적당히 갖춰나간 운영 환경

2016년, 중국 패션 리테일 영역의 클라우드 서비스 회사가 되겠다는 야심 찬 희망을 품고 아기 발걸음[1]을 시작했고, 2020년 현재 아래와 같은 구성을 갖추었다. 처음부터 이런 구성을 그려놓고 차근차근 갖춰 나간 것은 아니었다. 2016년 봄, 알리 클라우드에 3대의 리눅스 서버를 구매해서 1대에 대충 스테이징 환경과 각종 관리 툴을 세팅하고 2대 서버에 운영을 위한 최소한의 구성만 갖춘 채 첫 번째 기능을 출시했다. 매번 필요할 때마다 점진적으로 아키텍처를 개선해 나갔고, 4년이 지난 지금 꽤 그럴싸한(?) 모양을 갖추게 되었다. 지금 우리가 갖추고 있는 기술 셋을 소개해본다.
Infra 구성
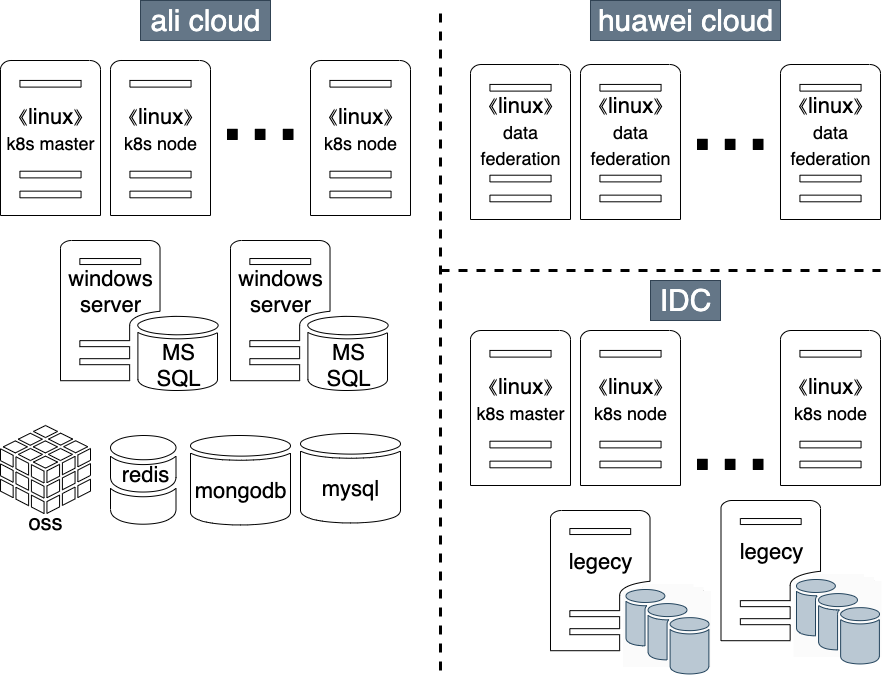
2개의 클라우드 회사를 사용하고 있다. 사용자들이 직접 사용하는 기능은 모두 알리(Ali) 클라우드에서 운영되고 있고, 화웨이 클라우드에는 data federation을 위한 하둡 클러스터와 각종 도구를 구성해 놓았다. 레거시와 인터페이스를 하기 위해 IDC 내에도 쿠버네티스kubernetes, k8s 환경을 구성해 놓았다.
2개 클라우드에 나눠서 세팅한 것에는 특별한 이유는 없다. 2016년 알리 클라우드에서 먼저 서비스를 시작하였는데, 그해 여름, 이제 막 클라우드 사업을 시작한 화웨이(Huawei)가 공짜로 서버를 줄 테니 한번 써보고 피드백을 달라고 했다. 이제 막 시작하는 클라우드 환경에 중요한 서비스를 올리긴 어려웠고, 장애가 생겨도 괜찮은(?) 그런 게 어딨어 ㅡ,.ㅡ;; 기능을 화웨이 클라우드에 구성해보았다. 무료 사용 기간이 끝나고, 또 한 번 싸게 사용할 기회가 생겨 지금까지도 data federation을 위한 서비스는 화웨이 클라우드에서 돌아가고 있다. 여러 개의 클라우드 업체를 사용한다고 해서 딱히 좋은 건 없더라. 오히려 번거로운 게 더 많다.
대부분의 기능은 리눅스 서버에서 동작한다. 하지만 몇몇 마이크로 서비스는 윈도우 서버와 MSSQL 서버에 의존하고 있어서 Windows Server도 사용하고 있다. mysql, mongodb, redis등의 데이터베이스는 직접 운영을 하지 않고 ali cloud에서 FaaS 형태로 제공하는 RDS를 사용하고 있다. 파일 저장 공간으로는 ali cloud에서 제공하는 OSS를 사용한다.
쿠버네티스kubernetes 구성
처음부터 쿠버네티스를 사용했던 것은 아니다. 2016년 당시 도커 스웜(swarm), Marathon, Rancher 등 다양한 도커 오케스트레이션 도구가 있었다. 여러 가지 도구들이 각자의 장점을 얘기하며 춘추전국시대를 만들고 있었지만, 기능은 대동소이했다. 이 중 하나를 선택하는 것도 피곤했고, 잘 모를 때는 맨땅에 직접 해 봐야 한다는 생각으로 한 땀 한 땀 운영 환경을 만들었다. 개발자들이 두려움 없이 배포할 수 있도록 consul, nginx, jenkins를 사용하여 Blue-Green Deploy 방식으로 배포하고 구동할 수 있는 환경을 직접 구성했다. 하지만 서비스 규모가 점점 커지면서 오케스트레이션을 위한 도구가 필요했고, 2017년 쿠버네티스를 도입했다. 하지만 여전히 운영되고 있는 서비스가 있어서 한 번에 쿠버네티스로 전환하기는 어려웠다. 시간을 두고 차근차근 쿠버네티스 환경으로 옮겨왔고, 현재는 모든 서비스가 쿠버네티스 클러스터에서 동작하고 있다. 아래는 쿠버네티스 클러스터 현황이다.
- production
- 274 services
- 647 pods
- staging/qa
- 570 services
- 667 pods
여기서 쿠버네티스 자체에 대해 설명은 하지 않고, 우리가 실제 적용하고 있는 몇 가지 사항만 소개하겠다.
Ingress: kong
외부에서 쿠버네티스 클러스터의 내부로 접근하기 위한 ingress로는 kong을 사용한다. nginx를 바로 사용해도 되지만 url mapping, JWT 인증 등 gateway로 사용하기 위한 다양한 plugin이 제공되기 때문에 kong을 선택했다. (사실 kong은 nginx 기반에 약간의 편리한 기능을 추가한 제품이다) kong 공식문서에 사용할 수 있는 플러그인들이 소개되어 있다.
리소스 할당
각 pod에는 사용할 리소스의 양을 명시할 수 있는데, 이때 request와 limit라는 개념을 사용한다. request는 pod가 생성될 때 할당되는 양이고, limit는 실행되다가 리소스가 더 필요한 경우 추가로 사용할 수 있는 양이다. request를 pod에 할당하는 최소 리소스, limit는 최대 리소스라고 생각하면 된다. 대부분의 pod의 리소스는 다음과 같이 셋팅했다.
1 2 3 4 5 6 7 8 9 10{ "limits": { "cpu": "500m", "memory": "512Mi" }, "requests": { "cpu": "50m", "memory": "64Mi" } }
우리는 대부분의 backend api는 Go로 작성한다. Go는 여러 장점이 있지만, 그중 하나가 서버 자원을 아주 적게 사용한다는 것이다. limit를 위와 같이 세팅해 놓았지만, 특별한 행사(중국에서는 한국인에게 잘 알려진 11.11 외에도 6.18, 3.8. 5.20등 다양한 온라인 커머스 행사들이 있다)로 사용자 요청이 집중되지 않는 한, 평소에는 cpu 0.05, memory 10MB를 넘는 일은 거의 없다.
배포
우리는 배포 작업 도구로 jenkins를 사용한다. 아래는 배포 작업 시 jenkins에서 실행되는 작업이다.
- gitlab에서 배포할 버전의 소스를 내려받는다
- 새로운 도커 이미지를 만들어 docker private registry에 push 한다.
- kubectl 명령으로 api 서버로 배포 명령을 전달한다.

쿠버네티스에서 새로운 어플리케이션을 배포한다는 것은, 결국 특정 노드에 동작 중인 pod를 제거하고 새로운 도커 이미지가 적용된 pod를 생성하는 것이다. 물론 pod만 내렸다 올리면 되는 게 아니라 일정 개수의 ReplicaSet이 유지되어야 하고, pod를 외부와 연결해주는 service/ingress와의 연결도 끊김 없이 유지되어야 한다. 그래서 deployment를 통해 인스턴스가 원하는 상태로 유지되도록 한다. 쿠버네티스 클러스터 내에서 각 인스턴스가 안정적으로 유지되려면 이러한 세팅들이 jenkins 작업으로 정확하게 등록되어야 하는데, 이러한 개념을 일반 개발자들이 정확히 이해하고 jenkins 작업을 스스로 만들기란 대단히 어렵다. 그래서 어플리케이션 타입별로 템플릿을 만들고, 해당 템플릿대로 jenkins 작업을 만들 수 있도록 하였다.

처음부터 이런 도구를 제공한 것은 아니었다. 새로운 마이크로 서비스를 배포할 때마다 인프라 담당자에게 생성해달라고 하거나 확인을 요청해 왔었는데, 그 담당자는 귀찮았는지 이런 웹페이지를 만들어 직접 등록을 하게 하더라. (우린 전체 인프라 및 어플리케이션 환경 관리를 2명이 다 하고 있음)
이러한 환경에서 개발자들은 두려움 없이 새로운 마이크로 서비스를 만들고 배포를 한다.
우리 회사의 쿠버네티스 도입기는 Open Infrastructure & Cloud Native Days Korea 2019 행사에 소개된 적이 있다. 발표 슬라이드 및 후기에서 현장감이 살아있는 더 상세한 이야기를 볼 수 있다.
관문
중국의 많은 서비스는 위챗에서 시작한다. 그래서 중국에선 위챗을 빼고 서비스를 하기는 불가능하다 어렵다. 위챗이 제공해주는 편리한 기능이 많을 뿐만 아니라, 위챗은 이미 사용자들의 실제 생활 속으로 아주 깊숙 들어가 있어서 새로운 기능을 제공할 때 위챗을 사용하면 확산하기도 쉽다. 위챗은 연동된 서비스들을 실행할 때 사용자들의 인증을 보장해주기 위해 OAuth 기능을 제공하고 있다. 이를 이용하면 로그인을 쉽게 구현할 수 있다. 위챗 OAuth 연동 방법에 대한 상세한 내용은 WeChat에 나만의 서비스 만들기 첫걸음 글에 자세히 소개되어 있다.
위챗 로그인
우리는 3가지 방식으로 서비스를 제공한다.
- 위챗 공식계정(微信公众号)
대상: 물건 구매 고객
물건을 구매하는 고객은 위챗 공식계정(微信公众号) 내에서 자신의 포인트, 쿠폰, 구매 이력 등을 확인할 수 있다.
- 위챗 기업계정(微信企业号)
대상: 기업 내 사용자
위챗 기업계정(微信企业号) 내에 별도의 App을 추가할 수 있는데, 매장 등 현장에서 일하는 사람을 위한 기능은 위챗 기업계정(微信企业号)을 통해 제공한다.
- 포탈
대상: 사무실에서 PC를 켜고 업무를 보는 사람을 위한 기능
아이디/패스워드 같은 건 필요 없고, 첫 화면에 뜨는 QR 코드를 위챗으로 스캔을 하면 로그인이 된다.
모두 다 위챗이 시작점이다.
Wechat OAuth 인증 과정을 거친 후 login service에서 JWT 토큰을 발급하면 로그인이 완료된다.
JWT의 장점은 인증에 필요한 모든 정보는 토큰 자체에 포함되어 있기 때문에 별도의 인증 서버를 둘 필요가 없다는 점이다. 대부분의 언어에서 JWT를 처리하는 라이브러리를 제공하고 있어서 쉽게 사용할 수 있다. 하지만 한번 발급된 토큰은 유효기간이 만료되기 전까지는 파기할 수 없다는 단점도 있지만, 이 단점은 무시하기로 했다. ㅋㅋ
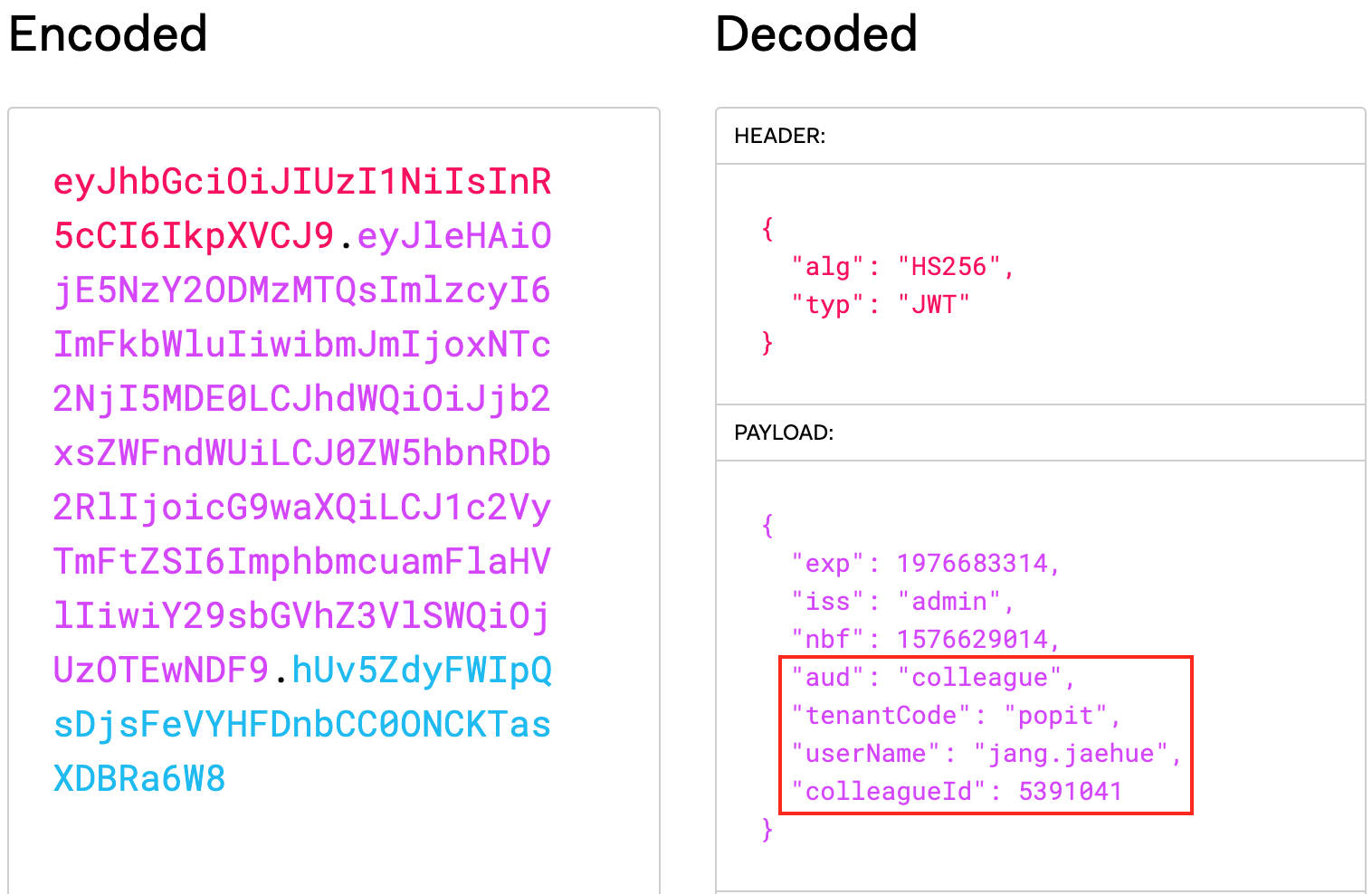
JWT 토큰은 세 파트로 나누어져 있고, 각 파트는 점으로 구분되어 있다. 즉, aaaa.bbbb.cccc와 같은 형태인데, 순서대로 헤더(Header), 페이로드(Payload), 서명(Sinature)이다. 서명(Sinature) 파트는 토큰이 변조되지 않았음을 증명하는 데 사용되는데 이때 SECRET KEY가 필요하다. 우리는 페이로드(Payload) 파트에 미리 정의된 클레임 외에 사용자의 신원을 확인할 수 있는 ID를 추가했다
인증
위챗 로그인을 통해 JWT 토큰을 획득하고 나면, 이후 모든 요청은 헤더에 JWT 토큰을 달고 다녀야 한다.
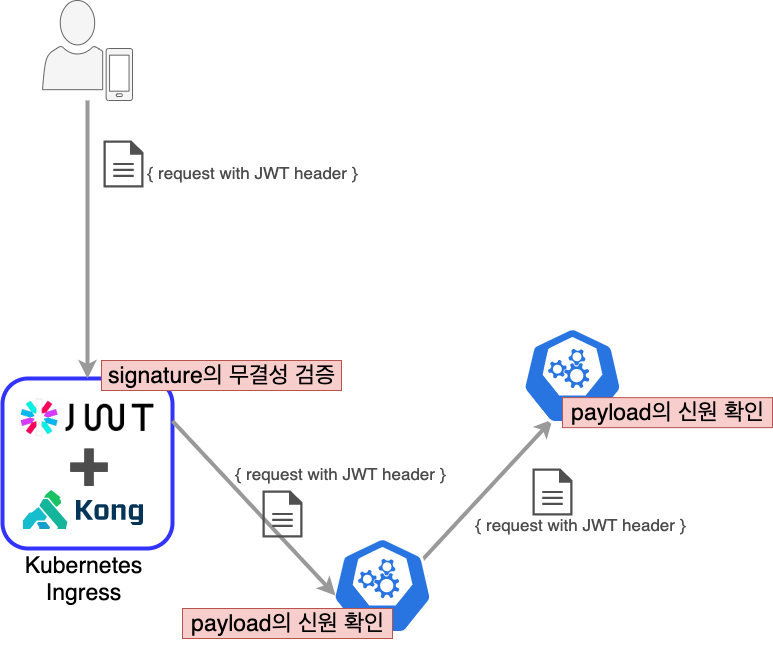
JWT 토큰으로 아래 2가지를 체크할 수 있다.
- 이 토큰이 유효한가?
signature의 무결성 검증SECRET KEY로 복호화한 서명(Sinature)의 무결성 확인 + 페이로드(Payload)에 있는 만료 시간 체크
- 이 토큰은 누구에게 발급한 것인가?
payload의 신원 확인페이로드(Payload)에 담겨 있는 사용자 ID
쿠버네티스의 Ingress로 사용하는 Kong에 JWT plugin을 추가하여 signature의 무결성을 검증한다. 각 마이크로 서비스에서는 payload의 신원을 확인한다. JWT 토큰을 발급하는 login service와 Kong의 JWT plugin은 같은 SECRET KEY를 사용해야 한다. 각 마이크로 서비스에서는 payload의 신원만 확인하기 때문에 SECRET KEY가 필요 없다. login service와 Kong의 JWT plugin에서 사용하는 SECRET KEY는 주기적으로 변경해주고 있다.
서비스 연계
마이크로 서비스 간 통신 방식으로 아래 2가지를 사용한다.
- web api
다른 마이크로 서비스를 호출해야 할 때 web api를 사용한다. grpc의 장점에 대해 많은 얘기가 나오고 있지만, 우리는 grpc를 사용했을 때 얻는 장점이 크지 않다고 판단하여(엄청 번거로움) 그냥 web api 방식으로 json 데이터를 주고받는다.
web api를 작성하는 방법에 대해서는 Go My Way #1 - 웹 프레임워크, Go My Way #2 - 데이터베이스, 로깅 글에 자세히 소개되어 있다.
- kafka message
요청 처리 과정 중에 비즈니스적으로 주요 행위가 일어나면 kafa로 이벤트를 전송하고, consumer service가 그 이벤트를 받아서 여러 액션을 처리한다.
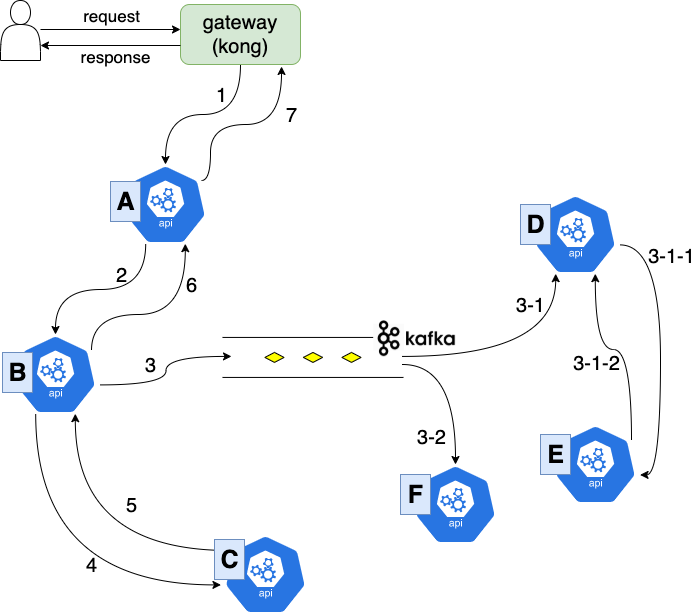
하나의 요청이 하나의 마이크로 서비스에서 처리가 끝나는 경우는 드물고, 대부분 여러 서비스를 거치면서 처리된다. 마이크로 서비스 환경으로 1년 정도 운영을 해보니 기존의 모노리틱(monolitic) 방식과는 또 다른 어려움이 있었다.
무엇이 문제인가?
오류를 추적하기가 어렵다
이제 더이상 nginx의 access log와 개발자가 개별적으로 남기는 로그만으로는 문제를 추적하기가 너무 어려워졌다.
- 위와 같이 복잡한 처리 흐름이 이어지는 경우, A 서비스에서는 아무 문제가 없이 처리되었는데 C 서비스는 아예 동작조차 하지 않았다. 프로그램상의 오류일까? 아니면 네트워크 장애인가? 어디에선가 타임아웃이 발생한 것은 아닐까?
- 이벤트를 받아 처리해야 하는 D 서비스가 동작하지 않았다면, 도대체 어디에서 문제가 발생한 것일까? 내 서비스는 문제없는데(당연하지! 내가 짰으니!!) kafka가 이벤트를 먹어버린 걸까?
다른 동료를 의심하기도 하고, 그냥 문제 해결을 포기하고 만다. 사용자는 불편을 겪고 있는데, 문제가 무엇인지 정의할 수도 없다.
비즈니스 흐름을 파악하기 어렵다
하나의 마이크로 서비스가 만들어지면, 어느 팀이든지 그 서비스를 사용할 수 있다. 중요한 행위에 대해 이벤트를 정의하고 그 이벤트를 발생시키면, 필요한 누군가가 그 이벤트를 subscribe 해서 또 다른 로직을 이어간다. 이렇게 여러 팀이 개발한 서비스들이 서로 얽히고 얽혀서 하나의 요청이 처리된다. 이렇게 되다 보니 사용자가 버튼 하나를 클릭했을 때 어떤 일이 일어나는지 파악하는 것은 거의 불가능해졌다. 한 서비스의 작은 변경사항이 전혀 예상하지 못했던 곳에서 문제를 일으키기도 한다.
예전에는 비즈니스 로직을 파악하려면 소스 코드를 한 줄 한 줄 읽어내려가면 되었지만, 지금과 같이 여러 서비스 간의 상호작용으로 하나의 기능이 완성되는 마이크로 서비스 환경에서는 서비스들의 연관 관계가 명확하지 않으면 비즈니스 로직도 명확해질 수 없다.
음.. 우리가 고객에게 제공하는 기능이 정확히 어떻게 동작하는지도 모르는 상황이 되어 버렸다.
병목 지점을 찾을 수 없다
사용자 수가 갑자기 늘어난 것도 아니고 서버의 자원이 고갈된 것도 아닌데, 응답시간이 유난히 늦어질 때가 있다. 도대체 어디가 병목인 걸까?
트레이스 시스템의 필요
이제 서비스의 모든 행위에 대한 기록을 남기고 이것을 투명하게 드러내야 할 필요성이 생겼다.
대표적인 트레이스 솔루션으로는 zipkin, lightstep, appdash 등이 있고, opentracing를 사용하면 트레이스 서버로 모든 행위에 대한 정보를 쉽게 전달할 수 있다. 이런 잘 갖춰진(?) 솔루션들은 지금 당장 설치해서 사용하기는 쉽지만, 실제 운영을 해보면 여러 어려움에 부딪힌다. 그 어려움은 대부분 이 두 가지 패턴으로 좁혀지는데,
- 기능이 너무 많다. 그래서 학습해야 할 것도 많다. 사실 우리가 필요한 기능은 그 솔루션에서 제공하는 기능의 일부분일 뿐이다. 화려한 UI와 깔끔한 Getting Started 문서에 혹해서 시작은 했지만, 정작 내가 원하는 모습에 도달하기까지 학습해야 할 것이 한둘이 아니다. 특정 솔루션의 사용법을 학습하고 있자니, 주객이 전도되는 느낌을 받을 때가 있다.
- 정작 필요한 기능은 없다. 여러 기능을 제공하고 있지만, 그 기능은 우리에게 딱 맞는 기능이 아니다. 결국, 우리 입맛에 맞게 customizing 해서 사용해야 하는데, 그 과정에도 상당한 시간과 노력이 들어간다.
어떤 솔루션을 처음 도입할 때는 그 솔루션의 문제 해결 방식과 사상을 잘 모르고 접근하는 경우가 많다. 어떤 솔루션이든 어떤 문제를 효율적으로 해결하기 위해 많은 시도를 하다가 최종적으로 최적화된 무언가가 만들어진 것일 텐데, 과정은 모른 채 최종 모습만 보고 따라 한다면 그것이 제시하는 최적의 방법으로 문제 해결을 못 하는 경우가 많다. 즉 처음에는, 내 손으로 한 땀 한 땀 구성해보고, 솔루션이 문제를 해결하는 방식에 충분한 공감이 되었을 때 그것을 사용해야 잘 활용할 수 있다.
이런 이유로 트레이스 환경을 직접 구성했다.
트레이스 환경을 구축하게된 상세한 이야기는 Go My Way #3 - 트레이싱 글에 소개되어 있다.
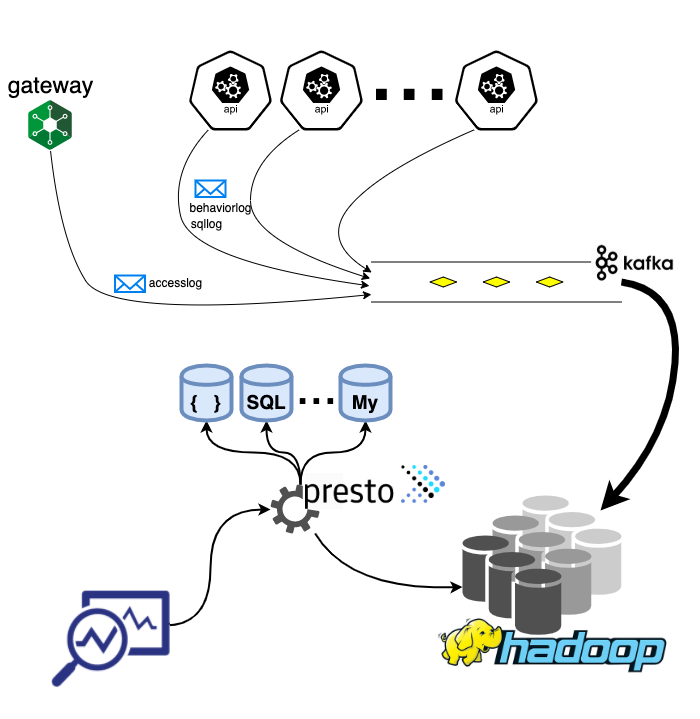
behaviorlog, sqllog
nginx에서 남기는 accesslog와 구분하기 위해 각 마이크로 서비스에서 남기는 트레이스 정보를 behaviorlog라고 부르기로 했다. nginx에서 남기는 accesslog는 단순히 사용자의 접속 정보를 보여주는 것이라면, behaviorlog는 쿠버네티스 클러스터 내부의 마이크로 서비스들의 행위를 보여주는 로그인 것이다. 그리고 sqllog는 각 마이크로 서비스에서 실행하는 쿼리 실행에 대한 로그이다.
behaviorlog와 sqllog를 남기는 규칙과 방식은 다음과 같다
식별하기
- SessionID
보통 웹 개발에서 세션(session)은 서버와 클라이언트와의 연결을 유지해주기 위해 서버에 사용자 정보를 저장하는 방법을 의미한다. 하지만 앞에서 말했듯이 우리는 JWT 인증을 사용한다. JWT 토큰 자체에 인증에 필요한 모든 정보가 포함되어 있으므로 별도의 저장 방법은 필요 없다. 그런데 무슨 SessionID?
특정 기술의 이름으로써의 세션이 아닌, 사용자가 로그인한 후부터 로그아웃하기 전까지의 행동의 묶음이라는 개념적인 의미로 생각한다면, 우리에게 세션은 한번 발급받은 JWT 토큰이 사용되는 기간을 세션이라 할 수 있다. 앞서 JWT 토큰의 구조에 관해 얘기했는데, JWT 토큰의 마지막인 서명(Sinature) 파트를 세션으로 사용하기로 했다. 즉, 한번 로그인을 해서 JWT 토큰을 획득한 후 해당 토큰을 사용한 모든 행동이 같은
SessionID로 묶인다. - RequestID
사용자의 하나의 요청으로 이루어지는 모든 행위는 모두 같은
RequestID를 가진다. - ActionID
각각의 마이크로 서비스에서 처리하는 행위는 고유의
ActionID를 가진다. - ParentActionID
나를 호출한 caller 서비스의 ActionID는
ParentActionID가 된다.
SessionID, RequestID, ActionID, ParentActionID 이 네 가지로 실제 요청이 처리되는 흐름을 정확하게 표현할 수 있다.
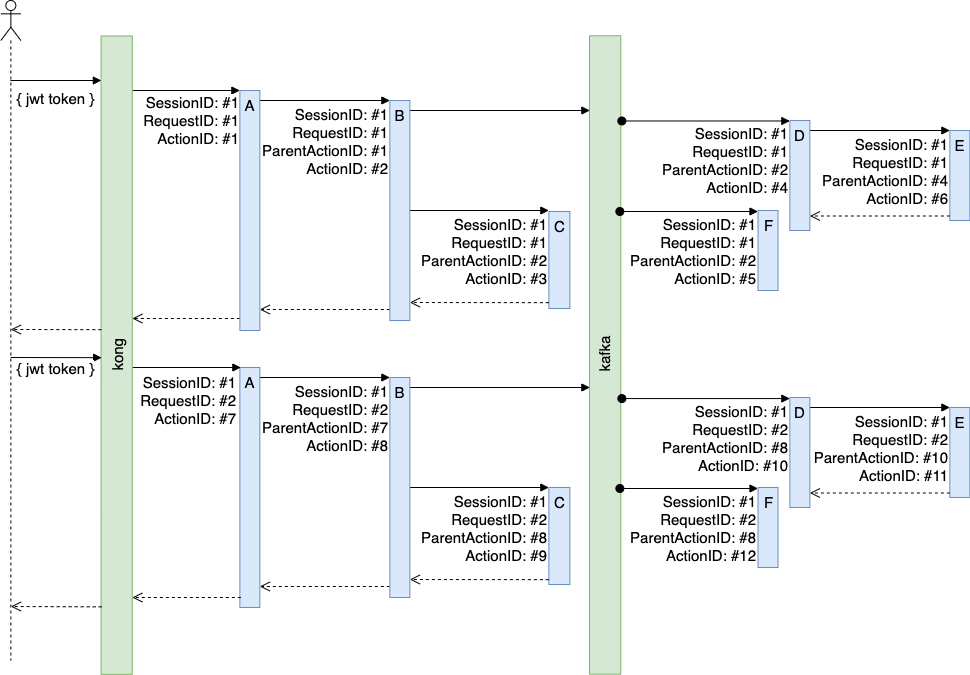
아래는 모든 마이크로 서비스가 지켜야 할 규칙이다.
- Kong에서 외부의 요청을 수신하면 새로운
RequestID를 만들어 헤더X-Request-ID에 담는다. - 각 마이크로 서비스에서는 모든 요청 처리에 대해
ActionID를 생성한다. - 다른 마이크로 서비스를 호출할 때는
RequestID와 자신의ActionID를 헤더X-Request-ID,X-Action-ID에 담는다. - 각 마이크로 서비스에서 요청 처리가 끝나면 처리 로그를 카프카로 전달한다.(토픽명: behaviorlog)
로그 식별자:
SessionID: JWT 토큰의 서명(Sinature) 파트RequestID: Header의 X-Request-IDActionID: 자신이 직접 생성한 식별자ParentActionID: Header의 X-Action-ID
- 쿼리를 실행하는 경우 쿼리, 파라미터, 실행 시간의 내용을 담아 sqllog를 남긴다. 이때 behaviorlog와 동일한 식별자를 사용한다.
로그 활용
behaviorlog, sqllog는 kong에서 남기는 accesslog와 함께 kafka를 거쳐 HDFS에 저장된다. 서로 다른 데이터베이스에 쿼리를 실행할 수 있는 SQL Engine인 Presto를 통해 필요한 데이터를 추출한다.
Zepplin을 통해 트레이스 정보를 조회
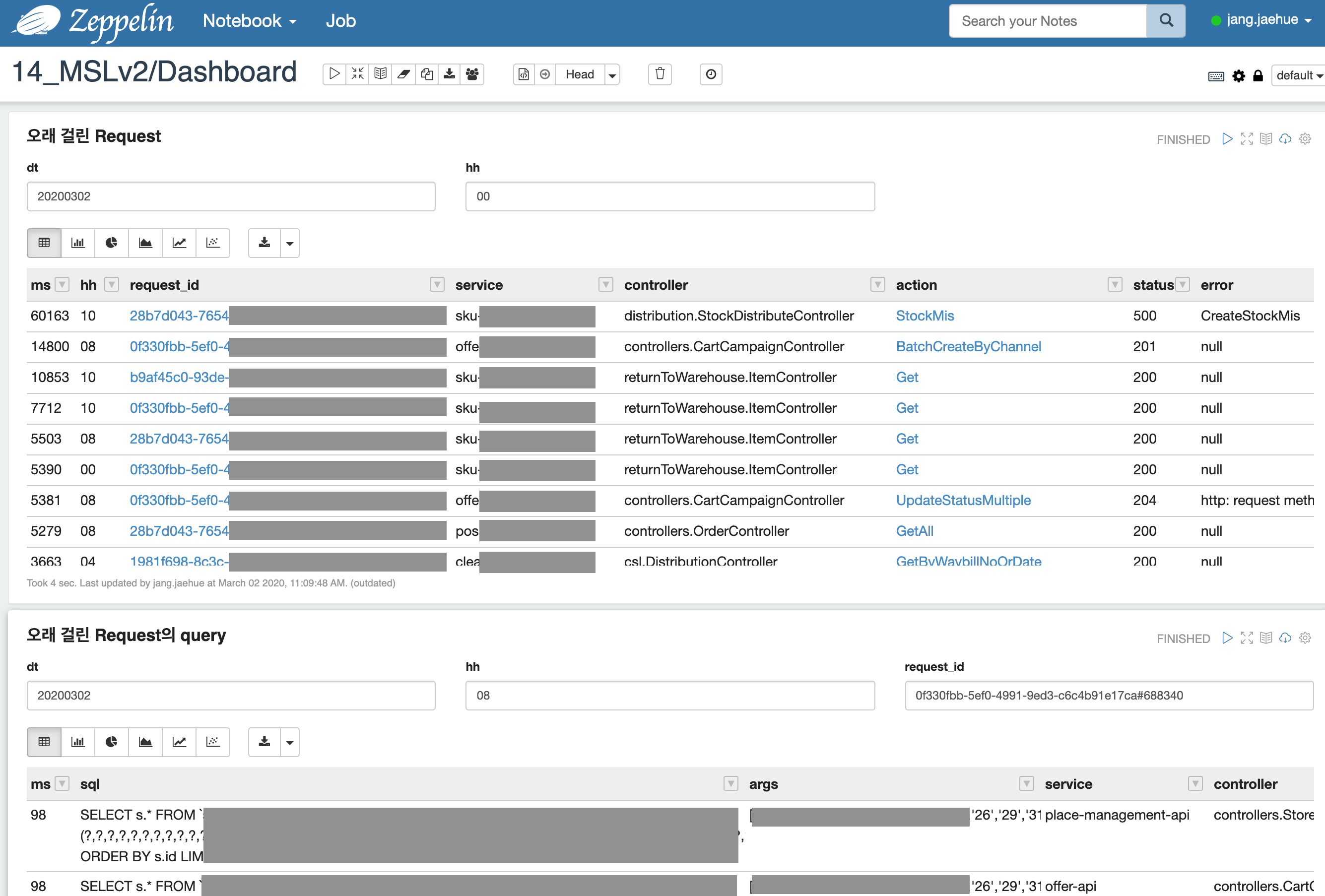
트레이스 정보를 활용하여 직접 제작한 모니터링 도구
마무리
사실 소개한 각 요소가 나름의 비하인드 스토리를 가지고 있다. “지금“과 “우리“라는 제약 속에서 오늘의 최선의 선택을 해가며 차츰차츰 형성된 것이기 때문이다. 이번 글에서는 전반적인 기술요소들을 소개했다면, 다음 글에서는 각 부분으로 시선을 좁혀서, 지금 모습에 도달하기까지의 과정을 이야기해 보고 싶다.
그리고, 마이크로 서비스는 조직문화와 분리해서는 얘기할 수 없다. 어떤 기술을 사용하고 하지 않고의 문제가 아니다. 지난 4년간 만들어왔던 조직 문화에 대해서도 후속 글을 써 보겠다.
- 아기발걸음(Baby steps): 익스트림 프로그래밍Extreme Programming, XP 원칙 중 하나. 중요한 변화를 한번에 몰아서 시도하는 것은 위험하기 때문에, 할 수 있는 최소한으로 작은 단계를 빠른 속도로 밟아나가는 방법을 말한다.