때, 이 부분을 다시 사용할 수 있도록 Sink로 정의합니다. 아래 예제를 확인해보세요.
1
2
3
4
5
def lineSink(fileName: Stirng): Sink[BigInt, Future[IOResult]] =
Flow[BigInt]
.map(s => ByteString(s"$s\n"))
.toMat(FileIO.toPath(Paths.get(fileName)))(Keep.right)
val reulst: Future[IOResult] = factorials.runWith(lineSink("factorials2.txt")
<예제 2>를 보면, FileIO Sink를 활용한 Writing 과정을 Flow를 이용하여 재정의하고 있습니다. FileIO의 toPath는 Input이 ByteString으로 정해져 있으므로 변환하는 과정이 필요한데, 이 변환 과정과 저장 단계를 하나로 묶을 수 있습니다. 이 변환의 과정을 정의하는 것이 Flow이고, toMat을 통해 재사용이 가능한 Sink(혹은 Source)로 instantiate 할 수 있습니다. 위의 예제에서, Keep.right는 마지막에 위치한 FileIO를 Sink 결과물로 내어주기 위해 사용되었습니다. 자세한 설명은 Stream flow basics(
http://doc.akka.io/docs/akka/2.4/scala/stream/stream-flows-and-basics.html)를 참고해주시기 바랍니다.
이제 예제보다 조금 더 구조화 된 사례를 들어 설명해 보겠습니다. Stream을 실제 구조화하기 위해서는 Flow 또는 Graph를 사용해야 합니다. Flow와 Graph를 정의하는 것은 마치 청사진을 미리 준비한 후 실행 계획을 세우는 것과도 같습니다. 잘 정의한다면 한 눈에 알아보기 쉬운 데이터의 처리 흐름을 만들어 낼 수 있습니다.
Akka stream kafka 를 이용하여 Kafka produce 만들기
Akka stream 을 사용할 때, 특히 Kafka sink를 사용할 때의 data reliability를 제공하는 방법에 대해서 살펴보겠습니다. 먼저 Akka stream을 사용하여 Kafka로 producing 을 하기 위한 기본 코드를 살펴보고, 발생 가능한 데이터 유실 문제에 대해 정의한 뒤 해결 방법을 이야기해보도록 하겠습니다.
Akka stream을 사용하여 Kafka의 특정 토픽으로 message를 전송하기 위해서 akka-stream-kafka library를 활용했습니다. 이 library의 자세한 내용은 github (
https://github.com/akka/reactive-kafka)에서 확인하실 수 있습니다. 기본적인 사용법과 configuration을 위한 가이드도 제공하고 있으니 사용하실 때 참고하시면 좋을 것 같습니다. Kafka로 message를 publish 하기 위해서는 우선 Producer를 생성하기 위한 기본 configuration을 설정해주어야 합니다. 아래와 같은 형태로 기본 설정을 만들면 됩니다.
1
2
3
val brokers = "host1:9092,host2:902,host3:9092"
val producerSettings = ProducerSettings(syste, new ByteArraySerializer, new StringSerializer)
.withBootstrapServers(brokers)
<예제 3 - Kakfa produer settings>과 같이 producer 관련 setting을 생성하면, 해당 Kafka broker로 message를 전송할 준비가 된 것입니다. 아래의 코드는 Akka stream을 통해 실제 message를 전송하는 예시입니다.
1
2
3
4
Source(1 to 10000)
.map(_.toString)
.map(elem => new ProducerRecord[Array[Byte], String]("topic1", elem))
.to(Producer.plainSink(producerSettings))
이번에는 akka stream kafka에서 제공하는 flow를 사용하여 메시지를 produce하는 방법에 대해 알아보겠습니다.
다음은 두 가지 형태의 message를 Kafka로 produce하는 예제입니다.
1
2
3
4
5
6
7
8
9
Source(1 to 1000)
.map(elem => ProducerMessage.Message(new ProducerRecord[Array[Byte], String]("topic1", elem.toString), elem))
.via(Producer.flow(producerSettings))
.map { result =>
val record = result.message.record
println(s"${record.topic}/${record.partition} ${result.offset}: ${record.value} (${result.message.passThrough}")
result
}
.to(Sink.ignore)
message를 produce 하는 두 예제 (<예제 4>와 <예제 5>) 간의 큰 차이점을 발견하기 어려울 수도 있습니다. 하지만, stream을 구성하고 사용하는 방법에서 약간의 차이가 있고, 용도도 다를 수 있습니다. 두 예제 모두 1에서 10000까지의 숫자를 Kafka 내의 topic1로 produce 하고 있습니다. 두 번째 예제에는 akka stream kafka에서 제공하는 flow를 사용한 작업이 더해져 있습니다. `via`를 통해 실제 flow로 전달하고자 하는 message를 보내고, 전송에 성공한 결과물을 map을 통해 후 처리를 하는 것입니다.
Kafka로 메시지를 보내는 것은 위 두 가지 예제를 활용하여 처리할 수 있습니다. 이 예제들은 github에서 제공하는 가이드에도 포함되어 있습니다. Kafka를 사용해보신 분들이라면, 여기까지 구현하면 어느 정도 처리가 된다는 것은 알고 계실 것 같구요. Kafka 또는 네트워크 상에서 문제가 발생했을 때, 전송하던 데이터 손실을 어떻게 처리할 수 있는지가 추가로 고민했던 부분입니다. Akka stream에는 message를 처리하는 도중 이러한 문제가 발생하면 stream에 대한 self recover를 수행하는 기능이 포함되어 있습니다. 이 기능을 사용하면 stream이 중단되는 것과 같은 critical한 이슈는 막을 수 있습니다. 이 때 사용하는 것이 Supervision Strategy입니다. 자세한 내용은 Akka stream 문서의 Error Handling(http://doc.akka.io/docs/akka/2.4/scala/stream/stream-error.html#supervision-strategies) 부분을 참조하시면 됩니다.
Supervision 을 통한 Error Handling 요약
간략히 정리하자면, message 처리 과정에서 exception 등 예측하지 못한 error case가 발생한 경우, 상위의 supervisor에게 exception을 보고하고, akka stream이 어떻게 행동할지에 대한 정책을 받아오는 과정이라고 할 수 있습니다. 정책은 Resume, Restart, Stop 세 가지로 구성됩니다. Resume과 Restart는 문제를 일으킨 message를 drop시키고, akka stream이 계속해서 처리를 진행할 수 있도록 stream을 관리합니다. Stop은 말 그대로 akka stream의 처리가 더 이상 진행되지 않도록 stream 자체를 중단시키는 것을 의미합니다. Stream이 중단되면, 흘러 들어오던 메시지들은 모두 dead letter mail box로 보내져 사용자가 정의해 놓은 처리 과정을 거치지 못하게 되죠.
Reliable message producing
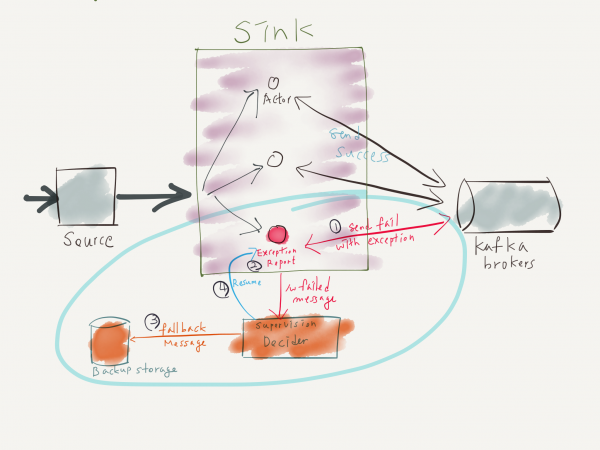
여기서부터가 제가 정말 이야기하고 싶었던 주제입니다. ^^; 너무 멀리 돌아온 듯 싶지만, 본격적으로 이야기해보도록 하겠습니다. 설명할 내용은 길지 않습니다만, 이 처리 과정을 실제 애플리케이션 로직에 적용한다면, Kafka upgrade, Kafka broker restart, 장애 등의 다양한 상황에 기민하게 대응할 수 있을 것으로 기대합니다. 아래는 Akka stream 을 활용하여 구성하고자 하는 시스템의 간략한 구성도입니다.
위 구성도에서 보여지는 구조를 구현하기 위해서 관련 내용을 알아보겠습니다. 먼저 Supervision Strategy의 사용 방법을 살펴보겠습니다. Supervision Strategy를 akka stream에 적용하기 위해서는, ActorMaterialzer 생성 시 param으로 Supervision Strategy instance를 넘겨주어야 합니다. 다음 예제를 확인해보세요.
1
2
3
4
5
6
val decider: Supervision.Decider = {
case _: ArithmeticException => Supervision.Resume
case _ => Supervision.Stop
}
implicit val materializer = ActorMaterializer(
ActorMaterializerSettings(system).withSupervisionStrategy(decider))
<예제 6> 코드는 akka stream의 메시지 처리 과정에서 exception이 발생하면, Supervision.Decider instance로 보고하도록 짜여져 있습니다. 보고를 받은 decider 는 try / catch 의 catch 구문처럼 exception 처리 과정을 추가합니다. 여기서 return해야 하는 Enum은 Supervision.Resume/Restart/Stop으로 정의되어 있으며, 앞서 설명한 것과 같이 return된 값이 곧 정책이 되어 akka stream의 다음 행동을 결정합니다. 위 예제의 decider는 ArithmeticException은 Resume을, 그 외 모든 exception들은 Stop 하도록 정의하고 있습니다. 이렇게 kafka로 message를 produce 하는 stream logic을 적용하면, exception이 발생했을 때 decider로 보고되기 때문에, 이 시점에서 실패한 메시지에 대한 처리를 수행하면 됩니다.
현재 akka-stream-kafka 의 한계
하지만 akka stream kafka가 제공하는 Producer flow는, exception이 발생할 경우 실제 메시지는 제외한 채, exception이 발생한 사실만 보고하도록 구현되어 있습니다. 이러한 이유로, exception에 대한 처리와 stream 작업이 계속되어도 실제 데이터에 대한 fallback 처리는 불가능합니다. 즉, 현재 버전의 akka-stream-kafka는 데이터에 대한 처리를 지원하지 않습니다.
message produce를 실행 중인 akka-stream-kafka의 flow를 통해, 실제 kafka producer를 어떻게 생성하여 사용하고 있는지 살펴보겠습니다. 현재 사용하고 있는 위의 코드 <예제 5>를 보면, Producer.flow라는 method를 사용하여 flow를 생성하고 있는데요, 이 Producer.flow 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/**
* Publish records to Kafka topics and then continue the flow. Possibility to pass through a message, which
* can for example be a [[ConsumerMessage.CommitableOffset]] or [[ConsumerMessage.CommittableOffsetBatch]] that can
* be committed later in the flow.
*/
def flow[K, V, PassThrough](settings: ProducerSettings[K, V]): Flow[K, V, PassThrough], Result[K, V, PassThrough], NotUsed] = {
val flow = Flow.fromGraph(new ProducerStage[K, V, PassThrough](
settings,
() => settings.createKafkaProducer()
))
.mapAsync(settings.parallelism)(identity)
if (settings.dispatcher.isEmpty) flow
else flow.withAttributes(ActorAttributes.dispatcher(settings.dispatcher))
}
<예제 7> 코드를 보면, parameter로 넘겨받은 Kafka producer와 관련된 setting을 이용하여 ProducerStage[K, V, PassThrough]를 생성합니다. 그리고 이 ProducerStage 내에서 settings.createKafkaProducer()를 통해 실제 Kakfa producer를 생성합니다.
ProducerStage[K, V, PassThrough]의 내부를 조금 더 자세히 보겠습니다. 참고로, ProduceStage는 akka-stream-kafka의 internal use only로 구현된 class입니다. 따라서, 여기에서는 ProducerStage의 내부 코드 중 일부를 옮겨 수정하는 방식을 다루겠습니다. ProducerStage는 Push/Pull model을 구현하고 있습니다. pull을 통해 처리할 message를 가져오고, push를 통해 message produce 과정을 실행하는 방식입니다. 이 때 message produce에 실패한 경우의 처리 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
setHandler(in, new InHandler {
override def onPush() - {
val msg = grab(in)
val r = Promise[Result[K, V, P]]
producer.send(msg.record, new Callback {
override def onCompletion(metadata: RecordMetadata, exception: Exception) = {
if (exception == null)
r.success(Result(metadata.offset, msg))
else
r.failure(exception)
decrementConfirmation.invoke(())
}
})
awaitingConfirmation += 1
push(out, r.future)
}
override def onUpstreamFinish() = {
completionState = Some(Success(()))
checkForCompletion()
}
override def onUpstreamFailure(ex: Throwable) = {
completionState = Some(Failure(ex))
checkForCompletion()
}
})
onCompletion 안의 코드가 producer를 사용하여 message를 보내는 부분입니다. 그 결과에 대한 callback을 등록하고, 결과에 대한 확인 및 문제 상황(exception 발생)을 Supervision decider에게 보고하는 부분이기도 하고요. Asynchronous 처리를 위해 Promise가 Future의 형태로 변환되어 사용되는 것을 확인하실 수 있습니다. 성공한 경우 Promise의 success를 호출해서 처리 과정이 정상적으로 진행되도록 하고, 실패한 경우 failure를 사용하여 실패에 대한 보고를 하게 됩니다. SupervisionStrategy 코드의 내부까지 자세히 살펴보지 않아도, asynchronous로 처리되는 코드들은 future의 series로 연결이 되어 있을 것으로 유추할 수 있습니다. 해당 future들에 대한 recover(fallback) 처리 과정이 SupervisionStrategy쪽으로 callback이 연결되어 있는 것으로 보이구요. (나중에 이 부분은 조금 더 자세히 살펴보아야겠네요.) 방금 설명한 내용을 통해, 우리는 flow 안에서 Kafka로 message를 produce 하는 과정에 대해 알게 되었고, 문제가 발생했을 때 내부에서의 동작이 어떻게 구현되어 있는지도 알게 되었습니다. 이제 어떤 부분을 건드려야 외부에서 실패한 메시지들의 reliability를 제공할 수 있을까요? 바로 producer가 send 후 callback을 등록해 둔, onCompletion 부분입니다. 앞서 말씀드린대로, 지금은 단순히 exception 사실만을 보고하도록 되어 있으므로, application 로직 (akka stream을 정의하고 처리하도록 설계한 로직) 레벨에서는 메시지를 구경조차 할 수 없습니다. 다른 좋은 방식이 많겠지만, 메시지 자체를 위로 보고하고, 케이스를 나누어 처리하는 방법을 집중적으로 다루겠습니다.
해결 방안
아주 단순하게 접근해 보겠습니다. 문제는 message 자체가 위로 보고되지 않는다는 것입니다.
- Custom exception 정의
- Custom exception이 실제 exception을 담고, 이 때 message를 추가
- Custom exception을 Promise의 fail로 처리
- Decider가 방금 만든 custom exception 케이스만 발췌 후 분기
- Message를 다른 backup storage에 저장하고, 나중에 다시 처리할 수 있도록 도움
물론 backup storage 또는 메모리에 저장한 뒤 retry 과정을 진행할 수도 있고, fallback kafka broker를 두어 완전하게 end to end를 보장할 수도 있습니다. 하지만 이러한 전략은 시스템 환경에 대한 고려와 운영자의 검토하에 세워져야 하는 부분이므로, 여기에서는 더 다루지 않겠습니다.
결론 - 구현 내용
이제 앞서 설명한 내용을 바탕으로 간략히 코드를 추가해 보겠습니다. 먼저 custom exception를 아래와 같이 정의한 뒤, Exception을 담을 있도록 member variable을 정의하고, 처리에 실패한 메시지를 담기 위한 member variable을 정의하였습니다.
1
case class KafkaFallbackException[K, V](exception: Exception, record: ProducerRecord[K, V]) extends Exception(exception)
이제, 앞서 <예제 9>에서 정의한 KafkaFallbackException을 사용하는 부분입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
setHandler(in, new InHandler {
override def onPush() - {
val msg = grab(in)
val r = Promise[Result[K, V, P]]
producer.send(msg.record, new Callback {
override def onCompletion(metadata: RecordMetadata, exception: Exception) = {
if (exception == null)
r.success(Result(metadata.offset, msg))
else
r.failure(new KafkaFallbackException(exception, msg.record))
decrementConfirmation.invoke(())
}
})
awaitingConfirmation += 1
push(out, r.future)
}
override def onUpstreamFinish() = {
completionState = Some(Success(()))
checkForCompletion()
}
이것으로 코드는 변경이 끝났습니다. 너무 간단해서 길게 설명할 필요가 없네요. ^^;
이제 남은 것은 메시지가 decider로 넘겨진 후의 처리 과정입니다.
1
2
3
4
5
6
7
8
9
val decider: Supervision.Decider = {
case e: KafkaFallbackException[String, String] =>
// fallback message store to local storage file using slf4j logger
logger.info(e.record.value)
Supervision.Resume
case e: Exception =>
logger.error(s"Unspected exception occurred : $e", e)
Supervision.Resume // Just ignore data with unhandled exception, in case of non-pre-defined
}
decider가 앞서 정의한 KafkaFallbackException을 처리할 수 있도록 case 를 추가하고, 해당 block에서 처리하는데 실패한 message를 로컬에 저장하도록 했습니다. slf4j logger를 사용하여 로컬에 저장된 message는 각자의 정책에 따라 처리하면 됩니다. file tailing을 통해 실시간으로 수집할 수도 있고, rsync를 통해 주기적으로 카피해가는 정책을 적용할 수도 있습니다. custom exception 이외의 케이스에 대해서는, message를 로깅 후 버리도록 했습니다.물론 위에서도 message를 로컬에 저장하도록 하고 있으니, 사실상 같은 것이겠네요.
얻을 수 있는 이득
이야기하고자 했던 내용들은 이제 모두 말씀드린 것 같습니다. 위 기능이 개발되면, Kafka broker가 내려가는 상황이 발생해도 Akka stream이 각 actor들의 mailbox에 메시지를 buffering 하고 flow에서 처리하고 있으므로, 나중에 broker가 다시 정상화 되었을 때 실패한 메시지는 따로 저장되고, 뒤이어 들어오는 message stream도 문제없이 처리될 수 있습니다. 물론 akka stream을 운영중인 JVM instance가 내려갈 경우에는 손실이 발생할 수 있지만, fail over는 다른 방식으로 해결책을 찾을 수 있습니다. 나중에는 persistent actor 등을 사용하여 처리하는 방법 등에 대해서도 정리해보도록 하겠습니다. 당연히 아실테지만, 여기에서 정리한 내용은 정답이 아니라, 선택할 수 있는 방법들 중 한가지입니다.