Kafka 운영자가 말하는 Kafka Consumer Group

지난 글에 이어서 이번에는 Consumer Group이라는 주제를 가지고 설명하려고 합니다. 이 내용 역시 제가 처음 카프카를 접했을때, 정말 이해가 안되고 어려웠던 부분이었습니다. 컨슈머 그룹에 대해 국내 자료들을 검색했었는데, 안타깝게도 제가 이해하는데 도움이 될만한 글을 찾지 못하였습니다. 그래서, 제가 카프카를 처음 접하시는 분들이 컨슈머 그룹에 대한 개념을 잘 이해하실 수 있도록 간단한 예제와 그림을 추가하여 설명을 진행하도록 하겠습니다.
이 글을 처음 보시는 분은 이전 글을 한번 보시고 오시면 좋을 것 같습니다.
컨슈머 그룹
카프카에서는 컨슈머 그룹이라는 용어가 사용됩니다. 컨슈머 그룹에 대해 보다 쉽게 이해하기 위해 반드시 필요한 용어 몇가지만 살펴보도록 하겠습니다.
Consumer Group란? 컨슈머 인스턴스들을 대표하는 그룹 Consumer Instance란? 하나의 프로세스 또는 하나의 서버라고 할 수 있습니다. 여기에서는 이해를 돕기 위해서 하나의 서버로 설명하겠습니다. Offset란? 파티션안에 데이터 위치를 유니크한 숫자로 표시한 것을 offset이라 부르고, 컨슈머는 자신이 어디까지 데이터를 가져갔는지 offset을 이용해서 관리를 합니다.
위에서 설명한 간단한 이론을 바탕으로, 아래 그림을 살펴보겠습니다.
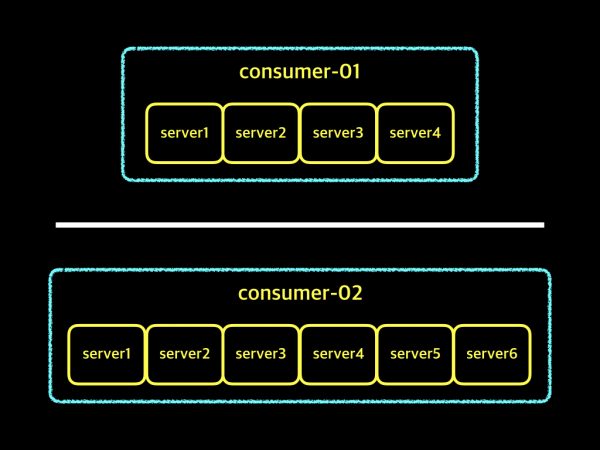
위 그림은 2개의 컨슈머 그룹을 나타내고 있습니다. 2개의 컨슈머 그룹은 서로를 구분하기 위한 이름으로 consumer-01, consumer-02이라고 되어 있고, consumer-01 그룹의 구성원은 4개의 서버로 구성되어 있으며, consumer-02 그룹의 구성은 6개의 서버로 구성되어 있습니다. 각각의 그룹내의 서버들끼리는 서로의 정보를 공유하고 있어, 만약 하나의 서버가 Down되더라도 다른 서버가 그 서버의 역할을 할 수 있게됩니다. 아래에서 좀더 자세히 살펴보겠습니다.
컨슈머 그룹의 목적
위에서 컨슈머 그룹이 어떻게 구성되어 있는지에 대해 설명드렸습니다. 제 생각에는 컨슈머 그룹에 대한 개념을 이해를 하시려면, 컨슈머 그룹이 왜 필요한지에 대해 알아보면 쉽게 개념을 이해할 수 있을거라고 생각합니다. 컨슈머 그룹을 사용하는 이유는 사용 방법에 따라 여러가지가 있을 수 있지만 저는 2가지의 이유를 설명을 드리도록 하겠습니다.
첫번째 이유는 가용성에 대한 부분입니다. 아래 그림을 보면서 설명하도록 하겠습니다.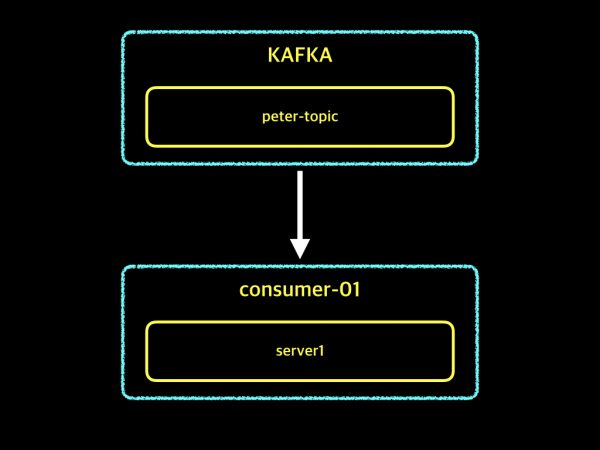
위 그림은 peter-topic이라는 토픽을 consumer-01 그룹이 데이터를 가져가고 있는 예제입니다. consumer-01 그룹은 하나의 컨슈머 인스턴스가 있습니다. 안정적으로 운영하던 중 컨슈머 인스턴스 server1이 장애가 발생하였습니다. 장애가 발생하였기 때문에 server1은 더 이상 자신의 역할을 못하게 되었고, 데이터를 가져오는 작업도 중단되었습니다. 하지만 위의 예제와 달리 컨슈머 그룹에서 1대의 컨슈머 인스턴스가 아닌 4대의 컨슈머 인스턴스로 운영중이었다면 어떨까요? 그리고 4대의 서버중 하나의 서버에서 장애가 발생하였다면 어떻게 되었을까요? 아래 그림을 보도록 하겠습니다.
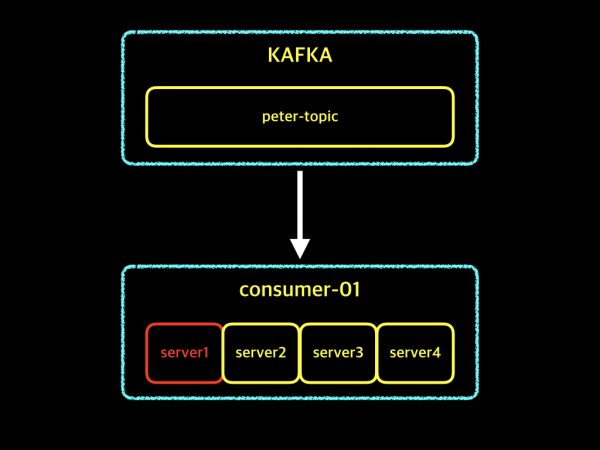
위 그림은 server1이 장애가 발생한 예제입니다. consumer-01 그룹은 4대의 서버로 구성되어 있어 server1만 제외되고, 나머지 서버 3대로 멈추지 않고 계속해서 작업을 이어갈 수 있습니다. 이러한 이유 때문에 우리는 컨슈머 그룹을 사용하고, 한대가 아닌 여러대의 컨슈머 인스턴스를 구성하여 안정성을 확보하는것이 필요합니다. 컨슈머 그룹을 사용해야 하는 충분한 이유가 되었죠? 이어서 2번째 이유에 대해 살펴 보도록 하겠습니다.
두번째 이유는 컨슈머 그룹들을 구분하고, 컨슈머 그룹들은 자신의 그룹에 대한 offset 관리를 하기 때문입니다. 개념적인 설명을 위해서 몇가지 조건을 가정해보겠습니다. A 사용자와 B 사용자가 있고, 둘다 동일한 토픽에 대해서 데이터를 가져가길 원하는 상황이며, 컨슈머 그룹이라는 것이 없다고 가정합니다. 컨슈머 그룹이 없기 때문에, 카프카에서는 컨슈머들을 구분할 수 없고, 또한 컨슈머들은 자신들만의 offset을 유지할 수 없습니다.
이해가 잘 안되시는 분들을 위해서 아래 그림을 보면서 설명을 이어가도록 하겠습니다. peter-topic에 1, 2, 3, 4라는 데이터가 들어가 있고, A 사용자가 1, 2, 3번까지 데이터를 가져갔습니다. 그리고는 다음에 가져갈 메시지는 4라는 자리 위치를 기록해 둡니다.
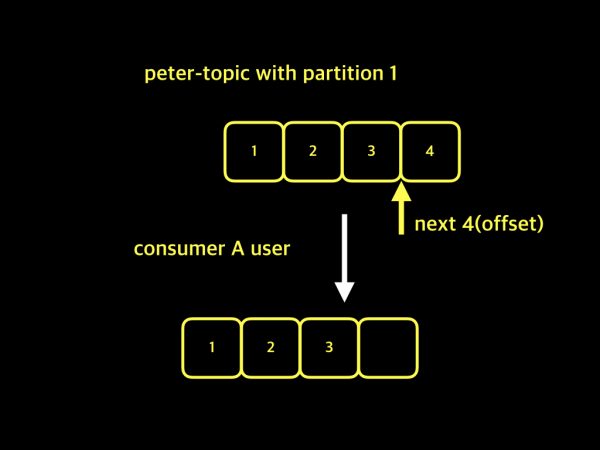
조금 전, 컨슈머 그룹이라는 것이 없다고 가정했으므로, 카프카는 컨슈머들에 대한 구분이 없습니다. 단지 컨슈머가 연결된 상태일뿐, A 사용자가 데이터를 가져가는 것인지, B 사용자가 데이터를 가져가는 것인지에 대한 구분이 없는 상태입니다. 그래서 B 사용자가 가져오기를 할 때, A 사용자가 데이터를 가져오면서 저장했던 offset 정보를 그대로 이용하게 됩니다. 설명 했던 내용을 그림으로 보도록 하겠습니다.
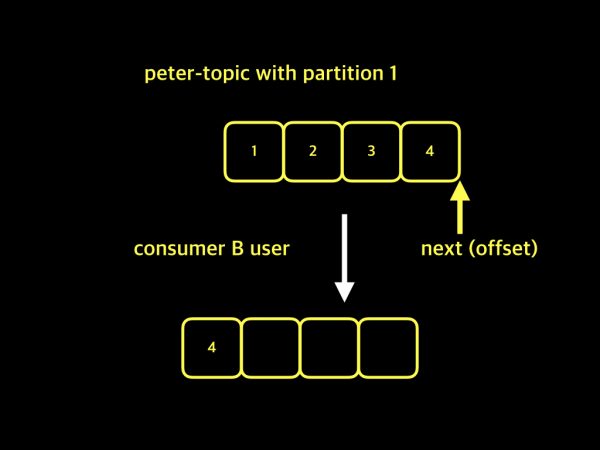
이미 A 사용자가 데이터를 가져오면서 next 메시지 4번이라고 기록하였기 때문에 위 그림처럼 B 사용자는 데이터 1, 2, 3은 가져오지 못한채 데이터 4만 가져오게 될 것입니다. 이 상황에서 또 다른 문제는 A 사용자가 데이터를 가져오기를 시도 할때입니다. B 사용자가 데이터 4번을 가져간 후 next 표시를 했기 때문에 A 사용자는 4번 데이터를 가져오지 못할 것 입니다. 이러한 이유 때문에 카프카에서는 컨슈머 그룹마다 컨슈머 그룹 네임을 지정하여 각각의 그룹들을 구분하고, 각각의 컨슈머 그룹별로 자신만의 offset을 관리 하게 됩니다. 컨슈머 그룹을 사용하게 되면, 동일한 토픽을 여러 컨슈머 그룹이 컨슘하더라도 서로 각기 다른 offset을 가지고 데이터의 손실 없이 가져가기를 할 수 있게 됩니다.
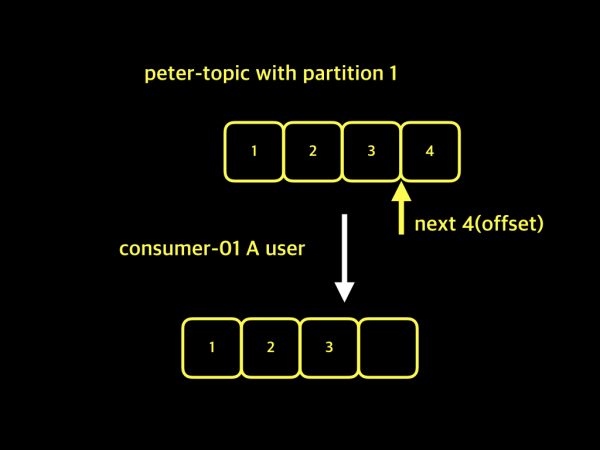
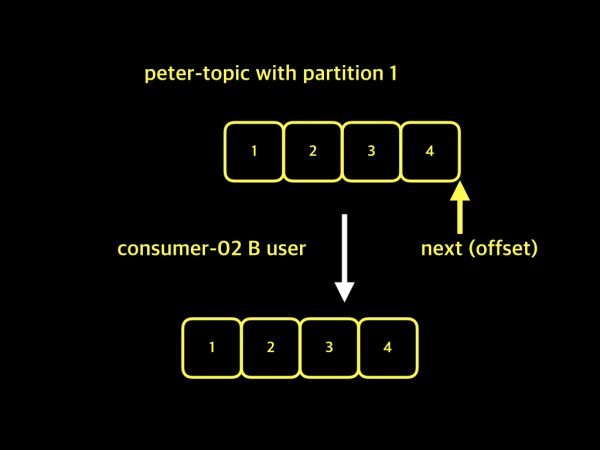
위 그림은 peter-topic이라는 하나의 토픽을 consumer-01, consumer-02 2개의 그룹이 가져가기를 하고 있는 예제입입니다. A 사용자는 consumer-01 그룹을 이용하여, 데이터 1, 2, 3을 가져온 상태이고 이후 4번 데이터를 가져올 것입니다. B 사용자는 consumer-02 그룹을 이용하여 1, 2, 3, 4 데이터를 가져오고 다음에 들어오는 데이터를 가져올 것입니다. 이렇게 카프카에서는 하나의 토픽이지만 2개 이상 여러개의 컨슈머 그룹이 데이터를 가져갈 수 있고, 각 그룹별로 서로 다른 offset을 유지할 수 있습니다. 여기서 중요한 점은 컨슈머 그룹을 만들때, 미리 동일한 이름의 컨슈머 그룹이 있는지를 체크 해보고 만드는게 중요합니다.
이제 컨슈머 그룹에 대해서 이해가 좀 되셨나요? 글을 읽기 전보다 이해가 많이 되셨을거라고 기대합니다. 컨슈머 그룹의 마지막 순서인 컨슈머 그룹과 파티션 수의 관계에 대해서 설명 진행 하도록 하겠습니다.
컨슈머 그룹과 파티션 수의 관계
이 주제에 대해 설명하기에 앞서 컨슈머 인스턴스의 제약사항에 대해 말씀드리고 진행하도록 하겠습니다.
카프카에서는 하나의 파티션에 대해 컨슈머 그룹내 하나의 컨슈머 인스턴스만 접근할 수 있다. -> 파티션에 대해 한명의 reader만 허용하여 데이터를 순서대로 읽어갈 수 있게 하기 위함(ordering 보장) 파티션 수보다 컨슈머 그룹의 인스턴스 수가 많을 수 없습니다.
위의 내용이 지금 바로 이해는 잘 안되실거라고 생각합니다. 위 내용에 대해 이해를 돕기 위해서, 아래 그림을 준비했습니다.
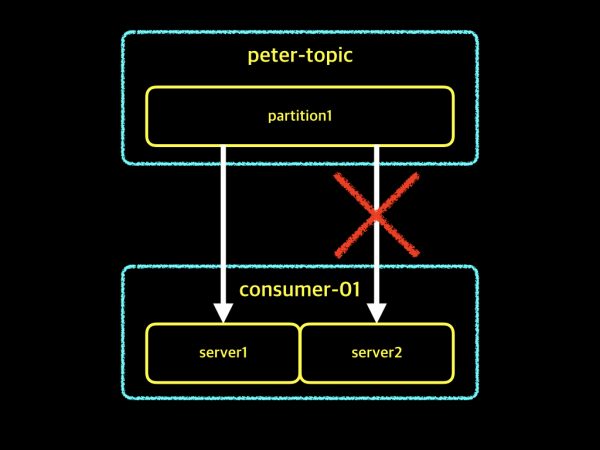
위 그림은 한개의 partition으로 구성된 peter-topic이라는 토픽이 있고, 컨슈머 인스턴스는 server1과 server2로 구성된 consumer-01이라는 컨슈머 그룹이 있습니다. 카프카에서는 하나의 파티션에 컨슈머 그룹내 하나의 인스턴스만 접근이 가능하기 때문에, 비록 컨슈머 인스턴스가 2개로 구성되어 있지만, server1만 접근하여 데이터를 가져오고 server2는 일을 하지 못하고 대기하고 있는 상태입니다. 컨슈머 인스턴스 하나는 대기 상태이므로, 예제의 상황이 효율적인 상황은 아닙니다. 제 생각에는 효율적인 구성을 위해서 토픽의 파티션 수와 컨슈머 인스턴스 수는 동일하게 맞추어 주거나 절반정도 수준으로 구성해주는 것이 좋습니다.
응용편으로 몇가지 예제를 들어보면서, 파티션과 인스턴스 수의 관계에 대해서 조금 더 자세히 알아보도록 하겠습니다.
4개의 파티션 + 2개의 컨슈머 인스턴스
peter-topic이라는 하나의 토픽은 4개의 파티션으로 구성되어 있습니다. 그리고 컨슈머 그룹은 consumer-01이라는 이름을 사용하며, 컨슈머 인스턴스 수는 2개입니다. 말씀드린 내용을 그림으로 표시하면 아래와 같습니다.
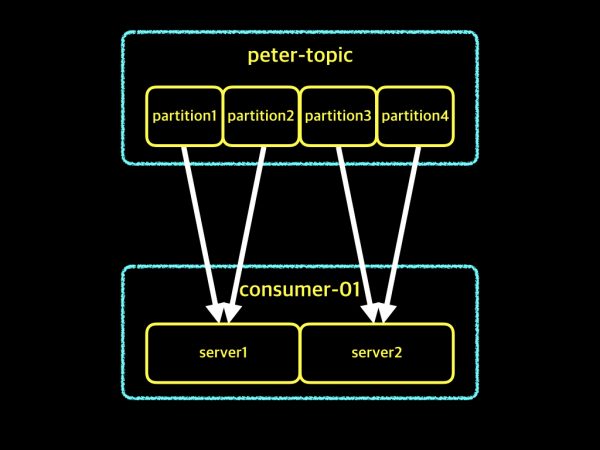
위 그림을 잘 보시면, 제가 앞서 설명드린 내용과 같이 하나의 파티션에 하나의 컨슈머 인스턴스만 연결되어 있습니다. 파티션수에 비해 컨슈머 인스턴스수가 적기 때문에 하나의 컨슈머 인스턴스는 2개의 파티션에 대해서 가져오기를 하고 있습니다. 만약 컨슈머 인스턴스가 2개가 아니라, 4개인 경우라면 어떻게 될까요?
4개의 파티션 + 4개의 컨슈머 인스턴스
위 그림에서 컨슈머 인스턴스를 2개 -> 4개로 늘리고, 위의 예제와 구분을 위해 컨슈머 그룹을 consumer-02라고 변경해보겠습니다. 그림으로 나타내면 아래와 같습니다.
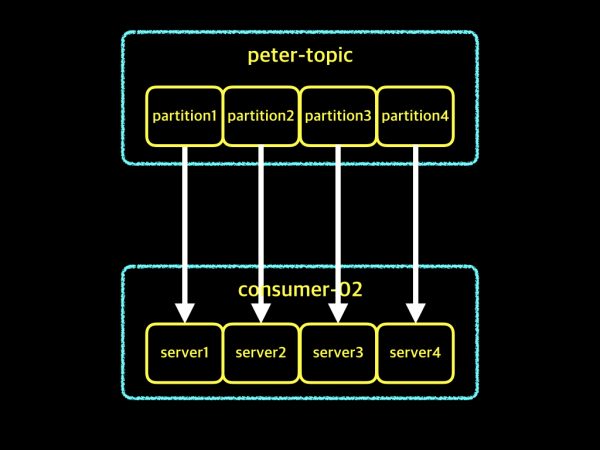
위 그림은 파티션 수 4개와 컨슈머 인스턴스 수 4개로 두 수가 같은 경우에 대한 예제입니다. 두 수가 동일하기 때문에 각각의 파티션과 컨슈머 인스턴스는 1:1로 연결되어 있습니다. 가장 이상적인 상태라고 할 수 있겠습니다. 그러면 앞에서 살펴본 컨슈머 인스턴스 2개인 경우와 지금 보고 있는 컨슈머 인스턴스 4개의 차이는 무엇이 있을까요? 정답은 바로 데이터를 가져오는 속도의 차이입니다.
예를들어, 각각의 파티션에 순서대로 1, 2, 3, 4라는 데이터가 들어있고, 컨슈머가 파티션에 있는 데이터를 가져올 때, 1초가 걸린다고 가정하겠습니다. 가정한 내용을 바탕으로, 그림을 추가하여 설명 이어가도록 하겠습니다.
컨슈머 인스턴스 2개 - 1초
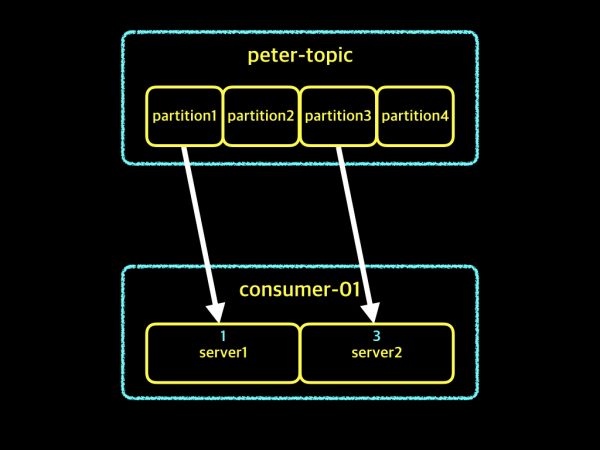
컨슈머 인스턴스 2개 - 2초
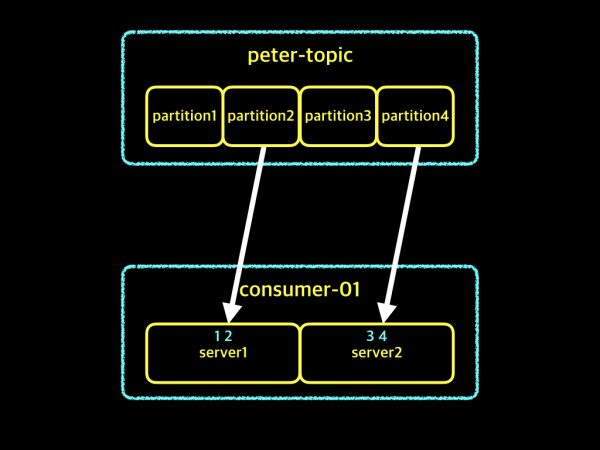
위 그림에서 보시는것처럼 consumer-01그룹은 파티션 1, 3의 첫번째 데이터 1, 3을 가져오는데 1초 소비하고, 파티션 2, 4의 첫번째 데이터 2, 4를 가져오는데 또 1초를 소비하여 1, 2, 3, 4 데이터를 전부 가져오는데 모두 2초를 소비하였습니다. 그럼 이어서 컨슈머 인스턴스가 4개인 consumer-02도 그림으로 살펴보겠습니다.
컨슈머 인스턴스 4개 - 1초
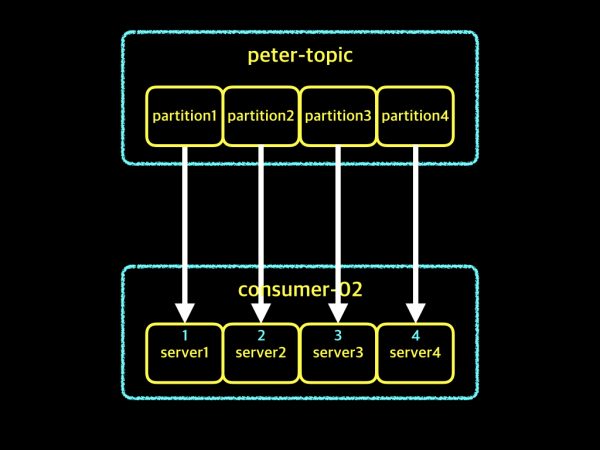
위 그림에서 보시는 것처럼 1, 2, 3, 4의 파티션에 각각 하나의 컨슈머 인스턴스가 데이터를 하나씩 가져오므로, consumer-02 그룹은 1, 2, 3, 4 데이터를 모두 가져오는데 1초가 소비되었습니다. 이렇게 토픽의 파티션 수가 많을 경우에는 그 수 만큼 컨슈머 인스턴스를 늘려서 데이터를 빠르게 가져올 수 있는 장점이 있습니다. 이러한 장점만 보고 파티션수를 무작정 늘리는 것은 좋지 않습니다. 토픽의 파티션 수는 토픽이 생성된 이후에 언제든지 늘릴 수 있지만, 절대로 줄일 수는 없습니다. 그래서, 일방적으로 파티션 수를 많이 늘리기 보다는 사전 테스트를 통해서 어느정도의 컨슈머 인스턴스 수를 유지했을 때, 데이터를 가져오는데 밀리는 증상이 없는지를 찾아서 해당 수만큼 파티션 수를 만들어주는 것이 효율적입니다. 자 이제 마지막 응용예제를 그림으로 만나 보겠습니다.
하나의 토픽에 2개의 컨슈머 그룹
컨슈머 그룹 응용편 마지막 예제로서, 하나의 토픽에 2개의 컨슈머 그룹이 연결되었을 때입니다. 응용편이기 때문에 토픽의 파티션수와 컨슈머 인스턴스 수를 모두 다르게 구성했습니다. 아래 그림을 살펴보겠습니다.
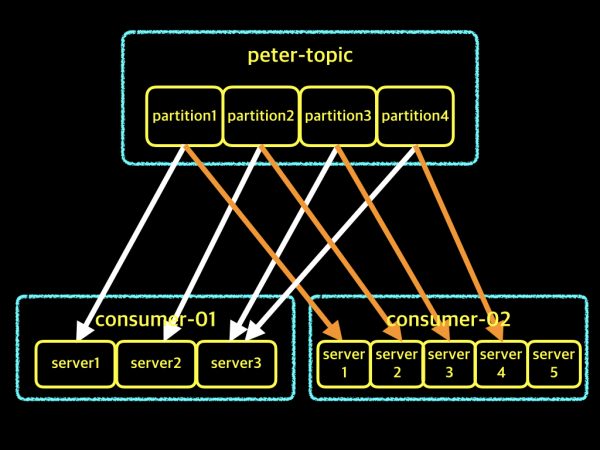
먼저 consumer-01 그룹에 대한 설명입니다. 4개의 파티션으로 구성된 peter-topic의 데이터를 가져오는데, 컨슈머 인스턴스 수는 3개입니다. 이런 경우에는 파티션 하나당 하나의 컨슈머 인스턴스가 연결되고, 토픽의 파티션 수보다 컨슈머 인스턴스 수가 부족하기 때문에 컨슈머 인스턴스 3개중의 어느 하나는 2개의 파티션에 대해서 데이터를 가져오게 됩니다. 설명을 드리기 위한 예제일뿐, 실제 서비스에 이렇게 구성하시게 되면 바람직한 구성은 아니겠죠?
다음은 consumer-02그룹에 대한 설명입니다. 앞서 설명드린 파티션 수보다 컨슈머 인스턴스 수가 많은 경우입니다. 하지만 이번에는 파티션 수와 컨슈머 인스턴스 수를 조금 더 늘렸습니다. 이런 경우에는 파티션 하나당 하나의 컨슈머 인스턴스가 연결되기 때문에, 마지막 컨슈머 인스턴스는 일을 하지 못하고 대기 상태로 남아 있게 됩니다. 이 역시 단지 설명을 위한 예제중의 하나일뿐입니다. 실제로 구성하실 때는 테스트를 해보시고 적정한 값으로 구성하시기를 권장합니다.
지금까지 몇가지의 예제를 가지고 컨슈머 그룹에 대해 개념적인 부분을 설명했습니다. 카프카를 처음 접하시면서 컨슈머 그룹때문에 잘 이해가 되지 않아 고민하시는 분들을 위해 부디 제 글이 조금이나마 도움이 되었으면 하는 바램입니다. 다음 내용은 연재하려고 생각해둔 몇가지가 있는데, 어떤 내용을 먼저할지 결정하지 못했습니다. 조금 고민해보고 다음 글도 작성하도록 하겠습니다. 긴 글 끝까지 읽어주셔서 감사합니다.