Spark2.0 New Features(2) Structured Streaming - 1편

Structured Streaming
Structured Streaming은 Spark2.X에서 새롭게 나온 Spark SQL엔진 위에 구축된 Stream Processing Framework이다. Structured Streaming은 기존에 Spark APIs(DataFrames, Datasets, SQL)등의 Structured API를 이용하여 End-to-End Streaming Application을 손쉽게 만들 수 있다. 또한 input data에 대한 Streaming데이터 처리 후 checkpointing과 write-ahead logs를 통한 exactly-once하고 fault-tolerance한 프로세싱을 지원한다. 또한, 늦게 오는 데이터에 대해 처리가 가능하며 Continuous Processing Mode로 1ms미만의 latency를 제공한다. 각각에 대해서는 개별 글을 통해 공유해 보도록 하겠다.
Structured Streaming의 주요한 아이디어 중 하나는 input으로 들어오는 stream데이터에 대해 table형식으로 append를 할 수 있다는 점이다. 즉, DataFrame을 통해 streaming으로 들어오는 데이터를 질의하거나 집계하거나 변형하는 작업등이 가능하다.
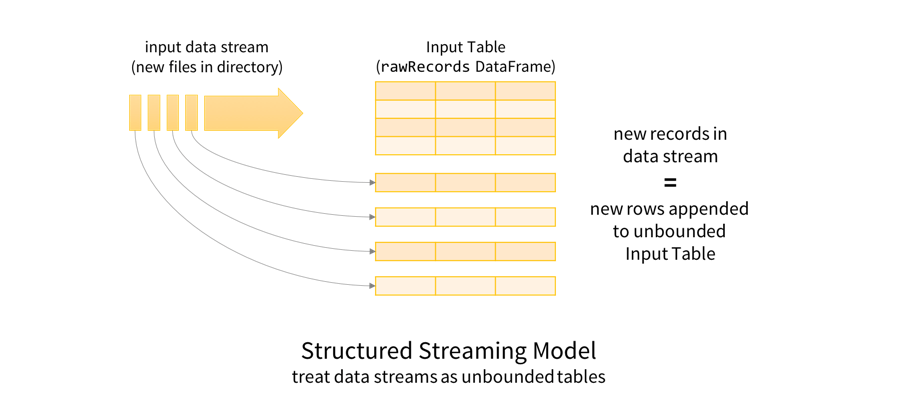
출처 - https://spark.apache.org/docs/2.3.0/structured-streaming-programming-guide.html
그럼 우선 Spark Streaming에 대해 간략하게 알아보자.
실시간 Streaming Framework에 있어서 Spark Streaming의 position은 micro-batch 영역이다. in-stream으로 들어오는 데이터에 대해 작은 batch로 만들어서 RDD연산을 수행한다.
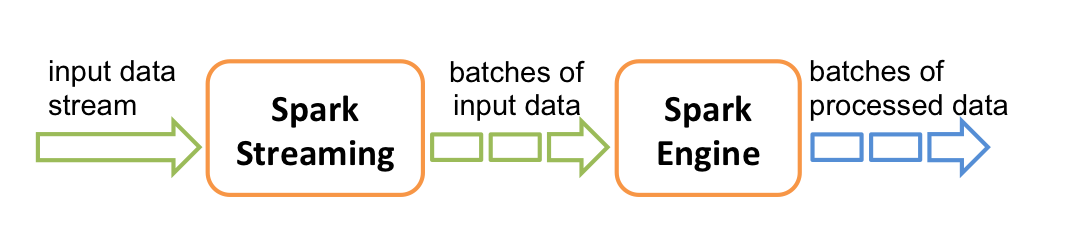
출처 - https://spark.apache.org/docs/2.3.0/streaming-programming-guide.html
위와 같이 작은 batch는 spark engine을 통해 처리되고 external system(HDFS, NoSQL 등)에 최종 결과가 write된다.
다음은 https://spark.apache.org/docs/2.3.0/streaming-programming-guide.html 에서 가이드하는 streaming application code example이다.
아래의 예제에서 Spark Streaming의 socket stream을 receiver로 만들고 9999 port로 socket을 binding하는 application이다.
input stream으로 들어온 socket data를 1초 단위의 small batch로 처리하게 되어 있는데 flatMap을 이용하여 입력 받은 데이터를 공백 단위로 split한다. 여기까지 읽었다면 대충 감이 올것이다. big data 계의 hello world같은 word count예제이다. split된 데이터는 각 word를 count하여 pairs로 만들고 최종적으로는 reduceByKey를 통해 입력받은 문장의 tokenizing한 word를 count하게 된다.
예를 들면 1초 내 input 이 hello world hello word라면 최종 결과 값의 최종 RDD는 (hello,2) (world,1) (word,1)이런식으로 생성된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3 // Create a local StreamingContext with two working thread and batch interval of 1 second. // The master requires 2 cores to prevent from a starvation scenario. val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) // Create a DStream that will connect to hostname:port, like localhost:9999 val lines = ssc.socketTextStream("localhost", 9999) // Split each line into words val words = lines.flatMap(_.split(" ")) import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3 // Count each word in each batch val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) // Print the first ten elements of each RDD generated in this DStream to the console wordCounts.print() ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate
Streaming Application의 Complexity
Spark Streaming을 개발하고 운영해 본 사람이라면 공통적으로 느끼는 점은 다음과 같을것이다.
점점 복잡해 진다 OTL
모든 시스템이 그렇듯이 데이터 처리하는 시스템 또는 프로그램도 살아있는 생물과 같다. 일부로 시스템을 내리지 않는 이상 시스템은 유지보수와 개선을 반복하기 마련이다. 실시간 스트리밍 시스템 역시 시작은 작았으나 나이가 들 수록 점차 거대해지고 복잡해진다. 이것 역시 전형적인 실시간 스트리밍 어플리케이션의 패턴이다. 실시간 Application을 릴리즈 하고 운영모드로 전환되면 추가 요구사항이 늘어나고 데이터 처리량도 증가하며(그나마 이중에선 행복한 비명) 이런저런 이유로 비지니스 로직이 복잡해 지게 된다. 실시간 Application을 개발하고 운영함에 있어 필자가 겪었던 문제점은 다음과 같다.
![[출처-https://www.winshuttle.com/blog/6ways-dirty-data/]](https://www.popit.kr/wp-content/uploads/2018/05/xdirty-data.jpg.pagespeed.ic_.upFd-lUVw0.jpg)
[출처https://www.winshuttle.com/blog/6ways-dirty-data/]
- dirty한 데이터 : 근본도 없이 던져지는 데이터들, 그리고 spec에 맞지 않는 데이터, 그리고 잊을만하면 변하는 데이터 spec
- 늦는 데이터 : 사람도 가끔 늦을때 있지만, input data가 늦는 경우(human error 또는 기타 error)도 drop해 버리고 싶지만.
- 이것저것 로직이 들어간다 : 실시간에서 뭘 그렇게 하고 싶은게 많은지 static 데이터도 join해야 하고 machine learning도 넣어달란다.
- external system에 데이터 저장하려는데;;; 자꾸 여기 저기 넣어달란다. 근데 그러면 그럴수록 데이터를 sink하는데 지연이 발생한다.
- data locality와 DAG schedule 을 고려한 미려한 programming - 순전히 개발자 경험과 노하우등 역량에 달려 있음
Streaming Application의 전형적인 패턴은 다음과 같다.
- input 데이터를 읽어온다. 읽어올때 실패가 발생할 수 있으므로 어디까지 처리했는데 offset을 관리한다.
- input 데이터를 처리한다. 이때, 집계를 하거나 filter하거나 필요로 하는 데이터를 생성한다. 필요시 다른 데이터와 조인을 해야 한다.
- 처리된 데이터를 저장한다.
이번 글에서는 실시간 End-to-End application으로 손쉽게 구현할 수 있는 방법에 대해 알아보려 한다.
DataFrame으로 데이터를 읽고 처리하는 batch query를 생각해 보자. json데이터를 path에서 읽어서 input DataFrame으로 만들고 필요로 하는 컬럼과 조건을 select한 다음 destination path에 parquet format으로 write하는 간단한 예제이다.
1 2 3 4 5 6 7 8 9input = spark.read .format("json") .load("source-path") result = input .select("device","signal") .where("signal > 15") result.write .format("parquet") .save("dest-path")
위의 코드는 1회성 batch code이다. 만약 source-path에 주기적으로 데이터가 적재된다고 하자. 그럼 다음과 같이 streaming query를 작성하여 사용할 수 있다.
1 2 3 4 5 6 7 8 9input = spark.readStream .format("json") .load("source-path") result = input .select("device","signal") .where("signal > 15") result.writeStream .format("parquet") .start("dest-path")
batch든 streaming 이든 JSON 데이터의 경우 key,value format으로 이 경우 Spark의 DataFrame이 별도 처리 없이 데이터를 읽어올 수 있다. 무엇이 바뀌었는지 찾을 수 있겠는가? 아주 미세하게 method만 변경되었다. read는 readStream으로 write는 writeStream으로 save는 start로 변경 되었다. 위와 같이 코드가 변경되면 input file path에 대해 자동적으로 데이터 변경이 있을때마다 batch-like하게 스트리밍 처리가 된다.
데이터 처리에 대해 key 또는 time widow 기반으로 집계하는 예는 다음과 같다.
1 2 3 4 5 6 7 8 9events .groupBy("key") .count() events .groupBy(window("timestamp", "10 mins")) .avg("value") events .groupBy('key,window("timestamp","10 mins")) .agg(avg("value"),corr("value"))
- 첫번째 코드의 경우 events 데이터 프레임에 대해 key에 대해 group by를 수행하고 count를 가져온다.
- 두번째 코드의 경우 events 데이터 프레임에 대해 10분 단위의 time window로 평균 value를 가져온다.
- 세번째 코드의 경우 events 데이터 프레임에 대해 10분 단위의 time window로 key와 groupBy한 후 평균 value와 corr라는 UDAF를 호출하여 multiple로 aggregation가능하다.
위의 코드를 보면 RDD programming 방식보다 훨씬 더 직관적이고 간결하지 않은가?
Dataframe 기반의 Streaming 방식을 사용하게 되면 이점은 다음과 같다.
- 위에 언급했던 문제중에 data locality와 DAG schedule 을 고려한 미려한 programming 을 개선할 수 있다. DataFrame(DataSet, SQL포함)의 경우 내부적으로 실행 계획을 최적화 하는 Catalyst Optimizer를 사용하고 있다. RDD programming보다는 DataFrame기반 개발이 유지보수 측면에서나 성능적인 측면 모두에서 이점이 될것이다.
- End-to-End application개발의 용이성이다. read/transform/write에 대해 high-level API를 지원하기 때문에 손쉽게 실시간 Application을 개발할 수 있다. 필자의 경우 input data의 JSON 처리(클린징,변환,집계,예외처리 with Dirty Data)에 RDD programming으로 힘을 많이 쏟았다. DataFrame API나 UDF/UDAF를 사용하면 좀 더 간결하게 구현이 가능하다. 물론 성능상의 이점은 덤덤덤...
다음 편에서는 Structured Streaming에서 이야기하는 exactly-once 하고 fault-tolerance 한 프로세싱(으응?)에 대해서 알아보자