코드 한줄 없이 서비스 Dashboard 만들기(2)

지난 글에서는 전체 시스템 구성과 Kafka에 저장된 로그 데이터를 몇가지 처리를 한 다음에 hdfs에 저장하는 구성을 NiFi를 이용하여 처리하였습니다.
이번 글에서는 hdfs에 저장된 데이터를 이용하여 분당 또는 10분당 PV, UV 또는 다른 정보를 조회할 수 있는 Dashboard를 구성해보도록 하겠습니다. 주제가 "코드 한줄 없이" 이기 때문에 이 과정 역시 NiFi를 이용할 것이며 마지막 Dashboard UI 구성은 Grafana를 이용하여 구성해보도록 하겠습니다.
지난글부터 이번글까지의 전체 데이터 처리 흐름은 다음과 같습니다.
- Kafka -> HDFS -> Presto(SQL) -> InfluxDB -> Grafana
NiFi에서 SQL을 이용하여 InfluxDB에 저장하기
Dashboard UI 를 담당하는 Grafana는 시계열 데이터를 조회할 수 있는 데이터 저장소를 지원하는데 Graphite, Elasticsearch, CloudWatch, InfluxDB, OpenTSDB, KairosDB, Prometheus 를 공식적으로 지원하고 있습니다. 필자의 경우 InfluxDB를 선정 하였습니다. 이유는 대략 다음과 같습니다.
- OpenTSDB는 HBase에 데이터를 저장하기 때문에 설치 및 운영이 어려움
- Graphite에 대해서 깊게 확인해하지 않았지만 얼핏 보기에 구성이 복잡하고 하나의 컴포넌트가 아닌 여러개의 컴포넌트가 필요함
- InfluxDB는 오픈소스는 1대의 서버로만 구성할 수 있는 단점이 있지만 필자의 환경에서는 1분 단위로 aggregation 된 데이터만 저장하면 되고, 데이터가 많지 않기 때문에 1대로도 충분히 서비스 가능
HDFS에 저장된 로그 데이터를 InfluxDB에 저장하기 위해서 Presto SQL을 실행하여 POST 요청을 InfluxDB로 전송하였습니다. 이 과정을 NiFi로 이용하였는데 Flow는 다음 그림과 같습니다.
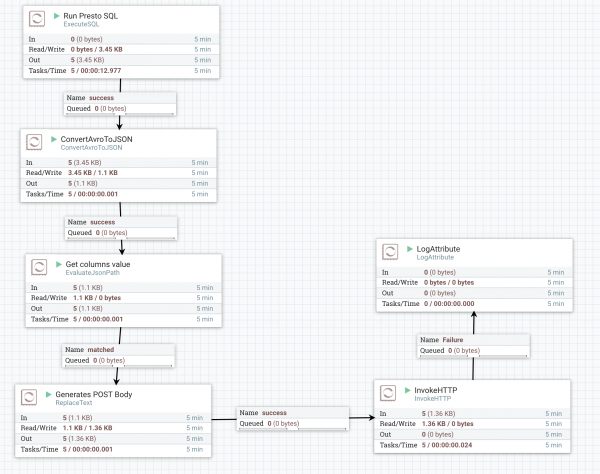
다음은 위 그림에 있는 각 Processor에 대한 설명입니다.
- Run Presto SQL: ExecuteSQL Processor
- ExecuteSQL Processor는 DBCPConnection Pool을 이용하여 SQL을 실행합니다. 따라서 Processor 설정 화면이 다음과 같이 Connection Pool을 선택하는 항목과 SQL을 입력하는 항목이 있습니다.
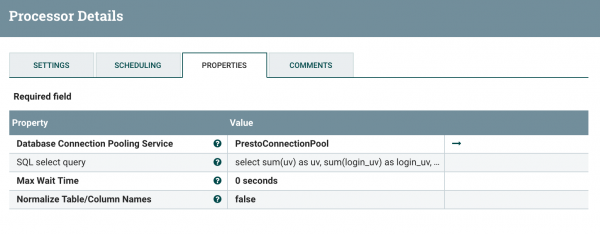 Connection Pool이 설정되지 않은 상태에서는 Value를 클릭하여 Create New 를 선택하면 다음과 같이 Connection Pool을 추가하는 화면이 나타납니다.
Connection Pool이 설정되지 않은 상태에서는 Value를 클릭하여 Create New 를 선택하면 다음과 같이 Connection Pool을 추가하는 화면이 나타납니다.
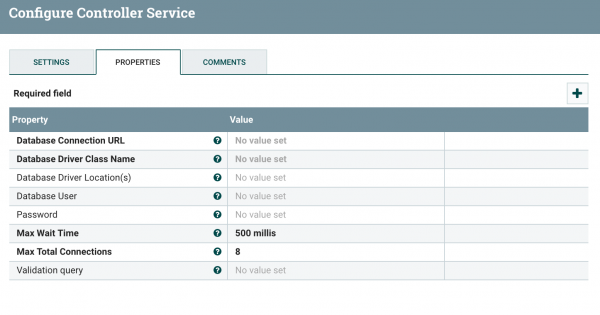 대부분의 항목은 JDBC Connection 설정 정보와 동일합니다. 다만 Database Driver Location(s) 이 항목에서 JDBC Driver의 jar 파일에 대한 패스를 지정해줍니다. NiFi 서버가 실행되는 장비에 JDBC Driver를 저장하고 그 파일의 패스를 입력하면 됩니다.
대부분의 항목은 JDBC Connection 설정 정보와 동일합니다. 다만 Database Driver Location(s) 이 항목에서 JDBC Driver의 jar 파일에 대한 패스를 지정해줍니다. NiFi 서버가 실행되는 장비에 JDBC Driver를 저장하고 그 파일의 패스를 입력하면 됩니다. - 실제 데이터를 조회하기 위해 SQL을 입력하는데 예제에서는 1분 단위로 데이터를 집계하여 저장하는 방식으로 구현하고자 하기 때문에 다음과 같이 질의를 작성하였습니다.
SQL의 where 조건을 보면 3분전 데이터를 조회하도록 되어 있는데 이것은 1편에서도 밝혔듯이 Kafka의 데이터를 hdfs에 저장하는데 최대 2분 delay가 발생하도록 설정되어 있기 때문입니다.
1 2 3 4 5 6 7 8 9 10select count(distinct cookie_id) as uv, count(distinct user_id) as login_uv, count(*) as pv from hive.default.t_log where datehour = format_datetime(now() - interval '3' minute, 'yyyyMMddHH') //datehour로 파티션되어 있음 and format_datetime(from_iso8601_timestamp(access_time), 'yyyyMMddHHmm') = format_datetime(now() - interval '3' minute, 'yyyyMMddHHmm') - 스케줄링 설정에서 1분 단위로 실행하도록 설정합니다.
- ExecuteSQL Processor는 DBCPConnection Pool을 이용하여 SQL을 실행합니다. 따라서 Processor 설정 화면이 다음과 같이 Connection Pool을 선택하는 항목과 SQL을 입력하는 항목이 있습니다.
- ConvertAvroToJSON
- ExecuteSQL Processor의 결과는 Avro 포맷입니다. 이것을 다음 단계에서 잘 활용하기 위해 JSON 포맷으로 변경합니다. NiFi 1.0 버전에서는 Avro 포맷 처리에 문제가 있어 이 기능이 정상동작하지 않습니다. 2016/12/18일 기준으로 1.1 버전이 배포되어 있으니 1.0 이상 버전을 사용하기를 권장합니다.
- Get Column Value: EvaluteJsonPath Processor
- ConvertAvroToJSON 결과는 Flow file에 JSON 형태로 데이터가 전달됩니다. 이것을 InfluxDB로 insert 요청을 하는 Http POST Body를 만들기 위해 각각의 값을 Flow Attribute로 설정하게 하는 Task 입니다.
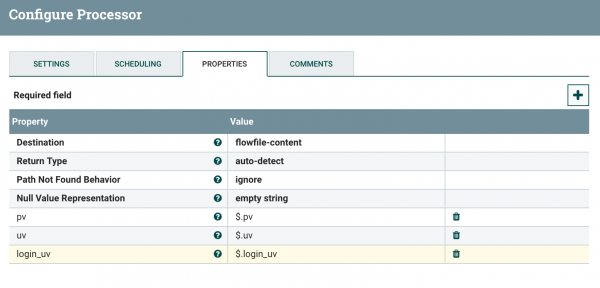
- 위 설정 화면에서 "Destination"을 flowfile-content -> flowfile-attribute로 변경합니다. 이것은 JSON에서 값을 가져와서 새로운 레코드를 만들 것인가? 기존 레코드에 속성만 추가할 것인가? 에 대한 설정입니다. 여기서는 최종 Flow file이 POST Body가 되어야 하기 때문에 flowfile-attribute로 설정합니다.
- JSON에서 값을 가져오는 것은 우측 상단의 "+" 버튼을 클릭하여 가져올 값을 추가하는데, JSON Path 문법을 이용합니다.
- ConvertAvroToJSON 결과는 Flow file에 JSON 형태로 데이터가 전달됩니다. 이것을 InfluxDB로 insert 요청을 하는 Http POST Body를 만들기 위해 각각의 값을 Flow Attribute로 설정하게 하는 Task 입니다.
- Generate Post Body: ReplaceText Processor
- 이 단계에서 Post Body를 만들어 줍니다. 이 Processor로 전달된 flowfile-content는 SQL 결과의 JSON이며 flowfile-attribute에 Post body를 만드는데 필요한 정보들이 있습니다. 따라서 flowfile-content는 필요 없기 때문에 flowfile-content 전체를 attribute를 이용하여 replace 처리합니다.
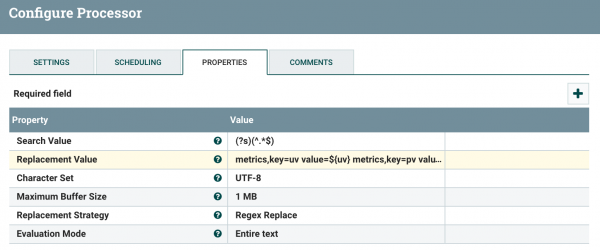
- Search Value에는 fileflow-content 전체를 설정하고, Replacement Value에 다음과 같이 InfluxDB 에 저장하기 위한 Post Body를 설정합니다.
1 2 3metrics,key=uv value=${uv} metrics,key=pv value=${pv} metrics,key=login_uv value=${login_uv} - metrics는 InfluxDB의 테이블 명이고, key는 tag 이름입니다. value는 실제 값으로 앞 단계에서 설정한 attribute 명을 사용하여 가져 왔습니다.
- NiFi 환경 설정 Editor에서 Enter를 입력하면 확인 버튼 누른것과 동일하게 창이 닫혀버리는데 Shift + Enter를 입력하면 개행문자가 추가됩니다.
- 이 단계에서 Post Body를 만들어 줍니다. 이 Processor로 전달된 flowfile-content는 SQL 결과의 JSON이며 flowfile-attribute에 Post body를 만드는데 필요한 정보들이 있습니다. 따라서 flowfile-content는 필요 없기 때문에 flowfile-content 전체를 attribute를 이용하여 replace 처리합니다.
- InvokeHTTP
- Flowfile-content로 전달된 값을 이용하여 HTTP 요청을 합니다.
이렇게 설정후 실행하면 1분 단위로 Presto SQL이 실행되면서 InfluxDB로 데이터를 저장하게 됩니다.
Grafana를 이용한 Dashboard 구성
이제 마지막 단계로 InfluxDB에 저장된 데이터를 이용하여 Grafana에 Dashboard를 구성해보겠습니다.
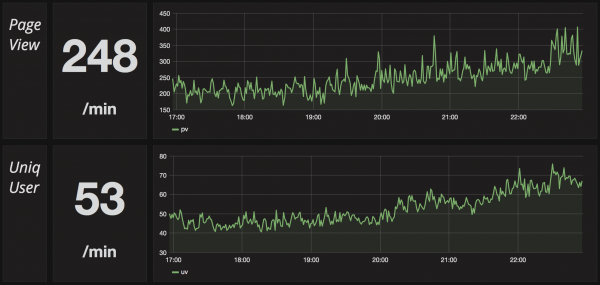
(그래프 내의 수치는 실제 서비스의 수치가 아니라 테스트 용으로 사용한 데이터입니다.)
먼저 DataSource에서 InfluxDB 연결을 추가한 다음 새로운 Dashboard를 추가합니다. 이 부분에 대한 설명은 http://www.popit.kr/influxdb_telegraf_grafana_3/ 글을 참고하세요.
Singlestat Panel 설정
Dashboard의 하나의 row에서 좌측 녹색 메뉴를 클릭하여 나타난 메뉴에서 Singlestat 를 선택하여 하나의 값이 나타나는 Panel을 추가합니다.
메뉴를 선택하게 되면 새로운 Panel이 하나 추가되고, Panel을 설정하는 화면이 나타납니다. 이 설정 화면에서 데이터를 조회하는 Query와 화면 관련 옵션을 설정합니다. 먼저 데이터 조회 질의는 다음과 같이 설정합니다.
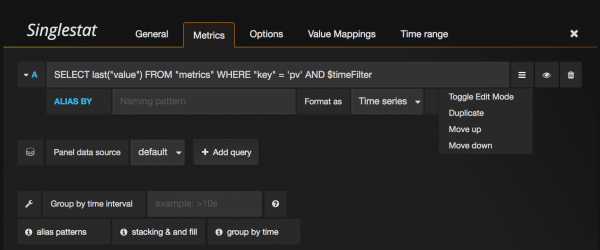
우측의 메뉴를 선택하면 화면에 보는 것과 같이 "Toggle Edit Mode" 가 나타나는데 이것을 클릭하면 Query를 Wizard로 할 것인지, Text 직접 모드로 입력할 것인지가 변경됩니다. 처음에는 Wizard 형태로 한 다음에 Query가 어떻게 만들어지는지 확인하면 그 다음부터는 Text 직접 입력 모드가 더 편하게 느껴지실 겁니다.
질의는 InfluxDB 질의는 사용하는데 $timeFilter 부분은 Grafana 상단에 사용자가 선택하는 일자 검색 조건에 선택한 값이 전달됩니다. 예를 들어 "최근 1 시간"으로 선택하면 "now() - 1h" 형태로 대체됩니다. 필자의 경우 InfluxDB Shell에서 실제 질의를 실행해보고 원하는 값이 나오는 질의를 확인한 다음에 직접 입력하는 방식으로 설정하고 있습니다.
다음으로 Options 설정에서는 Text의 크기와 예제에서와 같이 "/min" 등과 같은 Prefix, Postfix 텍스트 입력과 크기를 설정할 수 있습니다.
모든 설정이 완료되면 반드시 저장버튼을 클릭하여 설정을 반드시 저장해야 합니다. 저장되지 않은 설정은 화면이 Reload 되었을 때 모든 설정이 사라지게 됩니다.
Graph Panel 설정
Graph Panel 설정도 동일합니다. Graph Panel 설정 시도 Singlestat Panel 설정과 비슷하게 설정하였으며 질의는 다음과 같이 입력하였습니다.
1SELECT mean("value") FROM "metrics" WHERE "key" = 'pv' AND $timeFilter GROUP BY time($interval) fill(null)
GROUP BY 절에 있는 $interval은 Time Filter에 따라 Grafana가 적절한 값을 선택하여 전달한다. 예를 들어 Last 6 Hour로 선택하면 10m (10분)으로 Group by가 되고, Last 1 Hour로 할 경우 1m(1분) 단위로 됩니다. 이 값을 고정된 값으로 하고 싶은 경우 "GROUP BY time(10m)" 과 같이 지정할 수 있습니다.
글을 마치며
지금까지 1편, 2편으로 나누어 추가 프로그램 코드 개발없이 Kafka 에 저장된 데이터를 Grafana에 Dashboard 를 구성하는 방법에 대해 설명드렸습니다. 빠르게 기능을 추가하고 사용자의 반응을 확인하고, 바로 대응을 해야하는 최근의 서비스 트렌드에서 서비스의 전체 지표 뿐만 아니라 각 기능, 화면 단위의 지표를 보는 것도 아주 중요합니다. 따라서 지표를 만들어서 제공하는 것이 어려운 작업이 되면 그 서비스는 이미 사용자의 반응에 대한 대응 능력이 떨어지는 서비스라 할 수 있습니다. 본 연재에서 살펴본 것 처럼 가능한 쉽고 빠르게 지표를 관리할 수 있는 환경을 구성하는 것도 좋은 서비스를 운영하는 핵심 경쟁력이라 생각합니다.
최근의 데이터 처리 오픈소스는 그 진화의 속도가 아주 빠르며 엔터프라이즈 솔루션을 능가하는 고급스러운 기능까지 포함하고 있는 경우도 많습니다. 물론 글에서 보는 것 처럼 하나의 솔루션으로 이런 구성을 할 수 없기 때문에 다양한 솔루션의 조합 및 각각의 서비스 환경(데이터 용량, Latency 등)에 맞는 솔루션 및 아키텍처를 선정하는 것이 무엇보다 중요하다고 할 수 있습니다.
이글에서 소개된 방법만 아니라 다양한 방법 및 솔루션이 많은데 각자 자신들의 환경에 적합한 지표 관리 시스템을 구성하여 서비스 운영에 적극 활용할 수 있기를 바랍니다.