내가 본 Elasticsearch 5.0.0 신규 기능 몇 가지들

지난 10월 26일, 루씬 6.2.0을 기반으로 한 Elasticsearch 5.0.0 GA 버전이 공개되었다. 이 글에서는 Elasticsearch 5.0.0 릴리즈 노트에서 설명한 내용 중에서 내가 살펴 본 내용들을 간추렸다.
색인 성능
아래의 주요 변경 내용으로 인해 색인 성능이 25% ~ 80% 정도 향상된다.
블록 KD 트리 데이터 구조 적용
루씬 6.0에서 k-d 트리 공간정보 데이터 구조를 바탕으로 dimensional points라는 새로운 기능이 추가되었다. 다차원 데이터에서 성능향상을 꾀할 수 있을 뿐만 아니라, 1차원 숫자형 데이터에서도 효율적이다. Elasticsearch에서는 k-d 트리를 변형한 block KD 트리 구조를 사용하여, 숫자 기반 필드(byte, short, integer, long, float, double, ip, date)를 리팩터링했다.
lock 경합 완화
동일문서에 대해 동시에 업데이트하지 않도록 문서에 대한 업데이트 lock을 획득해야 한다. 이론적으로는 동일문서에 동시에 업데이트하는 경우에만 lock을 획득하기 위한 경합 과정이 필요하다. JDK의 ConcurrentHashMap을 사용하여 lock을 획득하기 위해 경합하는 과정을 완하하여, 15 ~ 20% 정도의 색인 성능이 항상되었다.
트랜스로그 fsync lock 조건 완화
트랜스로그를 fsync할 때 트랜스로그 쓰기 작업이 블록되지 않도록 수정, 비동기적으로 트랜스로그를 fsync할 때 나머지 색인 쓰레드에서 쓰기 작업이 블록되지 않도록 수정하는 등의 변경사항이 적용되었다. SSD에서는 성능이 큰 차이가 없지만, HDD에서는 최대 32%까지 색인 성능이 향상되었다.
"append-only + ID 자동 생성" 인덱스 구조의 경우
서버 로그와 같이 색인이 문서의 갱신 없이 추가(append)만 되는 구조라면, 문서 ID를 자동생성하는 경우 문서 버전을 조회하는 과정을 생략하여 성능이 향상된다.
GET 요청 처리 방식 변경
실시간으로 색인된 문서에 대해 GET 요청을 하는 경우, 문서를 트랜스로그에서 읽는 대신 세그먼트를 refresh하도록 변경했다. 이를 통해 인덱스 버퍼에 더 많은 메모리를 사용할 수 있고, GC 시간은 짧아진다.
인제스트 노드(Ingest Node)
문서를 색인하기 전에 데이터를 전처리할 수 있는 프로세서(processor)와 프로세스를 순차적으로 적용할 파이프라인(pipeline)을 추가했다. 그리고 이러한 전처리 과정만을 전담하는 인제스트 노드를 추가했다. 자세한 내용은 A New Way to Ingest - Part 1를 참고한다.
Painless 스크립트
스크립트 쿼리를 위한 Painless 스크립트 언어를 개발하여 스크립트 쿼리의 보안 이슈를 해결했다. 기본 스크립트 언어로 탑재했다. 관련 내용은 Painless: A New Scripting Language을 참고한다.
신규 데이터 구조
KD 트리 데이터 구조
k-d 트리를 변형한 block KD 트리 구조를 사용하여, 숫자형 데이터 타입을 변경했다. 자체 벤치마킹에서 아래와 같이 성능이 항상되었다.
- 쿼리 실행 시간: 36% 감소
- 색인 실행 시간: 71% 감소
- 디스크 사용량: 66% 감소
- 메모리 사용량: 85% 감소
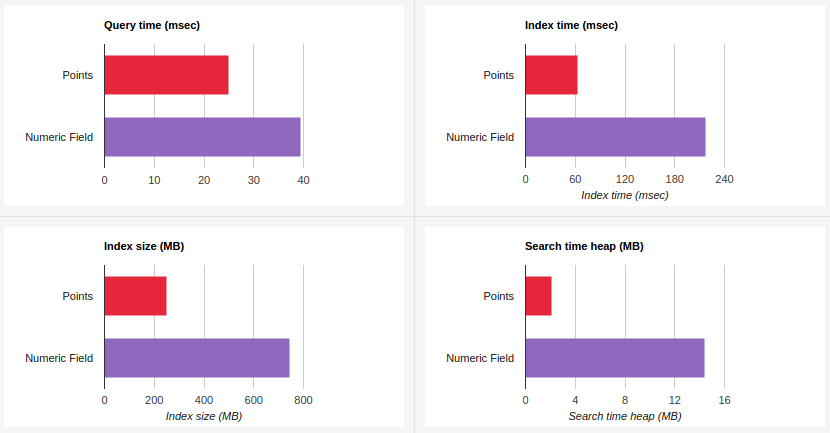
그림. 1차원 Points 타입과 예전 Numeric 타입의 성능 비교(출처: Elasticsearch, Searching numb3rs in 5.0)
half_float 필드 타입
부동소수점의 정확도를 낮추는 대신, 16비트를 사용하여 디스크 사용량 줄였다.
scaled_float 필드 타입
부동소수점을 scaling factor를 기준으로 정수 타입으로 저장했다. 정수 기반 압축 기능을 그대로 활용하여 디스크 사용량 줄였다.
text & keyword 필드 타입
기존에 string 타입에 대해 분석(analyze)이 필요한 경우는 2가지 유형이었다.
- analyzed: 전문 검색(full-text)이 필요한 경우
- not_analyzed: 키워드 검색, 정렬, 집계(aggregation)이 필요한 경우
5.0.0 버전부터는 각 유형을 목적에 맞게 text 타입, keyword 타입으로 분리했다.

그림. text, keyword 필드 타입 추가
자세한 내용은 Elasticsearch, Strings are dead, long live strings!에서 확인할 수 있다.
검색과 집계 관련
집계 성능 향상
time range query 리팩토링을 통한 집계 성능을 항상했다.
BM25: 검색 scoring의 새로운 방법
검색 scoring시 전통적인 TF/IDF 알고리즘 대신 최신의 BM25 알고리즘을 기본으로 채택했다.
deep 페이징을 해결하기 위한 search_after 구문 추가
검색 결과를 페이징 처리하는 경우, 검색 성능과 메모리 사용량은 “from + size”값에 비례한다. Elasticsearch 2.1 이전 버전에는 해당 값에 제한이 없었으나, Elasticsearch 2.1 버전에서 index 설정으로 index.max_result_window가 추가되었고, 기본값은 10,000이다. 따라서 페이징 처리시 "from + size"값이 10,000을 넘는 경우 "Result window is too large, from + size must be less than or equal to.."와 같은 에러 메시지가 발생한다. 따라서 페이징 처리를 하려면, “from + size” 값이 10000이 넘지 않도록 기능을 설계하거나, 성능을 낮추는 대신 해당 값을 높여야 한다.
5.0.0 버전에서는 검색 구문에 search_after이 추가되었다. from + size로 페이징을 처리하는 대신, 이전 검색된 결과의 마지막 문서의 정렬 값을 다음 검색 구문에 사용하는 방식이다. deep 페이징 문제로 성능이 나지 않는 경우 도움이 될 것 같으나, scroll과 달리 정렬 값의 상태를 저장하지 않으므로(stateless), 이전 문서의 정렬 값을 주고 받을 수 있도록 시스템을 설계해야 한다.
사용자 편의
“shout loud, shout early”를 모토로 잘못된 부분이 식별된 경우 빠르게 실패할 수 있게 했다. 이제 설정을 좀더 엄격하게 검사하며, 잘못된 설정이 있는 경우 즉시 에러를 알려준다. 기본 설정값 자체를 없앨 수도 있다(null). 쿼리 파라미터와 DSL도 엄격히 검사하여 파싱하며, 인식하지 못하는 파라미터가 있는 경우 예외가 떨어진다.
인덱스 생성 요청 후 클러스터 상태가 “wait_for_status=green”이 될 때까지 기다리는 대신, 인덱스 생성 요청은 인덱스가 사용가능해진 이후에 리턴된다. 샤드 재할당이 실패하는 경우 성공할 때까지 지속되는 대신, 5회만 시도한다.
안정성
부트스트랩 검사(bootstrap check)
부트스트랩 검사가 추가 되었다. 주요 설정들이 잘못된 경우, 상용 모드에서는 서버가 실행되지 않으며, 개발 모드에서는 경고 메시지를 출력한다. 상용 모드와 개발 모드는 transport 프로토콜이 바인딩한 네트워크 인퍼페이스가 루프백(loop-back) 주소인지 아닌지에 따라 결정된다.
상용 모드로 가기전 반드시 설정해야 할 항목들은 아래와 같다.
- path.data 인덱스 저장 위치
- path.logs 로그 저장 위치
- cluster.name 클러스터 명
- node.name 노드 명
- bootstrap.memory_lock JVM 메모리 swapping lock 여부. true로 설정
- network.host 노드가 바인딩하거나 외부 노드와 통신할 때 사용할 publish 네트워크 주소
- discovery.zen.ping.unicast.hosts 클러스트 구성시 노드들이 서로를 찾을 때 discovery router로 사용할 노드 리스트
- discovery.zen.minimum_master_nodes 클러스터의 마스터 노드 최소 개수
- node.max_local_storage_nodes 하나의 머신에서 여러 대의 노드를 실행한 경우 같은 path.data를 사용하지 않도록 1로 설정
이어서...
개인적으로 가장 관심이 가는 변경사항은 기본 검색 scoring 알고리즘을 TF/IDF에서 BM25로 변경한 부분이다. BM25 알고리즘에 대해서는 다음 글에서 좀 더 자세히 살펴보려고 한다.
참고자료
- Elasticsearch 5.0.0 released
- Elasticsearch, 5.0.0 Combined Release Notes
- WIKIPEDIA, k-d tree
- Elasticsearch, Multi-dimensional points, coming in Apache Lucene 6.0
- Elasticsearch, Avoid sliced locked contention in internal engine #18060
- Elasticsearch, FSync translog outside of the writers global lock #18360
- Elasticsearch, Fsync documents in an async fashion #20145
- Elasticsearch, Use _refresh instead of reading from Translog in the RT GET case #20102
- Elasticsearch Reference [5.0] > Processors
- Elasticsearch Reference [5.0] > Pipeline Definition
- Elasticsearch Reference [5.0] > Ingest Node
- A New Way to Ingest - Part 1
- Painless: A New Scripting Language
- Elasticsearch, Searching numb3rs in 5.0
- Elasticsearch, Strings are dead, long live strings!
- Elasticsearch, Instant Aggregations: Rewriting Queries for Fun and Profit
- Elasticsearch: The Definitive Guide [2.X] >What Is Relevance?
- Elasticsearch: The Definitive Guide [2.X] > Theory Behind Relevance Scoring
- Elasticsearch: The Definitive Guide [2.X] > Lucene's Practical Scoring Function
- Elasticsearch, Imporeved Text Scoring with BM25
- stackoverflow, Elasticsearch 2.1: Result window is too large (index.max_result_window)
- Elasticsearch Reference [5.0] > Search After
- Elasticsearch Reference [5.0] > Important Elasticsearch configuration