스파게티 조인을 피하고 경계안에서 캐시 구현하기

아침에 출근했더니 동료가 나에게 링크를 하나 던지며 이렇게 말했다.
위 블로그가 어제 말한 오퍼레이션 캐쉬 설명하는것 같은데 한번 검토해주실수있을까요?
Why duplication isn’t always a bad thing in micro-services
CTO님이 데이터 중복이 필요할 때가 있다고 설파하던 기억이 난다. 그 당시 대부분의 개발자들이 못알아듣는 눈치였는데, 역시 사람들이 배워서 써먹는 데에는 자기만의 시간이 있다. 귀로 듣거나 책으로만 읽어서는 알 수 없고, 자기 삶에서 그 장면을 만나야 한다. 반갑게도 동료에게 때가 온 모양이다. 어제 퇴근을 같이 하면서 나눈 수다가 그에게 여운이 되어서 (그 사이 무슨 일이 있었는지 모르지만) 나에게 영어로 쓰여진 모르는 이의 블로그 글을 날리게 했다. 거기에는 자연스럽게 나를 미소짓게 하는 익숙한 구조의 그림이 있었다.
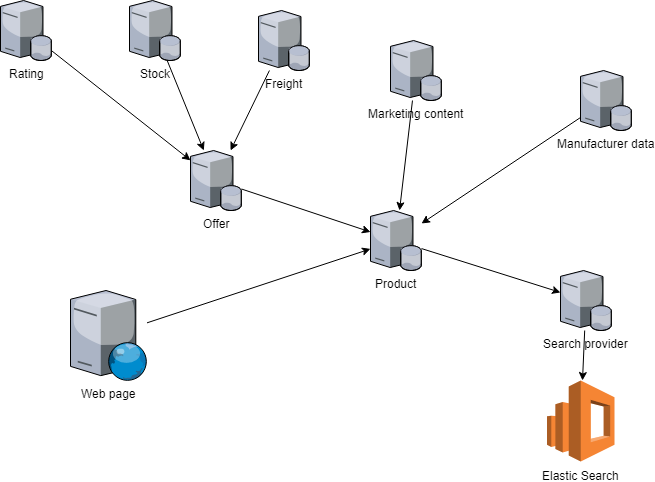
이미지 출처: michalbialecki.com
생각해보니 또 다른 동료가 예전에 우리 상황을 그린 그림도 있다. 둘은 조금 다르지만 어제 우리가 나눈 대화의 주제를 기준으로 보면 큰 차이가 없다.
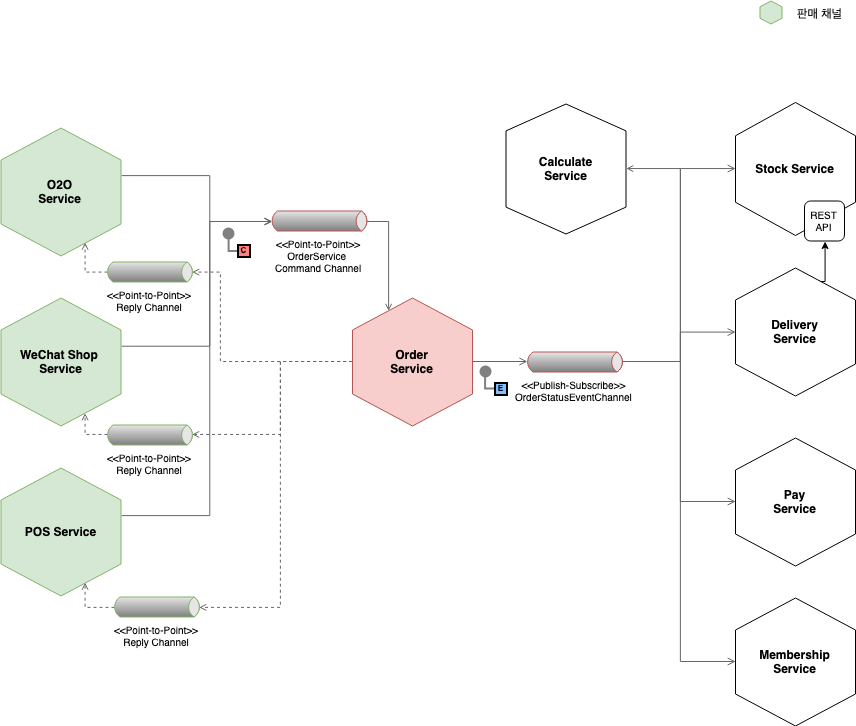
주문 기능을 둘러싼 마이크로 서비스 구조
영문 읽기가 가능하신 분들은 링크를 읽어 보시고 이제 우리의 이야기를 대략 풀어보겠다.
오퍼레이셔널 캐시란 무엇인가?
입에 밴 말인데 출처는 기억이 안난다. 위키피디아에 정의가 있으면 좋으련만 없었다. 구글 검색해보니 IBM 기술이 첫 페이지를 선점했다. 내가 IBM 기술을 통해 배웠을리는 없다. 그들이 개념 정의를 잘 하고, 글을 많이 써서 검색 엔진 노출을 잘할 뿐이다. 하지만 그들의 기술을 이용해서도 내가 말하려던 개념을 설명할 수 있다.
MDD 혹은 기준 정보(또는 원장)란 말을 쓰는 사람들이 있다. 대개 이러한 시스템 환경1)에서는 원천 데이터를 정의하는 데이터베이스가 따로 있고, 그걸 복사해서 쓰는 데이터베이스가 존재한다. 이때 원천 데이터가 아닌 곳의 데이터는 그 쓰임에 있어 캐시 성격을 띈다. 응답성과 처리량을 높이기 위해 쓰는 시스템 운영상의 캐시인 것이다. 이를 오퍼레이셔널 캐시Operational Cache라 부를 수 있다.
캐시란 무엇인가?
다행히 이번에는 위키피디아에 정의가 있다. 같은 요청이 여러번 올 경우 데이터를 다른 곳에 복제해서 빠른 응답을 보장해주는 구성요소다.
In computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere.
컴퓨터 구조를 아는 분들은 우리가 매일 쓰는 컴퓨터 내부에 캐시가 있는 것을 알 것이다. 한편, 성능 향상을 위해 많은 응용 프로그램에도 캐시가 쓰인다. 기술 위주로 학습을 하는 사람은 Redis나 Memcached를 써야 캐시를 쓴다고 이해하기 쉽지만, 캐시는 다른 방법으로도 구현할 수 있다. 마이크로 서비스 환경에서 캐시를 응용할 기회는 매우 많다.
서두에 언급한 CTO가 복제라고 말한 부분을 캐시 구현이라고 할 수도 있다. 왜 그러한지 설명을 하겠다.
동료의 사례에 대입해보기
동료가 '검토해달라'고 한 말이 구체적으로 뭘 요구한 것인지 모르겠지만, 일단 기사를 읽으면서 위에 쓴 내용처럼 과거의 기억을 소환했다. 그리고 궁금증에 Operational cache, cache 등을 키워드로 검색을 해봤다. 결국 그런 행동들이 동료가 말한 검토가 되었고, 그 끝에 나는 생산적인 답을 하고 싶었다. 그래서 그에게 내가 기억하는 사례가 그가 겪은 것이 맞는지부터 확인했다.
대략의 코드가 아래와 같다고 설명해주었다. Go 코드인데 대충 내 수준에서 해석해보면 분배distributes 항목에 들어 있는 숫자만큼 반복하면서 매장 번호(StroeId) 기준으로 매장 정보를 담는 store 구조체를 가져오고, 사용자 번호(ColleagueId)를 기준으로 사원 정보를 담는 emp 구조체를 가져온 후에 다시 분배 대상 상품(SKU) 중에서 운송장 번호와 불일치가 있는 것을 추려내는 일로 해석2)된다. 분배라는 말은 직영 매장에 상품을 보내는 책임자가 개별 매장에 도착해야 할 상품의 숫자를 입력하여 물류 명령을 내리는 일을 말하는 도메인 용어다.
1 2 3 4 5 6 7for _, distributre := distributes { store := CmmStore{}.FindById(distribute.StoreId) emp := CmmEmp().FindById(distribute.ColleagueId) for _, item := distribute.items { stockMiss := StockMis().FindByWaybillNoAndSkuId(distribute.waybillNo, item.SkuId) } }
여기서 동료의 고민은 실행 속도가 너무 느려 위 프로그램이 튜닝 대상으로 지목된 것에서 비롯되었다. 서로 다른 마이크로 서비스 3개가 엮이는 업무인데 '경계를 넘는 JOIN을 허용해야 하나?' 하는 생각이 잠깐 스쳤다고 한다. 다행히 그는 어제 다른 동료가 짜는 프로그램(마이크로 서비스 형태)의 테이블을 뒤지지 않도록 경계를 지켜냈고, 코드를 아래와 같은 식으로 수정하여 스파게티 JOIN3)을 만들지 않았다는 무용담을 했던 것이다.

동료의 무용담의 주제가 된 코드
위에서 DB에 존재하면 반환이라고 표기된 영역이 바로 (오퍼레이셔널) 캐시 응용에 해당한다. 위키피디아에 나오는 캐시 정책 이미지를 보면 cache hit? 라는 판단과 1:1 대응이다. 물론, 앞부분만 비슷한 것이라서 순서도의 아래 부분은 무시하자. 그저 전혀 다른 맥락에서 쓰이는 캐시와 응용 프로그램에서 우리가 로직으로 구현하는 캐시의 유사성을 언급하려고 인용했을 뿐이다.
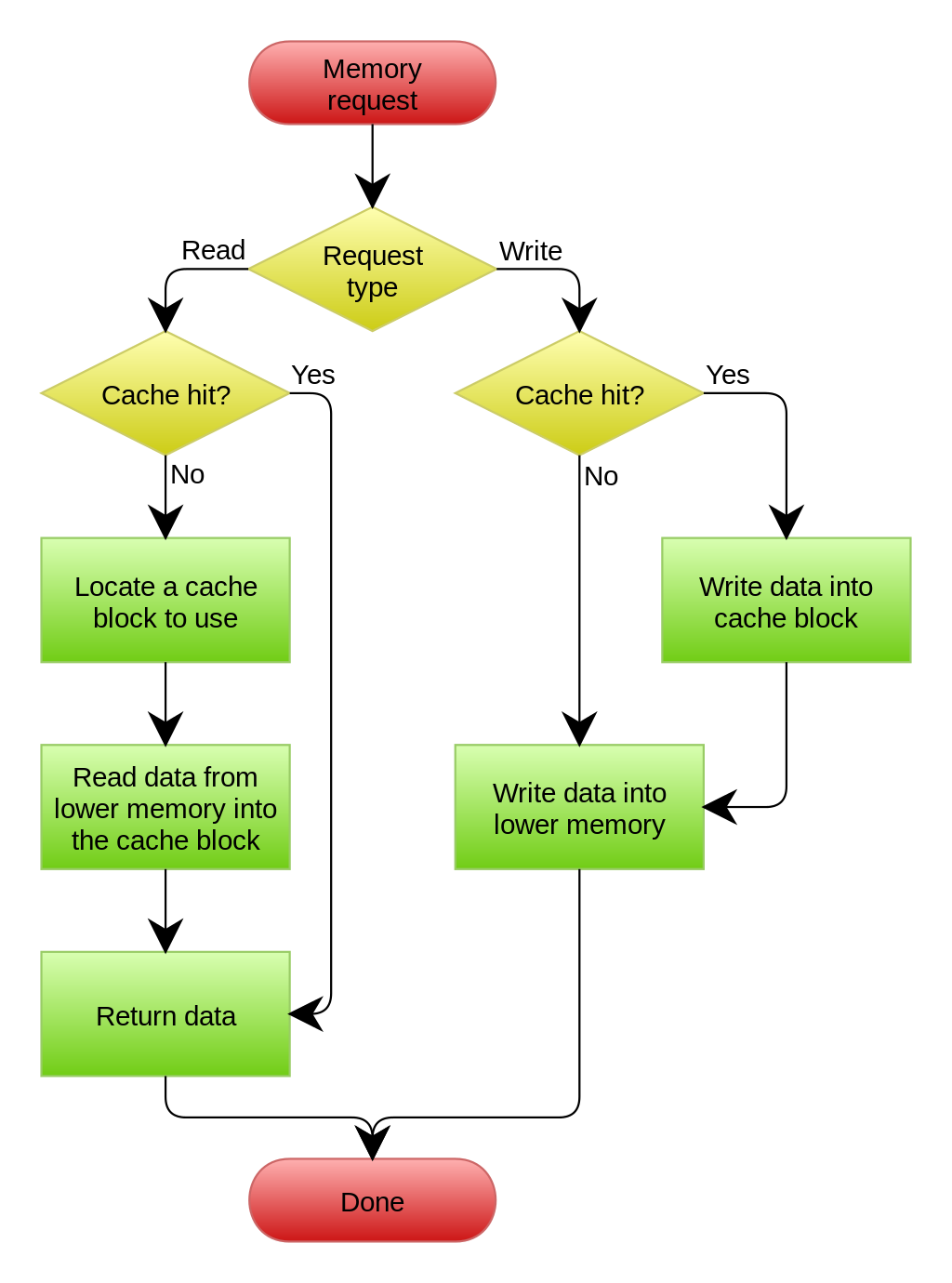
캐시 정책 사례 (출처: 위키피디아)
BoundedContext 구현
갈등속에서 동료가 지켜낸 경계를 Eric Evans의 정제된 표현을 빌리면 BoundedContext라고 할 수 있다. 경계를 지어 맥락을 보호하기 위한 프로그래밍 기법이며 구조체라고 할 수 있다. 이 지점에서 말장난으로 느껴질 분들에게 차이점을 설명해보자. 만일 여기서 동료가 급한 마음에 '에라모르겠다'는 심정으로 스파게티 JOIN을 썼다면 어떤 차이가 발생하는가?
경계를 두어 스스로 저장(캐시값)하는 대신에 관계형 테이블의 레코드 참조를 할 테니 다른 마이크로 서비스에서 바뀐 모든 상태값이 내가 짠 코드 경계안에 그대로 침투된다. 모노리식Monolithic 혹은 통DB구조에 익숙한 개발자들은 이걸 심각한 문제로 느끼지 않을 수 있다. 하지만, 이렇게 되면 내가 짠 코드의 결과값이 이후에 시스템 운영상황에 따라서 내 예상과 달라지는 일이 비일비재하게 겪는다. 내가 만들지 않은 프로그램에 의해서 만들어진 데이터의 일부를 기습적으로4) 참조해오기 때문이다. 대개 이런 처리가 시스템 도처에 퍼져 있으면, 평온한 심리상태를 유지하며 서비스 코드를 만들어가는 일상을 해내기가 쉽지 않다. 우리가 마이크로 서비스를 만드는 이유는 바로 이러한 직업 일상의 자가 통제와 이를 기반으로 하는 빠른 비즈니스 전개에 있다.
한 가지 주의사항
이렇게 중복값을 쓰면 데이터 변경 지점을 하나로 통제해야 한다. 크게 두 가지 방법이 있다. 하나는 피하라고 권하고 싶은 전통적인 방법이다. 관문성격이 되는 프로그램 흐름상 앞부분에 존재하는 어떤 코드에 데이터 변경에 따르는 다양한 규칙을 전담하는 방법이다. DDD 나 JPA 개념으로 등장하는 조립물이나 애그리게잇도 이러한 사례 중에 하나다. 하지만, 부정적인 단서를 단 이유는 종종 화면 이벤트를 받는 코드 중 일부가 점차 읽을 수 없는 방대한 코드5)로 변하는 사례를 매우 많이 보았기 때문이다. 그렇게 되면 이 부분을 담당한 개발자가 예민해지고 수정을 거부하는 꼰대 개발자로 변해가곤 한다.
또 다른 방법은 도메인 이벤트를 구현해서 처리하는 방법이다. 추천하고 싶지만, 개발팀 동료들 사이에서 협업이 꽤 잘되는 개발문화가 전제되어 있어야 한다. 앞서 인용한 영문 블로그에도 나오는 방식이다. 앞에서 소개한 필자의 다른 동료가 그린 그림에도 표현되어 있다. 복잡한 분기 자체는 이벤트 처리 인프라에 맡기고 일종의 발행/구독 방식으로 마이크로 서비스 사이의 교신과 데이터 변경을 해나가는 식이다. 의미상으로 저도 필요한 도메인 이벤트를 주고 받는 식으로 프로그램을 구성한다. 한번 익숙해지면 매우 편리한데, 경험상 조직력을 맞추는 학습비용이 발생한다.
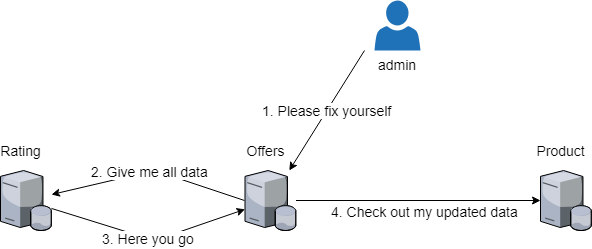
동료의 검토 요청에 응하는 정도로 쓰는 것이라, 다른 분들에게는 친절하지 않은 글이지만 이 정도로 마치겠다.
주석
[1] 매우 낙후된 환경이다. 비즈니스 이력이 사라지고 결과 데이터만 남는 구조탓에 원천 데이터의 특정 시점의 상태snapshot를 보존하려고 프로그램 수정을 막는 일이 비일비재하고, 결과는 항상 차세대 프로젝트라고 미화된 전면 재개발로 흘러간다.
[2] 내가 짠 것이 아니라 틀릴 수가 있지만, 본문을 설명하는데 문제가 없기 때문에 확인하지 않고 짐작하여 쓴다.
[3] 스파게티 코드에 빗대어 스파케티 JOIN이라는 신조어를 만들어 봄!
[4] 기습적으로 수식어가 매우 중요하다. 왜냐하면 그 수식을 빼면 남이 짠 프로그램이 변경한 데이터를 참조하는 일은 정상적인 보편현상이기 때문이다. 어떤 사건의 발생에 따른 파급효과를 시스템 전체에 퍼뜨리는 방식이 보장되지 않는 상황에서 일부 데이터를 가져가서 보는 형태를 비유적으로 설명했다.
[5] 필자는 모회사에서 주문 처리를 하는 3만 라인에 해당하는 코드를 보며 고치고 싶은 충동을 느낀 일이 있다.