[입 개발] Consistent Hashing 에 대한 기초

* 해당 글은 http://charsyam.wordpress.com 에도 올리지만, popit에도 함께 올리는 글입니다.
최근에 consitent hashing 에 대해서 다시 한번 공부를 해야할 기회가 생겨서 다시 한번 훝어보게 되었습니다. 그러면서 느낀게... 내가 잘못 이해하고 그렇게 구라를 치고 있었구나라는 점을 느끼게 되었죠.(이것도 개구라일지도...)
Consistent Hashing 에 의 가장 큰 특징 중에 하나는 HashRing에 k 개의 노드가 있는 상황에서, 노드가 사라지거나 추가될 때 1/k 정도의 key에 대한 것만 유실이 되고 나머지 key는 변동 없이 그 위치에 존재한다는 것입니다. 그리고 같은 값으로 노드들이 만들어지면 그 순서도 항상 동일합니다.(전 바로 이 부분이 신기했었습니다. 그런데... 그런데...)
일단 Consistent Hashing 이라는 것은 David Kager 라는 사람에 의해서 처음 소개가 되었습니다. https://www.akamai.com/es/es/multimedia/documents/technical-publication/consistent-hashing-and-random-trees-distributed-caching-protocols-for-relieving-hot-spots-on-the-world-wide-web-technical-publication.pdf
일단 논문은 어려우니 패스하기로 하고...
1] Consistent Hashing의 핵심은 hash 함수
일단 Consistent Hashsing 의 가장 큰 핵심은 hash 함수입니다. 뭐, 여러가지 어려운 얘기들로 시작하면 더욱 더 어려워지므로, 가장 간단하게 말하자면, hash 함수의 특징은 f = hash(key) 의 결과가 항상 같은 key에 대해서는 같은 hash 결과 값이 나온다는 것입니다. 이 얘기는 우리가 host1, host2, host3 와 같은 주소를 해시하면 hash 함수를 바꾸지 않는 이상은 항상 같은 hash 값이 나오게 됩니다. 그러면 그 hash 값으로 정렬을 하게 되면? 항상 같은 순서가 나오겠죠.
그리고 이 hash 값으로 Hash Ring을 만들면...?
이해를 쉽게 하기 위해서, 어떤 hash의 결과가 0 부터 1 까지 float 형태로 나온다고 가정하겠습니다. hash("host1") = 0.25, hash("host2") = 0.5, hash("host3") = 0.75 가 나온다고 가정하고, 특정 key에 대한 hash 결과는 그것보다 hash값이 크면서 가장 가까운 host에 저장이 된다고 하겠습니다. 즉 hash("key1") = 0.3 이면 key1이라는 key가 위치할 서버는 0.5 값을 가지는 host2가 되게 됩니다. 0.75 보다 크면 Ring 이므로 다시 첫번째 host1에 저장이 되게 됩니다.
이제 우리는 hash 함수와 서버의 목록만 알면, 바로 특정 key를 어디에 저장할 것인지 결정할 수 있게 되었습니다. 그리고 Consistent Hashing은 위에서 말했듯이... 서버가 추가되거나 없어져도, 1/k 개의 key만 사라지는 특성이 있습니다. 이것은 또 어떻게 보장이 되는 것일까요?
hash("host4") = 0.6 인 서버가 하나 추가되었다고 가정하겠습니다. 이 서버가 들어오면 순서는
host1, host2, host4, host3 이 됩니다. 즉 host4 와 host3 사이의 값, 즉 hash 함수의 결과가 0.6 ~ 0.75 인 녀석들만 저장해야 할 서버가 바뀌지, 다른 녀석들은 원래의 위치에 그대로 저장되므로 찾을 수 있게 됩니다.
다시 정리하자면, A, B, C 세 대의 서버가 hash Ring을 구성합니다.
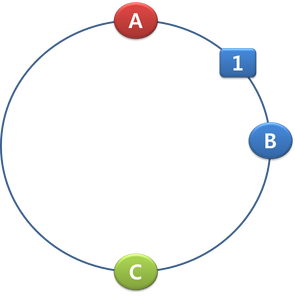
여기에 1이라는 key가 들어오면 hash("1") 해서 그 결과값을 보니 B가 규칙에 맞아서 B에 저장되게 됩니다.
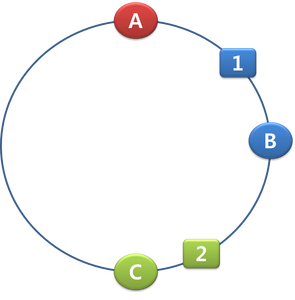
이제 두번 째 2가 들어올 경우 hash("2") 한 값이 C에 속해야 하므로 C에 저장되게 됩니다.
마지막으로 key 3,4는 hash("3"), hash("4") 의 값이 A 서버에 속하므로 A 에 들어가고 key 5는 C에 가까워서 C에 들어가게 됩니다.
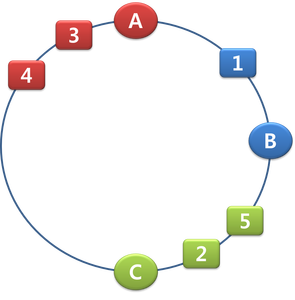
그런데 위의 예제나 그림을 보면, A, B, C의 공간이 서로 균일하지가 않습니다. 또, B가 죽는다고 가정하면 B의 부하는 전부 C로 넘어가게 됩니다. 뭔가 불공평한 일이 벌어지는 것이죠. 그래서 이것을 해결하기 위해서 가상의 친구들을 더 만들어냅니다.
가상의 친구들을 한 서버당 2개씩 더 만든다고 하면 hash('A'), hash('A+1'), hash('A+2') 로 Hash Ring 에 추가합니다. B는 hash('B'), hash('B+1'), hash('B+2') 등으로 추가하면 됩니다. 즉 총 3개의 서버를 9개로 보이게 하는거죠. 아래와 같이 A+1은 실제로는 A지만, hash ring에서 가상적으로 다른 녀석으로 보이게 됩니다. hash ring 자체도 더 촘촘해지고, 어떤 서버가 한대 장애가 나더라도, 그 부하가, 적절하게 나머지 두 서버로 나눠지게 됩니다. 실제 서비스에서는 서버당 수십개의 가상 노드를 만들어서 처리하게 됩니다.(2~3개도 너무 적습니다.) 이것을 보통 vnode 라고 부르게 됩니다.
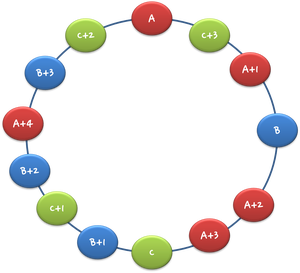
핵심 결론은, 서버 이름으로 hash 값을 만들어서 정렬한 것을 하나의 Ring 처럼 생각해서 key를 hash 값에 따라 저장한다입니다. 다음은 아주 간단하게 만든 Consistent Hashing 코드입니다. rebuild가 핵심입니다.
https://gist.github.com/charsyam/d2ca7cf6143ff714938c246fd7b73018
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50import sys import hashlib import struct VALUE_IDX = 2 HASH_IDX = 3 LAST = -1 FIRST = 0 class ConsistentHash: def __init__(self, kvlist, replica, hash_func = None): self.hash_func = hash_func if not self.hash_func: self.hash_func = self.ketama_hash self.kvlist = kvlist self.replica = replica self.continuum = self.rebuild(kvlist) def ketama_hash(self, key): return struct.unpack('<I', hashlib.md5(key).digest()[0:4]) def rebuild(self, kvlist): continuum = [(k, i, v, self._hash("%s:%s"%(k,i))) \ for k,v in kvlist \ for i in range(self.replica)] continuum.sort(lambda x,y: cmp(x[HASH_IDX], y[HASH_IDX])) return continuum def _hash(self, key): return self.hash_func(key) def find_near_value(self, continnum, h): size = len(continnum) begin = left = 0 end = right = size while left < right: middle = left + (right - left) / 2 if continnum[middle][HASH_IDX] < h: left = middle + 1 else: right = middle if right == end: right = begin return right, continnum[right][VALUE_IDX] def get(self, key): h = self._hash(key) if h > self.continuum[LAST][HASH_IDX]: return self.continuum[FIRST][VALUE_IDX] return self.find_near_value(self.continuum, h) if __name__ == "__main__": replica = 2 kvlist = [("host1", "value1"), ("host2", "value2"), ("host3", "value3"), ("host4", "value4")] ch = ConsistentHash(kvlist, replica) print ch.continuum v = ch.get(sys.argv[1]) print v[0], ch.continuum[v[0]]
그런데!!!, 하나 더... 위에서 우리가 놓친 중요한 개념이 있습니다. hash ring이 우리가 의도한 것과 다르게 구성되는 경우가 언제가 될까요? 바로... Hash Ring을 구성하는 서버의 이름이 바뀌게 되는 경우입니다.
Consistent hashing을 많이 쓰는 libmemcached 의 경우 보통 서버 주소가 들어가게 됩니다. "1.1.1.1:11211", "1.1.1.2:11211", "1.1.1.3:11211" 그런데 이런 이름의 경우에 만약 1.1.1.2 서버가 문제가 있어서 새 장비를 받아야 하는데 그 장비가 1.1.1.4 의 ip를 가진다면? Hash Ring이 꼬여 버릴 수 있습니다. 이런 문제를 해결하려면 위의 직접적인 이름 대신에 alias 한 다른 이름으로 Consistent Hashing 을 구성해야 합니다. 즉 redis001, redis002, redis003, redis004 이런 이름으로 Hash Ring을 구성하고, 서버가 바뀌더라도 이 이름을 사용하고 Consistent hashing의 결과로 가져올 값만 다르게 가져오면 되는 것이죠.
바로 이해가 안되시더라도 곰곰히 생각해보시면 무릎을 딱 치시게 될껍니다.