Selenium 으로 Web Scraping 아이 해봤니?

본 글은 ‘테스트 자동화 도구’로 잘 알려진 'Selenium (셀레니움)'을 이용하여 Java + Spring 환경에서 'Web Scraping' 을 구현해 본 경험에 대한 이야기 입니다.
배경
왜 하게 됐는가?
업무 상 특정 웹사이트의 정보를 Scraping 해오는 신규 시스템을 설계하고 개발 하였습니다.
왜 Selenium 을 선택 했는가?
개발을 막 시작한 당시, Scraping 대상 웹사이트는 JavaScript 가 실행되어 동적으로 랜더링된 웹요소(Web Element) 중 하나를 로그인 폼(Form)의 필수 입력 값으로 사용하고 있었는데요, 이처럼 Scraping 에 필요한 필수 웹요소가 JavaScript 에 의해 동적으로 랜더링 되는 경우 Jsoup(Java), Beautifulsoup(Python) 과 같이 JavaScript 해석기를 포함하지 않은 도구들로는 Scraping 이 불가능 합니다.
이러한 경우 Scraping 이 가능하도록 지원해 주는 도구들이 몇가지 있는데요,
먼저 저희 회사의 경우 Java + Spring 이 표준 개발환경인데, 해당 환경에서 Batch 기반의 Web Scraping 시스템을 개발하여 운영 할 경우 기본적으로 얻을 수 있는 장점이 많이 있습니다. 또한, PhantomJS 의 경우 기술 선정을 위한 Prototyping 과정 중 국내 유명 웹사이트 몇 곳에서 JavaScript 실행 시 에러가 발생하는 현상이 있었으며, 아키텍처 상 별도의 Middleware 를 구축하고 API 요청을 통해 JavaScript 의 수행 결과를 얻어오는 Splash 의 경우 관리 포인트가 증가하는 것에 대한 부담이 있었습니다. 그래서, 최종적으로 'Selenium + 브라우저' 기반의 Scraping 방식을 선택하게 되었습니다.
Selenium 을 이용한 Web Scraping 의 경우 성능이 이슈가 되기도 하는데요, 이 부분은 몇가지 튜닝을 통해 만족할 만한 수준을 얻을 수 있었습니다. 또한, Selenium 은 Headless 타입인 PhantomJS, Splash + Scrapy 와 달리 실제 구동되는 화면을 눈으로 직접 확인 할 수가 있어 개발 시 디버깅 측면에서 많은 도움이 됩니다. (물론, Headless 타입 또한 지원합니다.)
그런데, 당황스러운 것은 얼마 전 Scraping 대상 웹사이트가 친절?하게도 로그인 페이지의 보안수준을 낮추는 작업을 진행 하였고, 그로 인해 현재는 정적인 Web Scraping 이 가능한 상태가 되었다는 것 입니다. ㅡ,.ㅡ;
Web Scraping 방식
Scraping 시 JavaScript 의 실행이 필수인지에 따라 그 방식이 결정됩니다.
Static Scraping
JavaScript에 대한 실행 없이도 필요한 모든 정보가 표현되고 동작하는 정적인 웹사이트의 경우 Jsoup, Beautifulsoup 등을 이용해 빠르고 가볍게 Scraping 할 수 있습니다.
Dynamic Scraping
반드시 JavaScript 실행을 거쳐야지만 필요한 모든 정보가 표현되고 동작하는 동적인 웹사이트의 경우 JavaScript를 실행할 수 있는 브라우저(Selenium 연동) 또는 그에 상응하는 무엇인가가 있어야 Scraping 이 가능 합니다.
Hybrid Scraping
정적 & 동적 웹페이지를 Scraping 할 때 사용하는 각각의 기술을 적절히 조합하여 사용하는 방식으로써, 개인적으로 'Hybrid Scraping'이란 이름을 최초로 한번 붙여 보았습니다. (샘플코드는 아래 ‘구현 > [부록]’ 부분에 있습니다.)
참고로 자신이 사용하는 브라우저의 JavaScript 실행 기능을 Disable 한 상태에서 Scraping 대상 웹사이트에 방문해 보면 어떤 방식으로 Web Scraping을 진행해야 할지 감이 오실 겁니다.
Selenium 아키텍처
Selenium 은 아래 그림과 같이 좌측부터 Selenium Client Library, JSON Wire Protocol, Browser Driver, Browser 총 4가지로 구성 됩니다. Selenium 을 사용하면 실제 브라우저를 애플리케이션 코드 레벨에서 자유롭게 핸들링 할 수 있게 되어 자동화된 테스팅 또는 Web Scraping 이 가능해 집니다.
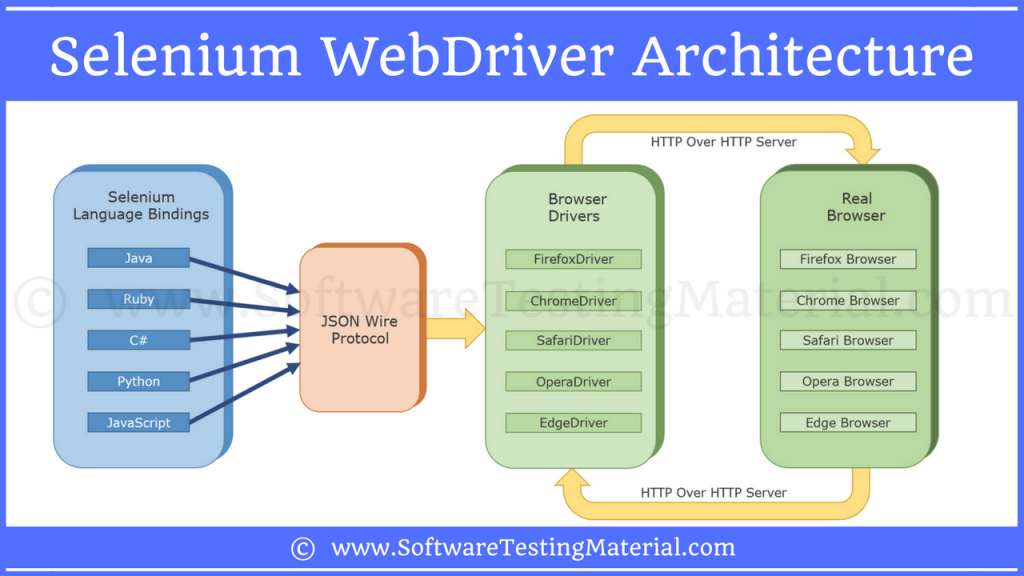 https://www.softwaretestingmaterial.com/selenium-webdriver-architecture/
https://www.softwaretestingmaterial.com/selenium-webdriver-architecture/
아래의 간단한 Java (Selenium Client Library) 코드가 실행되면 꽤 많은 일들이 일어나는데요.
1 2 3WebDriver driver = new FirefoxDriver(); driver.get("https://www.google.com"); System.out.println(driver.getPageSource());
- Selenium Client Library는 Browser Driver에게 실제 Browser(Firefox)의 구동을 명령 합니다.
- 이후 Selenium Client Library는 Local Server로 떠 있는 Browser Driver에게 보낼 명령을 다음처럼 JSON Wire Protocol 기반의 URL로 변환한 후 전송 합니다.
http://localhost:56081/{"url":"https://www.google.com"} - 명령을 수신한 Browser Driver는 Selenium Script를 이용하여 실제 Browser에게 최종 명령을 전달 합니다.
- 최종 명령을 전달 받은 Browser는 www.google.com 을 요청한 후 랜더링된 페이지 결과를 Browser Driver를 통해 다시 Selenium Client Library에 전달 합니다.
- 전달된 결과는 Selenium Client Library를 통해 코드 레벨에서 사용이 가능 합니다.
동작하는 방식이 마치 Marionette (마리오네트: 줄인형)와 유사 합니다.
- Selenium Client Library : 인형사가 잡는 '손잡이'
- JSON Wire Protocol : 인형사의 손에 의한 '움직임'
- Browser Driver : 손잡이와 인형을 연결하고 있는 '줄'
- Browser : 실제 '인형'
구현
환경구성
macOS 기준으로 설명 드리며, Selenium 과 호환이 잘되어 코드를 통해 브라우저의 기능 대부분을 핸들링 할 수 있는 Firefox 를 기준으로 하였습니다.
1. Project 생성 (IntelliJ > Gradle > Java)
Java Project 생성 후 build.gradle 에 아래 Selenium 과 Jsoup 2개의 의존성을 추가하고 build 합니다.
1 2compile group: 'org.seleniumhq.selenium', name: 'selenium-java', version: '3.13.0' compile group: 'org.jsoup', name: 'jsoup', version: '1.11.3'
2. Firefox 설치
https://www.mozilla.org/ko/firefox/new/ 에 방문하여 '다운로드' 후 설치 합니다.
3. gekodriver 설치
아래 사이트에서 자신의 OS 맞는 geckodriver를 다운로드 & 압축해제 한 후 1번에서 생성한 Project 폴더 안 적당한 곳에 위치 시킵니다. (ex. {project-root}/drivers/geckodriver)
https://github.com/mozilla/geckodriver/releases
추가로 Linux(Ubuntu) 기반의 Selenium Web Scraping 서버를 구성하실 경우 여기를 참조 하세요.
간단한 예제
Scraping 대상 웹사이트에 로그인 한 후 웹페이지를 Scraping 하는 샘플 소스코드 입니다. 보시듯이 코드가 굉장히 쉽고 직관적 입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24@Before public void before() { System.setProperty("webdriver.gecko.driver", "{project-root}/drivers/geckodriver"); } @Test public void selenium_example() { WebDriver driver = new FirefoxDriver(); // 브라우저 실행 driver.get("로그인 URL"); // 로그인 페이지로 이동 합니다. WebElement id = driver.findElement(By.id("id")); id.clear(); id.sendKeys("아이디"); // 아이디 입력 필드에 '아이디'를 입력 합니다. WebElement pw = driver.findElement(By.id("pw")); pw.clear(); pw.sendKeys("비밀번호"); // 비빌번호 입력 필드에 '비밀번호'를 입력 합니다. WebElement button = driver.findElement(By.cssSelector("#login > form > fieldset > button")); button.submit(); // Form 전송. // Form 전송 후 로그인 완료 페이지로 이동하여 페이지가 완전히 랜더링 될 때 까지 대기 헙니다. new WebDriverWait(driver, 10).until(ExpectedConditions.urlToBe("로그인 완료 URL")); new WebDriverWait(driver, 10).until((ExpectedCondition<Boolean>) d -> ((JavascriptExecutor) d).executeScript("return jQuery.active == 0").equals(Boolean.TRUE)); driver.get("Scraping 대상 URL"); // Scraping 할 페이지로 이동 합니다. System.out.println(driver.getPageSource()); // 페이지 소스를 Scraping 합니다. driver.quit(); // 브라우저 종료 }
성능 끌어올리기
Selenium을 이용해 실제 Web Scraping 을 진행해 보니 예상보다도 훨씬 속도가 안나왔습니다. 그래서, 어떻게든 최대한 성능을 끌어 올리고자 아래의 몇가지 방안을 고민하고 적용 했었는데요, (WebDriver 기동 시간을 제외하고) 적용 전 5~6초 걸리던 Scraping 시간이 적용 후 2초 이내로 약 60% 이상의 성능개선 효과를 얻을 수 있었습니다. (제가 진행한 Web Scraping 은 한번 시도에 로그인, 로그아웃을 포함하여 총 10개의 웹페이지에 대해 Scraping 을 시도하는 것 이었습니다.)
WebDriver 를 재사용하라
WebDriver 객체 생성(브라우저 기동) 시 굉장히 많은 컴퓨터 자원이 소모되기 때문에 최대한의 재사용을 통해 이를 방지해야 합니다. 저의 경우 Spring 에서 제공되는 org.springframework.aop.target.CommonsPool2TargetSource 를 사용하여 WebDriver 를 멤버변수로 지니고 있으면서 재사용 하는 Bean 을 Object Pooling 화 하는 방법을 사용 하였습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18@Test public void create_driver_bad_case() { for (int i = 0; i < 5; i++) { WebDriver driver = new FirefoxDriver(); driver.get("https://www.google.com"); System.out.println(driver.getTitle()); driver.quit(); } } @Test public void reuse_driver_good_case() { WebDriver driver = new FirefoxDriver(); for (int i = 0; i < 5; i++) { driver.get("https://www.google.com"); System.out.println(driver.getTitle()); } driver.quit(); }
UI 테스트가 아닌 이상 브라우저는 무조건 Headless(Background) 모드로 띄워라 (불필요한 Graphics 자원 사용 최소화)
1 2 3FirefoxOptions options = new FirefoxOptions(); options.setHeadless(true); WebDriver driver = new FirefoxDriver(options);
불필요한 데이터는 로딩하지 말아라 (Image, CSS, Flash)
1 2 3 4 5 6 7FirefoxProfile profile = new FirefoxProfile(); profile.setPreference("permissions.default.image", 2); profile.setPreference("permissions.default.stylesheet", 2); profile.setPreference("dom.ipc.plugins.enabled.libflashplayer.so", false); FirefoxOptions options = new FirefoxOptions(); options.setProfile(profile); WebDriver driver = new FirefoxDriver(options);
Web Element(웹 요소)를 얻어 올 때는 아래의 순서(속도 별)대로 얻어오라
- ID
- CSS and Name selectors
- XPath locators
다음 코드는 '구글' 의 검색어 입력 창 웹요소를 얻어오는 속도에 따른 여러 가지 방법 입니다.

1 2 3 4WebElement first = driver.findElement(By.id("q")); WebElement secondA = driver.findElement(By.cssSelector("#q")); WebElement secondB = driver.findElement(By.name("q")); WebElement third = driver.findElement(By.xpath("//*[@id="q"]"));
내부 API(End-points)를 찾아라
최근 대부분의 웹사이트는 비동기 방식으로 내부 API를 호출하여 웹페이지를 랜더링 합니다. 이런 경우 브라우저 자체에서 제공되는 개발자도구(네트워크 > XHR)를 이용하면 API의 URL과 응답 결과를 쉽게 확인할 수 있습니다. 확인된 API를 직접 호출하여 Scraping 할 경우 응답 결과(JSON, XML)를 정제 과정 없이 빠르게 Java Object 로 Mapping 하여 사용할 수 있습니다.
웹페이지 요청 회수를 최대한 줄여라
동일한 기능과 데이터를 제공하는 웹페이지가 중복으로 존재 할 경우 용량이 적은 웹페이지 위주로 요청 하시고, 필요한 정보가 최대한 많이 포함되어 있는 웹페이지를 찾아 요청 회수를 최대한 줄이세요.
병렬 처리!?
컴퓨터가 같은 작업을 동시에 여러 개 수행 하려면 어쩔 수 없이 멀티 쓰레드 또는 멀티 프로세스를 이용한 병렬처리 기법을 사용해야 합니다.
Web Scraping 의 경우도 마찬가지 인데요, 다만 반드시 주의 할 사항이 하나 있습니다. 병렬처리로 인한 과도한 Scraping 은 대상 사이트의 보안정책(방화벽 룰)에 의해 차단됨은 물론, 심각할 경우 추후 법적인 책임을 져야 할 수도 있습니다.
따라서, Web Scraping 시 항상 정상적인 허용 범위 내에서 요청해야 함을 절대 잊지 마시길 바랍니다!
주의사항
보안
SSL(HTTPS)을 사용하라
만약 SSL을 사용하지 않고 인증과정을 거친 중요한 개인정보 또는 그에 상응하는 정보를 Scraping 한다면 자신만 모른체 벌거벗은 채로 거리를 당당하게 행차한 임금님과 같다고 보시면 됩니다. 오고 가는 모든 정보는 100% 해커에게 노출될 것 입니다. 따라서, 인증을 거친 Scraping 또는 Proxy 를 경유하는 Scraping 의 경우 SSL 은 무조건 필수 입니다. 이론적으로 SSL 을 사용 한다면 패킷이 노출되어도 해석이 불가능 하기 때문 입니다. (참고로 Selenium 이 사용할 브라우저의 설정을 통해 SSL 통신이 아닌 경우 웹서핑을 불가능하게 하는 것도 좋은 방법 중 하나 입니다.)
브라우저 업데이트를 정기적으로 확인하고 적용하라
브라우저 취약점을 이용한 공격은 날마다 새롭게 생겨 납니다. 이를 막으려면 정기적으로 Web Scraping 에 사용되는 브라우저의 업데이트를 확인하고 적용해야 합니다.
기다려야 할 때
Scraping 도 중 Submit, Click, Redirect 등의 상황을 만나 웹페이지가 전환될 경우 (브라우저의 응답이 비동기로 드라이버에 전달되기 때문에) 최종 목적지 페이지의 랜더링이 완료 될 때까지 기다려야 합니다. 이유는 랜더링이 완료되지 않은 시점에서 웹요소를 얻어오려 시도할 경우 org.openqa.selenium.NoSuchElementException 이 발생하기 때문입니다.
아래의 코드로 랜더링이 완료 될 때 까지 대기할 수 있습니다.
1 2 3 4new WebDriverWait(driver, 10).until(ExpectedConditions.urlToBe("최종 목적지 URL")); // [주의] 아래 코드는 jQuery 를 사용하지 않는 웹사이트의 경우 에러가 발생합니다. 그런 경우 해당 웹사이트의 상황의 맞게 JavaScript 구문을 변경하여 사용 하세요. new WebDriverWait(driver, 10).until((ExpectedCondition<Boolean>) d -> ((JavascriptExecutor) d).executeScript("return jQuery.active == 0").equals(Boolean.TRUE));
좀 더 잘하려면
최대한 자연스럽게 하라 (입력 키 값 속도 제어 등)
실제 사용자로써 웹사이트를 충분히 이용하고 파악하신 후, 코드를 사용하여 실제와 같이 최대한 자연스럽게 구현하고 테스트해 보세요.
과도한 양을 요청하지 마라
앞서 말씀 드렸듯이 방화벽 정책으로 인해 자동으로 차단 되거나, 법적인 책임을 져야 할 수도 있습니다.
파라미터를 변조하지 마라
대상 웹사이트의 로그에서 기존과 다른 파라미터 패턴(순서변경, 삭제 또는 추가)이 발견 될 경우 차단 될 가능성이 커집니다.
Proxy 사용
Scraping 대상 웹사이트가 보안을 조금이라도 신경쓰고 있다면 AWS(Amazon Web Services), Tor(익명 네트워크) 등의 IP 대역은 (웹상에 공개되어 있기에) 이미 접속이 차단되어 있을 겁니다. 이런 경우 규모가 있는 회사라면 직접 Proxy 서버를 구성하여 경유하거나 그게 어렵다면 클라우드 기반의 Proxy 서비스(유료)를 이용해 보는 것도 방법일 수 있습니다.
아래는 FireFox 기반에서 Proxy 를 설정하는 코드 입니다.
1 2 3 4FirefoxProfile profile = new FirefoxProfile(); profile.setPreference("network.proxy.type", 1); profile.setPreference("network.proxy.socks", proxyUrl); profile.setPreference("network.proxy.socks_port", proxyPort);
Fault Tolerance (결함 내성) 적용
Web Scraping 의 경우 대상 웹사이트의 예기치 못한 변경, 장애, 차단 등 여러 가지 이슈로 인해 Scraping 이 불가능한 상황이 발생 할 수 있습니다. 따라서, 이와 같은 상황이 발생하더라도 그 영향을 최소화 할 수 있도록 Fault Tolerance 를 시스템에 적용해야 합니다.
Fault Tolerance?
전체 시스템 중 일부에 결함(고장)이 발생하더라도 정상 또는 부분적 기능 수행이 가능하게 하는 것. Timeout, Retry, Fallback, CircuitBreaker, Bulkhead 등의 패턴이 있음.
Fault Tolerance 개념에 대해 좀 더 알고 싶으시다면 기존에 제가 정리한 MicroProfile 슬라이드의 P.38 을 참고해 주세요.
[부록] Hybrid Scraping
보통 보안 수준이 어느정도 갖춰져 있는 웹사이트들의 경우 무분별한 Web Scraping 을 막기위해 최소한 로그인(인증) 페이지 만은 대부분 동적으로 구성됩니다. 이런 경우 인증이 필요한 부분만 Selenium 을 이용하여 처리하고 응답으로 받은 Cookies 를 Jsoup 등과 같은 정적 Scraping 도구에 세팅하여 나머지 Web Scraping 을 빠르게 수행할 수 있습니다.
아래는 Selenium 과 Jsoup 을 이용한 Hybrid Scraping 예제 입니다. (v.2018년11월)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35@Test public void hybrid_scraping_by_selenium_and_jsoup_using_cookies() throws Exception { // Selenium(Dynamic Scraping) WebDriver driver = new FirefoxDriver(); driver.get("로그인 URL"); WebElement id = driver.findElement(By.id("id")); id.clear(); id.sendKeys("아이디"); WebElement pw = driver.findElement(By.id("pw")); pw.clear(); pw.sendKeys("비밀번호"); WebElement button = driver.findElement(By.cssSelector("#login > form > fieldset > button")); button.submit(); new WebDriverWait(driver, 10).until(ExpectedConditions.urlToBe("로그인 완료 URL")); new WebDriverWait(driver, 10).until((ExpectedCondition<Boolean>) d -> ((JavascriptExecutor) d).executeScript("return jQuery.active == 0").equals(Boolean.TRUE)); // 로그인 Cookies 를 얻어 옴 Set<Cookie> cookies = driver.manage().getCookies(); Map<String, String> cookieMap = cookies.stream().collect(Collectors.toMap(Cookie::getName, Cookie::getValue)); for (Map.Entry<String, String> entry : cookieMap.entrySet()) { System.out.println("key: " + entry.getKey() + ", value : " + entry.getValue()); } // Jsoup(Static Scraping) Document document = Jsoup.connect("Scraping 대상 URL") .userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:62.0) Gecko/20100101 Firefox/62.0") .header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8") .header("Accept-Encoding", "gzip, deflate, br") .header("Accept-Language", "ko-KR,ko;q=0.8,en-US;q=0.5,en;q=0.3") .header("Host", "Scraping Host URL") .cookies(cookieMap) // 로그인 Cookies 세팅 .ignoreContentType(true) .get(); System.out.println(document.html()); driver.quit(); }
마무리
창과 방패의 끝없는 싸움
처음 해보는 Web Scraping 이었는데, 짧은 시간 동안 정말 재미있게 개발 하였습니다. 아마도 Web Scraping 이 마치 ‘창과 방패’, ‘뚫으려는 자와 막으려는 자’ 의 싸움과 같아서 더욱 흥미로웠던 것 같습니다. 참고로 국내 최대 포털 사이트 같은 경우 Web Scraping 에 대한 대비가 정말 잘 되어 있더라고요. 아마도 내부에서 담당자 분들이 이런 저런 방식으로 Web Scraping 을 직접 시도해 보고 발견된 특이사항과 패턴들에 대해 지속적으로 대응책을 마련하고 있는 것 같습니다.
제 개인적으로도 Web Scraping 을 더 잘 수행하거나 더 잘 차단하려면 서로 상대방의 입장에서 먼저 고민해 보고 해답을 찾는 것이 가장 빠른 지름길 이라고 생각합니다. 그리고, 그런 과정의 반복을 통해 시스템은 계속해서 발전해 나가리라 생각하고요.
왜 공유 했는가?
제가 이 글을 쓴 이유는 제목과 같이 테스트 자동화 도구로 잘 알려진 Selenium 이 상황에 따라 동적인 웹페이지를 Scraping 하는 데에 아주 유용하게 쓰일 수 있다는 것과 제가 그것을 구체적으로 어떻게 적용 했으며 그 과정에서 무엇을 경험 했는지를 관심 있으신 분들과 함께 나누기 위해서 입니다.
또한, 본 글은 제가 처했던 상황과 환경에서 찾은 방법과 경험에 대한 공유인 것이지 반드시 정답은 아닙니다. 그래서 제가 시도한 그대로 하지 마시고 더 나은 방법은 없는지 꼭 한번 고민해 보시길 바랍니다.
머지않은 미래
Web Scraping 개발을 진행 하면서 이런 엉뚱한 생각을 한번 해보았습니다. (최근 무섭게 발달한 음성인식 기술과 Deep Learning 기술에 편승하여)
| 나: 안녕? AI. 내가 지난 주에 OO몰에서 주문한 OO좀 재주문 해줘~
AI: 안녕하세요? 마이엉주(Myungju)님. 무료배송쿠폰이 있는데 주문할 때 사용할까요? (상품과 가격 정보를 보여주며) 나: 응 AI: 무료배송쿠폰 사용해서 총 ₩10,000 에 재주문 완료하였습니다. YYYY-MM-DD 에 배송 될 예정 입니다. (주문 내역을 보여주며) AI: 혹시 더 필요하신 것은 없으세요? |