NSA의 Dataflow 엔진 Apache NiFi 소개와 설치

Apache NiFi는 NSA(National Security Agency)에서 Apache에 기증한 Dataflow 엔진입니다. 복잡해지는 기업의 시스템들에서 신속하고, 유실 없는 데이터 전송은 점점 더 중요해 지고 있습니다. 빅데이터 시스템도 마찬가지로 데이터의 전송 경로가 더 복잡해지고, 실시간 처리가 중요해지는 시점에 Apache NiFi는 훌륭한 솔루션입니다. 여기서는 NiFi의 소개와 설치에 대해서 알아보도록 하겠습니다.
본 글은 저자가 경험을 통해 작성한 글로 오류가 있을 수 있습니다. 오류 또는 다른 의견이 있으신 분은 댓글을 통해 교류했으면 좋겠습니다. 또한 NiFi의 컴포넌트 및 개념에 해당하는 것은 영어로 표기했으며, 이미지는 nifi.apache.org에 있는 것을 사용했습니다.
소개
Apache NiFi는 시스템 간 데이터 전달을 효율적으로 처리, 관리, 모니터링하기 위한 최적의 시스템이다. NiFi는 다음과 같은 특징을 가지고 있으며, 이러한 특징들 때문에 복잡한 시스템 간의 데이터 이동에 NiFi를 이용하여 쉽고, 안전하게 개발 할 수 있다.
- Dataflow를 쉽게 개발할 수 있고, 시스템 간의 데이터 이동과 내용을 볼 수 있는 기능과 UI를 제공한다.
- 실시간 데이터 전송에 필요한 유용한 기능을 제공한다.
- 강력한 자원과 권한 관리를 통해 멀티테넌시(Multi-tenant, 여러 조직이 자원을 공유해서 사용)를 지원한다.
- 데이터가 어느 시스템으로부터 왔는지 추적할 수 있다.
- 국내에는 크게 사용하는 곳이 없지만, 해외에서는 충분한 사례가 있다.
- 오픈 소스이면서, 호튼웍스의 기술 지원을 받을 수 있다.
- 여러 NiFi 시스템 간 통신을 지원한다(Site-to-site).
NiFi는 Flow Based Programming(FBP)의 개념을 구현했으며, 프로세서를 이용하여 수집, 변형, 저장을 여러 단계에 거쳐서 할 수 있다. 다음은 NiFi에서 사용하는 주요 용어들이다.
| NiFi 용어 | FBP 용어 | 설명 |
| FlowFile | Information Packet | Nifi에서 데이터를 표현하는 객체로, Key/Value 형태의 데이터 속성(Attribute)과 데이터(Content)를 포함할 수 있다. 데이터는 0바이트 이상의 데이터가 저장될 수 있다. FlowFile를 이용하여 여러 시스템 간의 데이터 이동이 가능하다. |
| FlowFile Processor | Black Box | FlowFile은 여러 단계에 걸쳐 속성이 추가되거나 내용이 변경될 수 있는데, 이때 사용되는 것이 FlowFile Processor이다. NiFi는 150개 이상의 Processor를 제공하는데, 이를 이용하여 FlowFile을 다양한 시스템으로부터 읽어와 변경, 저장을 할 수 있다. |
| Connection | Bounded Buffer | Processor 간의 연결을 말하며, NiFi의 Connection은 FlowFile의 대기열(queueing)뿐만 아니라 라우팅, 처리량 제한, 우선순위 제어, 모니터링 등의 강력한 기능을 제공한다. |
| Flow Controller | Scheduler | Processor가 어느 간격 또는 시점에 실행하는지 스케줄링한다. |
| Process Group | subnet | 특정 업무, 기능 단위로 여러 Processor를 묶을 수 있으며, Input과 Output 포트를 제공해 Process Group 간의 데이터 이동이 가능하다. |
NiFi 아키텍처
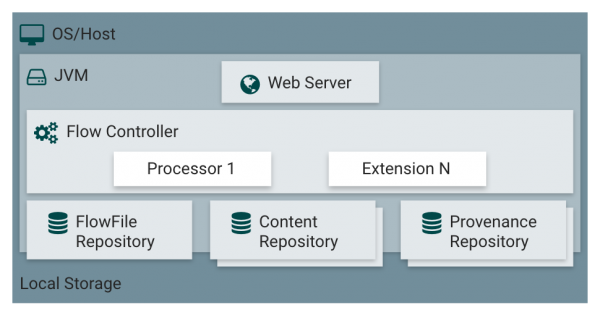
NiFi는 JVM 환경에서 실행되며, 위 그림과 같은 컴포넌트들로 구성되어 있다.
Web Server
NiFi는 UI를 웹 서비스를 통해 제공하며, 개발자 혹은 관리자는 이를 이용하여 Dataflow 개발, 제어, 모니터링을 한다.
Flow Controller
위에 설명한 것과 같이 Processor들의 스케줄링을 담당한다.
Extension
NiFi가 제공하는 기본 Processor들 외, 개발자가 프로세스를 개발해 확장할 수 있다.
FlowFile Repository
Write-Ahead-Log로 FlowFile의 상태와 속성값들을 저장하는 곳이다. 일반적으로 Raid 10으로 디스크를 구성하여 저장해, 시스템 장애 때 유실되지 않게 한다.
Content Repository
FlowFile의 데이터(Content)가 저장되며, 일반적으로 Raid 10으로 디스크를 구성해 저장하며, 여러 디렉토리에 분석 저장이 가능하다. 이 때문에 용량이 큰 데이터를 저장할 수 있으며, 단일 디스크의 처리량보다 많은 양을 처리할 수 있다. Nifi 시스템의 역할을 봤을 때, 일반적으로 여러 파티션을 사용할 경우가 많지는 않을 것이다.
Provenance Repository
데이터의 처리 단계별로 FlowFile 변화(원천) 데이터를 보관하는 곳으로, 여러 디스크를 지원하며, 각 데이터는 인덱스 되어 검색할 수 있다.
FlowFile, Processor
위에 설명하였지만, 다시 언급할 만큼 NiFi의 핵심 컴포넌트이다. FlowFile은 Processor에 의해 생성되며, FlowFile은 속성 정보와 데이터가 들어있다. 예를 들어 HDFS에서 파일을 조회하는 Processor(ListHDFS)에서 생성된 FlowFile은 데이터(Content)는 없으며, HDFS의 파일 속성만이 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16// HDFS에서 디렉토리의 파일 목록 조회 for (final FileStatus status : listable) { final Map<String, String> attributes = createAttributes(status); FlowFile flowFile = session.create(); flowFile = session.putAllAttributes(flowFile, attributes); session.transfer(flowFile, REL_SUCCESS); ... } // FlowFile의 속성에 HDFS의 파일 정보 입력 private Map<String, String> createAttributes(final FileStatus status) { ... attributes.put("hdfs.owner", status.getOwner()); attributes.put("hdfs.group", status.getGroup()); ... return attributes; }
NiFi는 아래 그림과 같이 클러스터 환경으로도 운영할 수 있다.
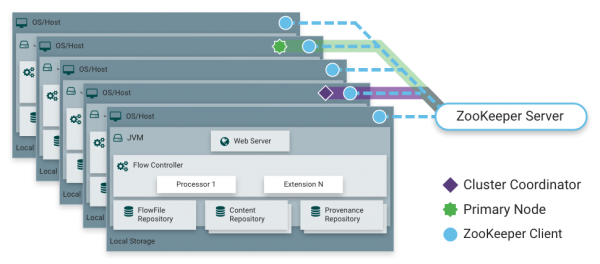
Cluster Coordinator가 각 NiFi 서버들의 정보(가동여부, 상태)를 관리하며, DataFlow의 추가, 삭제, 수정 등의 변경을 클러스터에 등록된 NiFi 노드들에 복제해 준다. Primary Node는 여러 노드에서 Processor가 실행되지 않고, 특정 단일 노드에서만 실행하고자 할 때 사용되는 대표 노드이다. 이러한 역할들은 ZooKeepr Server에 자동으로 선출되며, NiFi 1.0부터는 Zero-Master Clustering이 적용되어 클러스터 내에 NiFi 노드들 중 한대가 자동으로 Cluster Coordinator와 Primary Node가 된다.
클러스터의 각 노드는 같은 Dataflow를 가지고 있으며, 각 노드에서 중복되지 않는 서로 다른 데이터를 처리한다. 클러스터를 소개할 때 자세히 다루겠지만, 간단히 그림을 통해 소개하겠다.

위 그림과 같이 클러스터 환경에서 데이터를 분산 처리할 수 있다. 데이터의 중복 조회를 막기 위해 Primary Node에서 ListHDFS processor를 실행하며, ListHDFS는 위 소스 코드에서 간략히 소개했듯이 HDFS의 특정 디렉토리 안의 파일들을 조회하여, 파일 별로 FlowFile을 생성한다. 이렇게 생성된 FlowFile은 여기서 다루지는 않았지만 RPG(Remote Process Group)에 전달되어 각 노드로 FlowFile을 분산하여 전달되며, FetchHDFS Processor를 이용하여 HDFS의 파일을 조회한다. 이렇듯 NiFi는 여러 노드들이 같은 Dataflow를 가지고 데이터를 분산하여 처리할 수 있다.
NiFi 로컬 설치
여기서는 리눅스 환경의 로컬 설치에 대해서만 다루도록 하며, 서버 환경에 대해서는 다른 글을 통해 소개할 예정이다.
NiFi 다운로드 페이지에서 NiFi 최신 버전을 받는다. 여기서는 nifi-1.0.0-bin.tar.gz 파일을 내려받으며, 해당 버전은 클러스터 환경에서 문제가 있지만, 로컬 환경에서는 문제가 없다. 압축을 해제하고, NiFi 설치 디렉토리에서 "bin/nifi.sh start"를 하면, NiFi가 실행되며, 기본 설정이라면 http://localhost:8080/nifi을 통해 접속할 수 있다. NiFi가 전체 다 기동 되려면 PC 사양에 따라 다르겠지만 30초 이상 걸리므로 참고하길 바란다.
1 2 3 4 5 6 7 8localhost:~/nifi/nifi-standalone$ bin/nifi.sh start Java home: /usr/lib/jvm/java-8-oracle NiFi home: /home/combine/nifi/nifi-standalone Bootstrap Config File: /home/combine/nifi/nifi-standalone/conf/bootstrap.conf 2016-09-24 16:36:02,900 INFO [main] org.apache.nifi.bootstrap.Command Starting Apache NiFi... 2016-09-24 16:36:02,900 INFO [main] org.apache.nifi.bootstrap.Command Working Directory: /home/combine/nifi/nifi-standalone 2016-09-24 16:36:02,900 INFO [main] org.apache.nifi.bootstrap.Command Command: /usr/lib/jvm/java-8-oracle/bin/java -classpath ... org.apache.nifi.NiFi localhost:~/nifi/nifi-standalone$
위 실행 화면에서 보면 Command라는 항목이 보이는데, NiFi 쉘을 실행하면, RunNiFi가 실행되고 이는 NiFi 데몬을 실행한다. 총 RunNiFi, NiFi 2개의 데몬이 뜨며, NiFi 데몬이 비정상적으로 종료하게 되면 RunNiFi가 이를 감시하여, 오류 메시지를 이메일 등으로 보낼 수 있는 알람 기능이 있다.
NiFi 웹 구성 요소
NiFi 웹 서비스에 접속하면, 아래 그림과 같은 화면을 볼 수 있다.
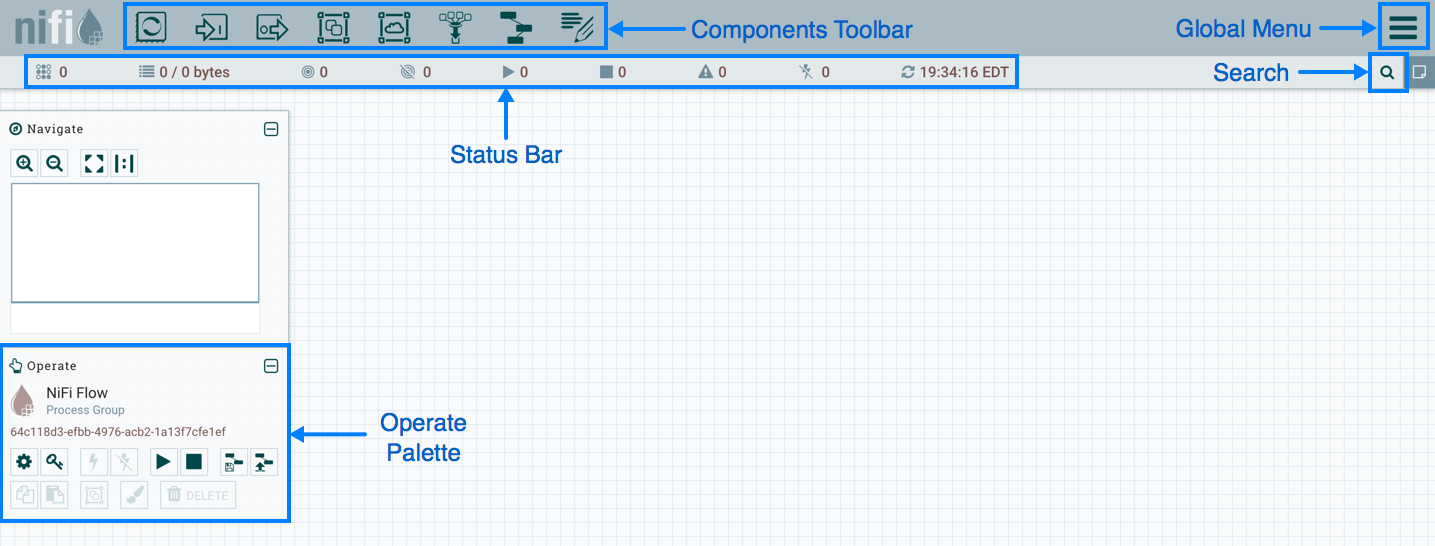
Components Toolbar
NiFi에서 사용하는 컴포넌트들이 있다. 이 컴포넌트를 클릭하여 드래그&드롭으로 캔버스에 컴포넌트를 등록시킬 수 있다.
Global Menu
아래 그림과 같은 메뉴로 구성되어있다.
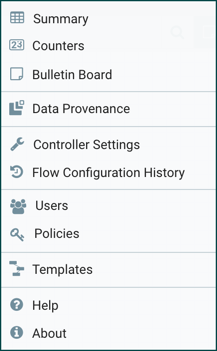
- Summary: NiFi에 등록된 컴포넌트들을 종합적으로 보고, 검색할 수 있다.
- Counter: MapReduce의 카운터와 유사한 기능으로 특정 Processor에서 발생시키는 카운트 정보를 제공한다.
- Bulletin Board: 시스템의 문제 등을 볼 수 있다.
- Data Provenance: 데이터를 추적할 수 있다.
- Controller Settings: FlowFile Controller의 설정(쓰레드 개수)과 DB Poll, Cache 서비스와 같은 컨트롤러 서비스를 관리 한다.
- Flow Configuration History: FlowFile의 등록, 삭제, 변경 등의 이력을 제공한다.
- Users, Policies: 사용자 및 권한을 관리 한다. NiFi는 SSL 인증서 기반의 인증(X.509)을 제공하는데, 인증 시스템이 활성화된 경우에만 메뉴가 보인다.
- Templates: Processor와 그 들의 연결 정보인 Connection 컴포넌트를 속성까지도 유지 한 체 템플릿화 할 수 있는데, 이렇게 등록된 템플릿을 조회하고, 내려받을 수 있는 기능을 제공한다.
- Help: 도움말을 제공한다.
- About: NiFi 버전 정보를 제공한다.
Status Bar
NiFi의 현재 상황을 볼 수 있다. 실행되고 있는 태스크, 프로세스 개수 정보와 오류 정보, 클러스터 노드 정보 등을 제공한다.
Search
NiFi에 등록된 Processor, Connection을 검색할 수 있다.
Operate Palette
NiFi 컴포넌트들의 설정, 활성화/비활성화, 시작/멈춤, 템플릿 생성/등록, 컴포넌트 복사/붙여넣기, Processor Group 화, 컴포넌트 색 변경, 컴포넌트 삭제 기능을 제공한다. 캔버스에서 컴포넌트를 선택하면, 상황에 따라 버튼들이 비화성화 된다. 또, Shift + 선택 또는 Shift + 선택영역 드래그를 통해 여러 개의 컴포넌트를 선택할 수 있다.
NiFi Processor 등록 및 연결
NiFi는 Processor 등록부터 시작한다. 데이터의 시작과 종료를 모두 Processor로 수행하므로 가장 많이 사용하는 기본 기능이다. Processor 등록을 위해서는 Component Toolbar의 Processor 아이콘(![]() )을 선택하여, 드래그하여 캔버스의 원하는 위치에 놔두면(드롭) 아래와 같은 추가할 Processor를 검색할 수 있다.
)을 선택하여, 드래그하여 캔버스의 원하는 위치에 놔두면(드롭) 아래와 같은 추가할 Processor를 검색할 수 있다.
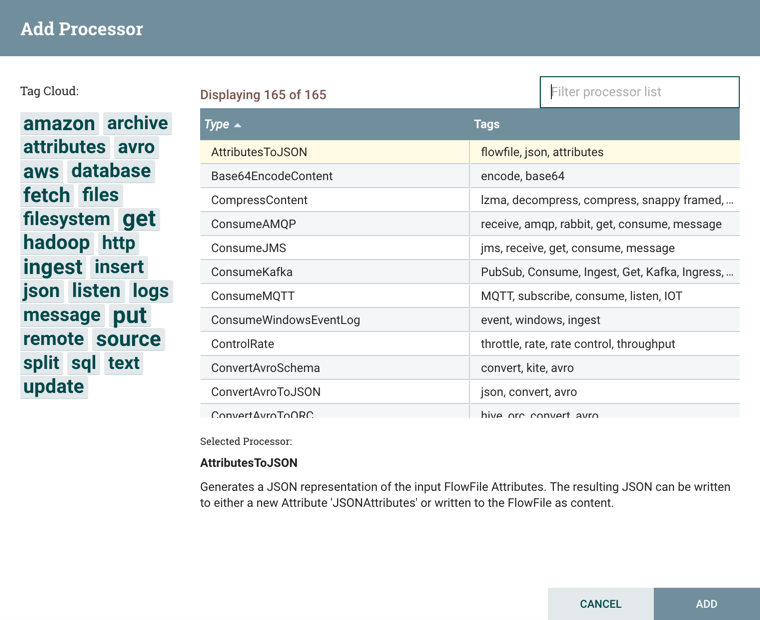
원하는 Processor를 필터에 입력하여 찾을 수 있으며, 옆에 Tag Cloud를 통해 Processor들을 분류할 수도 있다. 사용할 Processor를 테이블에서 선택하고, ADD 버튼을 눌러 등록하기 바란다. 여기서는 임의의 FlowFile을 생성하는 GenerateFlowFile을 등록한다.
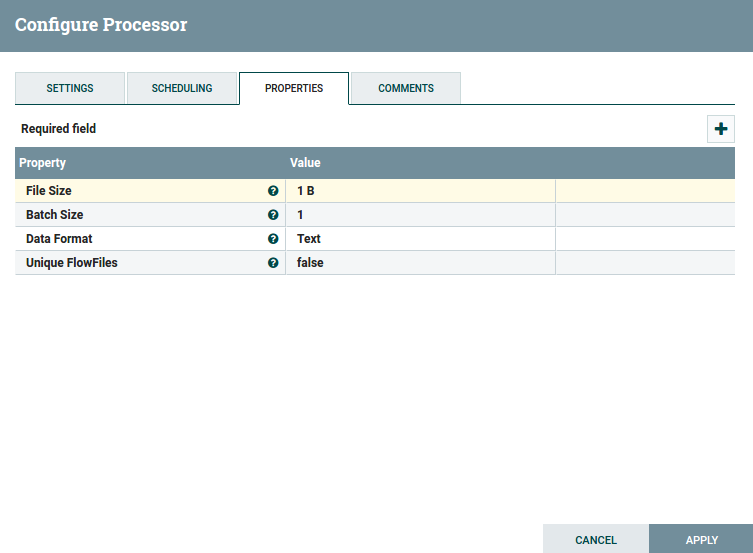
등록된 GenerateFlowFile Processor를 선택하고, 오른쪽 마우스 > Configuration을 선택하거나, Operate Palette의 설정 버튼(![]() )을 눌러 다음과 같은 설정을 할 수 있으며, APPLY를 눌러 설정을 저장할 수 있다. 아래는 임의의 FlowFile을 한 개씩 1 Byte 문자로 생성하라는 의미이다.
)을 눌러 다음과 같은 설정을 할 수 있으며, APPLY를 눌러 설정을 저장할 수 있다. 아래는 임의의 FlowFile을 한 개씩 1 Byte 문자로 생성하라는 의미이다.
같은 방법으로 LogAttribute라는 Processor도 등록하자. 이는 FlowFile 정보를 NiFi 로그 파일($NIFI_HOME/logs/nifi-app.log)에 출력시킬 수 있다.
Processor 위에 마우스를 올리면 연결 버튼(![]() )이 나오는데 이 버튼을 선택하여, GenerateFlowFile과 LogAttribute Processor를 연결하고, Operate Palette에 시작 버튼(
)이 나오는데 이 버튼을 선택하여, GenerateFlowFile과 LogAttribute Processor를 연결하고, Operate Palette에 시작 버튼(![]() )을 선택하여 Dataflow를 시작한다. 로그 파일을 "tail -f"로 보면 FlowFile의 속성 정보들이 로그에 출력되는 것을 확인할 수 있다. 정지 버튼(
)을 선택하여 Dataflow를 시작한다. 로그 파일을 "tail -f"로 보면 FlowFile의 속성 정보들이 로그에 출력되는 것을 확인할 수 있다. 정지 버튼(![]() )을 선택하여 Dataflow를 정지시킨다. 컴포넌트를 선택하지 않고 시작, 정지 버튼을 누르면 캔버스 전체의 컴포넌트들에 대해 적용되며, Shift + 선택, 또는 Shift + 드래그를 통해 선택된 컴포넌트들만 시작, 정지를 할 수 있다. 이 모든 기능은 대부분 직관적인 인터페이스라 몇 번 사용하면 금세 익숙해질 수 있다. 여기서는 더 상세히는 못 다루고, 아래 그림과 같은 Dataflow을 개발해보기 바란다. 다음 글에서는 이것을 할 수 있다는 가정에서 진행할 예정이다.
)을 선택하여 Dataflow를 정지시킨다. 컴포넌트를 선택하지 않고 시작, 정지 버튼을 누르면 캔버스 전체의 컴포넌트들에 대해 적용되며, Shift + 선택, 또는 Shift + 드래그를 통해 선택된 컴포넌트들만 시작, 정지를 할 수 있다. 이 모든 기능은 대부분 직관적인 인터페이스라 몇 번 사용하면 금세 익숙해질 수 있다. 여기서는 더 상세히는 못 다루고, 아래 그림과 같은 Dataflow을 개발해보기 바란다. 다음 글에서는 이것을 할 수 있다는 가정에서 진행할 예정이다.
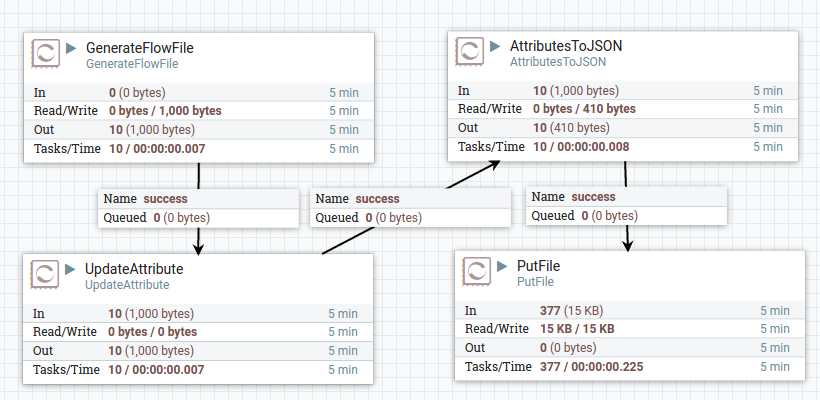
참고 자료
NiFi 전체를 다루는 문서로 이 글 연제의 대부분이 이 문서를 참고하여 작성했다.
https://nifi.apache.org/docs.html
NiFi 0.7 미만의 낮은 버전도 크게 다르지 않다. 1.0 버전에서 UI가 대폭 개선되어 달라 보이지만 대부분 구성요소는 변화가 없어, 사용법을 익히는 데 무리가 없다.
꼼꼼히 NiFi의 기술 하나씩 보실 분은 아래 2개의 영상을 보면 되고, 두 동영상 내용이 거의 유사한 내용이므로 감이 잡히면 바로 넘어가도 좋다.
https://www.youtube.com/playlist?list=PLHre9pIBAgc4e-tiq9OIXkWJX8bVXuqlG
https://www.youtube.com/channel/UC4-OIG3NPACKukfZGLWA0eQ
시간이 너무 없어 빠르게 익히실 분은 아래 동영상을 보면서 따라 한다.
https://www.youtube.com/watch?v=FgTGAWLC170
PDF로 된 슬라이드로 빠르게 익힐 수 있다.
http://requitest.com/nifi.html
실제 적용 사례는 다음 글에 설명되어 있다.
http://www.popit.kr/bigdata-platform-based-on-nifi/
긴 글 읽어주셔서 감사합니다. 오타 및 오류, 이견들은 댓글로 남겨주시면 반영 또는 답변 드리겠습니다.
앞으로 NiFi에 대해서 연재가 될 것이며, 다음 글은 주요 환경 변수와 클러스터 설치입니다.
감사합니다.