Presto를 이용하여 Google Sheets와 mysql 등 DB 데이터 JOIN 하기

데이터를 보는 많은 분들이 특징이 내가 만든 또는 내 PC의 엑셀에 있는 데이터하고 DB와 같이 서버에 있는 데이터하고 같이 볼 수 있는 방법이 없나? 라는 요구사항입니다. 이번 글에서 비슷하게 나마 요구사항을 만족시킬 수 있는 방법을 소개해 드리겠습니다.
최근 지인의 요청으로 AWS 환경을 좀 볼 수 있는 시간을 가졌습니다. 지인의 서비스는 작년 하반기 부터 갑작스럽게 성장하면서 데이터가 많아지고 분석의 요구도 많아지는데 전문적으로 이를 처리할 수 있는 개발 인력이나 조직은 거의 없는 상태였습니다. 물론 AWS의 좋은 서비스 덕분에 그럭저럭 운영은 하고 있었지만 한계에 부딪히고 있었는데 이런 저런 니즈가 서로 부합되어 잠시 도움을 주게 되었습니다.
대략 데이터 발생원으로 부터 정제된 형태의 데이터로 저장하는 데이터 파이프라인을 구성하고 이를 기반으로 SQL 등으로 쉽게 분석할 수 있는 체계를 만드는 작업이었습니다.
이번 글에서는 Google Sheet의 각 파일과 MySQL 또는 HDFS, S3 등에 저장된 데이터와 JOIN을 할 수 있는 방법에 대해 간단하게 소개해 드리겠습니다.
Presto
Presto는 이전에도 여러번 포스팅을 한 분산 환경에서 여러 데이터 소스의 데이터를 빠르게 SQL로 조회할 수 있는 기능을 제공하는 오픈 소스입니다.
원래 부터 직접 설치하고 사용하는 것을 좋아하는 스타일이라 2015년 AWS를 사용할 때나, 2017년부터 알리클라우드를 사용할 때나 모두 직접 설치해서 사용하였는데 최근 다시 AWS를 사용할 일이 있어 조금 더 살펴 보게 되었습니다.
AWS 환경에서 SQL을 이용하여 대규모 데이터를 조회하는 경우 redshift를 이용할 수도 있습니다. 이번에 작업을 하면서 Redshift와 Presto를 비교한 몇가지 문서를 찾아 보았는데 성능 관련해서는 참고할 만한 자료인 것 같습니다.
- https://www.concurrencylabs.com/blog/starburst-presto-vs-aws-redshift/
- https://www.holistics.io/blog/grab-move-redshift-to-presto/
다만 성능 테스트는 누가 어떤 의도를 가지고 했느냐에 따라 조금씩 달라질 수가 있으니 이 자료에서 제시하는 성능 수치가 모든 상황에는 맞지 않다는 것을 유념해 주셨으면 합니다. 직접 성능 테스트를 하는 것이 가장 좋겠죠.
2개의 오픈소스 Presto 프로젝트
Presto 가 Google Sheet를 지원한다는 소식을 듣고 원래 사용하는 Presto 프로젝트 사이트를 방문했는데 전혀 그런 내용을 없었습니다.
하나는 prestodb.io 이고 다른 하나는 prestosql.io 입니다. 원본 프로젝트는 prestodb 이고 페이스북에서 만들어서 오픈소스로 공개한 프로젝트 입니다. 아직도 페이스북에서 왕성하게 코드를 만들고 있어 지속적으로 릴리즈 되고 있는 프로젝트입니다. 이 글을 쓰는 시점에 prestodb의 버전은 0.237 이고, prestosql은 340 입니다. 왜 이렇게 두개의 프로젝트가 생성 되었는지는 모르겠지만 prestosql 쪽이 커넥터 부분에서는 훨씬 더 많이 지원하고 있습니다.

지원하는 커넥터를 보면 prestosql이 좀 더 상업적인 성향을 지향하고 있는 느낌입니다. AWS나 Google Clould의 서비스를 지원하고 있고 Oracle 등도 지원하고 있습니다.
EMR에서 제공하는 Presto는 prestodb.io 버전의 Presto를 지원하고 있기 때문에 Google Sheet 연동이 필요한 요구사항에는 적합하지 않아 직접 설치하였습니다.
Google Sheet 연동
Presto에서 Google Sheet를 연동하는 것은 공식 문서에도 잘 나와있어 특별할 것은 없습니다. 대략 순서는 다음과 같습니다.
1. Google Sheet API를 enable 시켜 Google Sheet 접근을 API를 통해서 접근할 수 있도록 한다. 이 부분에 대한 글은 아래 글을 자세하게 설명이 나와 있습니다.
2. 이 작업을 하고 나면 Credential 정보를 가져올 수 있는데 키 값을 Presto가 설치된 서버에 파일로 저장합니다.
-
1 2 3 4 5 6 7 8 9 10 11 12{ "type": "service_account", "project_id": "api-aaaaa", "private_key_id": "d458af...", "private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADANQF2Tk8c=\n-----END PRIVATE KEY-----\n", "client_email": "babokim@api-aaaa.iam.gserviceaccount.com", "client_id": "100465437764", "auth_uri": "https://accounts.google.com/o/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/popit-presto@api-8568.iam.gserviceaccount.com" }
3. 다음은 Google Sheet의 목록을 Presto의 테이블로 매핑하는 정보를 관리하는 시트를 만듭니다. Presto 문서에도 나와 있는데 예제를 참고해서 새로운 Google Sheet를 하나 만듭니다. 이 시트의 한 라인에 있는 정보가 Presto 에서는 하나의 테이블로 나타나게 됩니다. 예제에서 보는 것과 같이 첫번째 컬럼은 Presto에서 나타나게 될 테이블 명이 되고, 두번째 컬럼은 이 테이블의 데이터가 있는 Google Sheet의 Sheet ID를 입력합니다. 하나의 데이터 파일에 여러개의 Sheet 가 있는 경우 기본 값은 첫번쨰 Sheet를 사용하고 특정 Sheet를 지정하는 경우 “#” 이후 Sheet 명을 입력합니다.
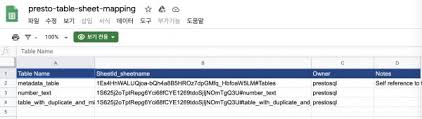
4. 테이블 매핑 시트 공유: 3번에서 만든 테이블 매핑 시트를 1번 Google Sheet API를 설정한 계정에서 접근 가능하도록 공유 설정을 해야 합니다. 2번 Credential에 내용중 client_email이 있는데 이 계정에 읽기 권한으로 공유를 하면 됩니다.
5. Presto의 catalog 설정(etc/catalog 하위 디렉토리)에서 다음과 같이 Google Sheet Connector를 설정합니다. Presto는 catalog 설정 파일명이 catalog 명으로 사용되는데 필자의 경우 gs.properties 파일을 생성하여 다음과 같이 설정하였습니다.
1 2 3connector.name=gsheets credentials-path=/etc/presto/google-sheets-credentials.json metadata-sheet-id=1oQiSn7Q9mi2BP-_oQaIgGmvNPggse17F3t046eGT_ZI#Tables
connector.name은 상수 값으로 gsheets 를 입력하고 credentials-path는 2번에 저장한 파일을 지정합니다. metadata-sheet-id는 3번에서 만든 테이블-시트 매핑 정보가 있는 시트의 ID를 설정합니다.
6. Presto의 경우 분산된 각 Worker 들에서 데이터에 접근을 하기 때문에 각 Worker로 2번에서 생성한 파일과 5번에서 생성한 파일을 배포합니다.
7. Presto 재 시작 후 다음과 같은 질의로 테이블 목록 및 데이터 조회를 할 수 있습니다.
- show tables from gs.default;
- select * from gs.default.orders;
이렇게 구성하게 되면 내 PC에 있는 엑셀 파일을 Google Sheet로 업로드 하여 MySQL 등 DB에 있는 데이터와 과 자유롭게 JOIN을 할 수도 있고, SQL을 이용하여 쉽게 데이터를 핸들링 할 수 있습니다.
Presto는 catalog -> schema -> table 형태로 구성되는데 Google Sheet Connector의 경우 schema 명은 자동으로 "default"를 사용하게 됩니다.
새로운 시트(테이블)을 추가하는 경우 1번에서 생성한 매핑 시트에 Row를 추가하기만 하면 자동으로 Presto에 나타납니다.
특이한 문제 발생 및 해결
Presto Shell이나 JDBC 연결 등에서는 문제없이 잘 실행 되었는데 구글이 인수한 대용량 데이터에 대한 BI 도구인 looker와의 연동에서 문제가 발생하였습니다. looker 웹 관리 도구에 있는 SQL Runner에서 아무런 정보가 나타나지 않고, looker 가 실행하는 일부 질의에서 다음과 같은 예외를 발생 시켰습니다.
1Java::JavaSql::SQLException: Query failed (#20200725_051350_00534_qdk4u): Schema not present - Optional.empty
대략 문제를 확인해보니 looker의 경우 연결된 데이터베이스(여기서는 Preso)의 모든 Catalog, Schema의 정보를 가져와서 처리하도록 되어 있었습니다. 대략 다음과 같은 질의를 실행해서 정보를 조회하고 있었습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13SELECT DISTINCT CONCAT(CONCAT(table_catalog, '.'), table_schema) as table_schema, table_name FROM ( SELECT * FROM es.information_schema.tables UNION ALL SELECT * FROM gs.information_schema.tables UNION ALL SELECT * FROM hive.information_schema.tables UNION ALL SELECT * FROM jmx.information_schema.tables UNION ALL SELECT * FROM mysql.information_schema.tables UNION ALL SELECT * FROM system.information_schema.tables);
hive, mysql, es 등 모든 정보를 가져오고 있습니다. 이 지점에서 Presto의 Google Sheet Connector의 스펙과 충돌이 발생합니다. Google Sheet Connector 문서의 API Usage Limits 다음과 같은 문구가 있습니다.
Running queries on the information_schema.columns table without a schema and table name filter may lead to hitting the limit, as this requires fetching the sheet data for every table, unless it is already cached.
즉, Google Sheet API는 시간당 API 호출 건수 제약이 있는데 information_schema의 columns 테이블 등에 where 조건 없이 질의를 하게 되면 API 호출 건수를 초과할 수 있기 때문에 하지 말라는 것입니다. 매핑된 테이블이 많은 경우 이 질의는 모든 테이블(Google Sheet 파일)을 열어서 컬럼 내용을 확인하도록 구현이 될 것입니다. 즉, 테이블이 많을 수록 API 호출이 많아진다는 것입니다. 이 문구만 보면 단순히 그렇게 하지 말라는 정도로 되어 있는데 실제 Connecrtor에서 where 조건이 없으면 Empty 값을 반환하고 있습니다.
필자의 지인이 사용하는 환경에서는 Sheet가 많지 않기 때문에 문제가 될 것이 없어서 일단 Connector 소스 코드를 수정해서 재 배포하면 형태로 문제를 해결 했습니다. 수정한 부분은 io.prestosql.plugin.google.sheets.SheetsMetadata 클래스의 다음 부분입니다.
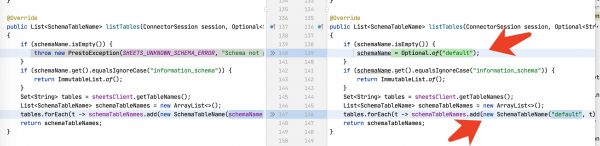
혹시 동일한 오류를 겪는 분이 있으시면 참고하세요.
마치며
데이터 분석이라고 하여 인공지능, 머신러닝 등을 생각할 수도 있겠지만 기업 내의 SQL만 잘 활용해도 좋은 분석 결과와 서비스의 수익을 확대하는데 많은 도움을 받을 수 있습니다. 실제 지인의 회사도 이런 분석을 통해 광고 효과 분석과 각 캠페인 별로 수익에 대한 추적, A/B 테스트 등의 효과 분석 등 다양한 분석을 수행하고 있습니다. 이번 글에서는 이런 SQL 분석에서 쉽고 빠르게 사용할 수 있는 도구 중의 하나인 Presto를 활용하는 하나의 방법에 대해 소개 드렸습니다.