NiFi를 이용한 빅데이터 플랫폼 개선

복잡해지는 빅데이터 클러스터 간에 데이터 동기화와 투명한 데이터 관리를 위한 고민을 공유하고, 이 문제를 해결하기 위한 오픈소스인 Apache NiFi를 소개하겠습니다.
연관 글: 멜론-빅데이터-이야기
소개
어떤 시스템이나 그렇듯 빅데이터 시스템도 여느 시스템과 같이 비즈니스 요건에 따라 점점 진화하게 되는데, 2011년 빅데이터로 불리는 하둡과 에코 시스템 모습과 현재의 빅데이터 시스템은 많은 부분 변화가 있었습니다. 처음 Melon에서도 아래 그림과 같이 분석 클러스터와 서비스 클러스터로 구성되어 서비스했습니다.
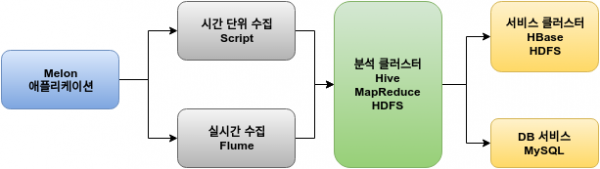
[Melon 빅데이터 1차 아키텍처]
그러다 다양한 분석 요건의 추가로 부하가 발생하고, 새로운 조직의 신설로 통계 클러스터를 별도로 분리하게 되었습니다.

[Melon 빅데이터 2차 아키텍처]
클러스터 분리 따른 문제
클러스터 분리는 자원 독립으로 시스템 간 영향을 최소화할 수 있는 장점을 주는 반면, 다음과 같은 여러 단점도 발생하게 됩니다.
- 데이터 복제로 인한 추가 네트워크 트래픽 비용 발생입니다. 대부분 클러스터에서 공유되는 주요 이력 데이터가 있습니다. 이를 복제하기 위해 시스템은 일정 간격으로 데이터를 복제하며 네트워크 트래픽을 사용하게 됩니다. 많으면 시간당 수십~수백 GB의 데이터가 옮겨가므로, 클러스터 간 네트워크 설계와 시스템 설계를 최대한 효율적으로 구성해야 합니다. 예를 들어 Hadoop Rack Awareness 설정과 네트워크 분리, 확장 가능한 네트워크 구조 등을 말합니다.
- 데이터 복제로 인한, 추가 디스크 비용이 발생합니다. 이는 회사에 따라 다르겠지만 많으면 수백~수천 GB의 데이터 중복이 발생 됩니다. 이를 위해 원천 데이터 복제는 최대한 지양하며, 중간 테이블(특정 단위로 그룹화)을 복제합니다.
- 중복된 분석 작업이 발생합니다. 클러스터 분리는 사용 주체도 분리될 수 있습니다. 이때 서로의 분석 작업의 내용을 공유할 수 있는 시스템이 없다면 유사한 분석이 서로 다른 클러스터에서 분석될 수 있어, 인적 또는 클러스터 자원이 비효율적으로 운영될 수 있습니다.
- 무분별한 데이터 동기화와 데이터 접근으로 인해 데이터 품질 및 보안 문제가 발생할 수 있습니다. 데이터의 중앙 통제가 어렵다는 뜻으로 데이터 메타(도메인)의 이원화(오염)와 데이터에 대한 상세한 권한 관리(테이블 또는 컬럼 단위)가 힘듭니다.
- 데이터 흐름의 모니터링이 어렵습니다. 보통 하둡 클러스터 간의 데이터 복제는 DistCp 명령을 통해 하는데, 이는 복제 데이터가 어디로 왔는지 업무 담당자가 아니면 파악하기 힘듭니다. 즉, 데이터 전송이 투명하지 않아 애플리케이션별로 어떤 데이터를 어떠한 방식으로 분석하는지 담당자만 알 수 있고, 다른 사람은 파악하기 힘듭니다.
이 밖에 제가 생각하지 못한 여러 가지 문제가 있을 수 있겠지만, 그런데도 클러스터를 분리해야 하는 이유는 한 가지로만 말씀드린다면,
자유롭게 부서별로 빅데이터를 통해 통찰력을 얻을 수 있고, 이를 통해 서비스가 발전한다는 것입니다.
특정 분석 부서 또는 분석가가 모든 업무와 중요성, 적시성 등 비즈니스 전반을 파악하기는 힘듭니다. Melon 역시 특정 분석 조직들이 모든 것을 다 분석, 서비스화하기는 힘듭니다. 중요하게 생각하는 비즈니스 기준도 다를뿐더러, 우선순위도 다르기 때문입니다. 빅데이터를 조직별로 위임함으로써 생기는 비즈니스적 가치는 따로 언급할 필요가 없을 것 같습니다.
다만 왜 통합된 클러스터 하나를 사용할 수 없느냐는 여러 이견이 있으시겠지만, 제 짧은 생각으로는 지역적으로 클러스터가 분리(데이터 로컬리티 유지) 될 수 있으며, 부서별로 클러스터 자원(데이터 용량과 컴퓨팅 파워)을 나누고, 접근 권한을 관리하며, 다양한 솔루션을 부서 특성에 맞게 자율적으로 구성할 수 있으므로 분리를 합니다. Melon에서도 아직 부서별로 자율성을 보장하는 것은 아니지만 꾸준한 교육을 토대로 단순 SQL on Hadoop만이 아닌, 필요에 따라 다양한 오픈 소스(Spark, TensorFlow 등)를 업무 담당자가 실험하고, 그 결과를 서비스할 수 있게 할 계획입니다.
본 글의 내용과는 차이가 있지만, 빅데이터의 멀티 테넌시 아키텍처에 대한 내용입니다. 조직의 성장과 함께 자연스럽게 유사한 고민을 하고 있습니다.
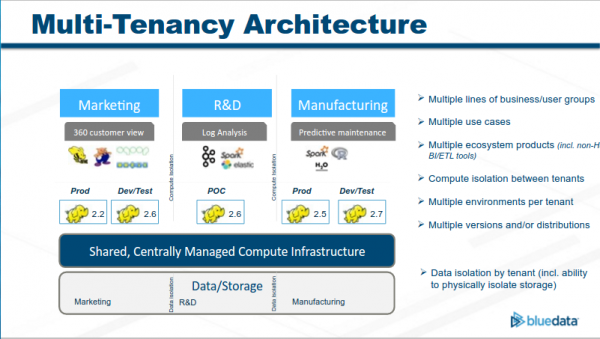
자료 출처: http://slideplayer.com/slide/8113990/
Melon의 새 빅데이터 플랫폼
업무 단위로 빅데이터 플랫폼을 위임하기 위해 Melon에서는 다음과 목표를 세웠습니다. 이 목표들은 아직 달성된 것이 아닌, 진행 되는 것이며, 혹시 독자분들 중에서 다른 추가적인 의견이 있으시면 댓글 부탁드리겠습니다.
- 조직 간 클러스터의 영향도 최소화
- Data Architect 조직의 데이터 품질 유지 (데이터 표준, 중복 업무 등)
- 유연한 데이터 필터 또는 변경 기능
- 클러스터 간 데이터 이동 및 추적
- 데이터 실시간 수집 및 모니터링 강화
이 목표 중 데이터 이동과 추적을 위해 UI 환경이 제공되는 하둡 Work Flow와 Data Flow, Job Scheduler 오픈 소스(Airflow, Azkaban, NiFi, StreamSets, Chronos, Jenkins)들을 검토했습니다. Job Scheduler의 경우 여러 시스템(Kafka, Flume, HDFS, HBase, ElasticSearch, SFTP 등)과 통합 시, 모두 애플리케이션에서 개발해야 한다는 부담이 있습니다. 사용이 비교적 쉽고, Melon에서는 Jenkins를 많이 사용하지만, 기능적으로 부족한 점이 많습니다. 하둡 Work Flow도 마찬가지로 HDFS는 지원해주지만, 다른 시스템과의 통합은 부족한 상황이라 검토를 중단했습니다. ETL로 Melon에서는 Informatica를 사용하고 있지만, 이는 Connector 구매에 대한 비용 이슈와 실시간 수집이 필요함으로 검토하지 않았습니다. Data Flow 엔진은 데이터의 이력 추적이 가능하고, 여러 시스템과 연동이 편리하게 되며, 다양한 확장 기능(스크립트, 확장 플러그인)으로 운영이 편리합니다.
오픈 소스 Data Flow 시스템인 NiFi와 StreamSets을 비교 검토해봤습니다. 검토 기간이 길지 않고, 실제 업무를 적용해 보지 않아 검토 오류도 있을 수 있겠지만, 다음과 같은 차이가 있었습니다.
| 구분 | Apache NiFi | StreamSets |
| UI | Process Group 기반의 Data Flow 관리
Process Group 간 데이터 이동 가능 약간 어려움 |
Pipeline 기반의 Data Flow 관리
Pipeline 간 데이터 이동 불가능 직관적 인터페이스 |
| 인증 | SSL X.509 (인증서 기반) 인증
LDAP 지원 설정이 어려움 |
자체 제공
LDAP 지원 설정이 쉬움 |
| 클러스터 간 통신 | Site-to-Site 지원 | Kafka 이용 |
| 이력 추적 | 가능 | Pipeline 내 가능 |
| 클러스터링 | 자체 클러스터링 | Spark on YARN/Mesos |
| 스케줄러 | 간격 실행
클러스터 환경에서 Primary 노드 실행 Cron 스케줄러 실행 |
간격 실행 |
| 기술지원 | 호튼웍스, Apache NiFi Group | StreamSets |
| Stack Overflow 기타 논의 | ||
StreamSets을 상용 수준으로 사용해보지 않았지만 StreamSets의 UI와 Data Flow가 직관적으로 관리 할 수 있었습니다. 클러스터링은 Spark on YARN/Mesos 위에서 구동되며, 복잡한 Data Flow 또는 지역 간 데이터 이동이 없는 회사의 경우 StreamSets을 조심히 추천해 드립니다.
Melon의 경우, Process Group 간의 연결, Cron 스케줄러, 데이터 추적 기능 그리고 자체 클러스터를 가지고 있는 NiFi를 선택하게 되었습니다. Melon에서도 Spark를 운영하고는 있지만, 문제가 있는 경우 재시작을 하는 수준으로 사용하고 있고, NiFi의 클러스터링 기능은 웹 애플리케이션 이중화 정도의 개념만으로 충분히 안정적인 클러스터를 구축할 수 있었습니다. 물론 데이터 유실이 중요한 문제이고, 초대형 시스템인 경우 많은 부분 고민을 해야 합니다(이중화 참고 자료). 온리인 자료 역시 두 솔루션 모두 한글 자료는 많이 없으며, 커뮤니티인 경우 Apache에 소속된 NiFi가 좀 더 활발합니다. 아래 그림은 NiFi를 중심으로 한 Melon의 빅데이터 시스템입니다.
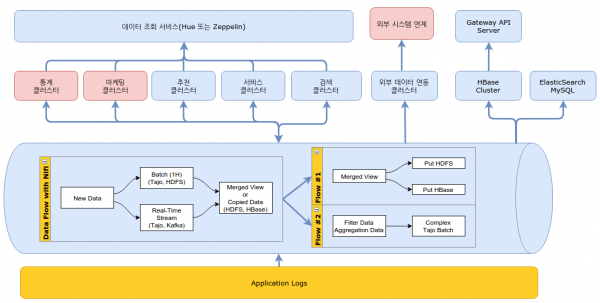
[Melon 빅데이터 3차 아키텍처]
클러스터를 조직, 업무별로 분리하여 영향도를 최소화했으며, NiFi는 간단한 데이터 필터와 수정 기능을 제공했습니다. 복잡한 로직은 Script 또는 별도 애플리케이션을 Process로 개발하여 공통화시킬 수 있었습니다. NiFi Provenance 기능은 데이터의 생성부터 종료까지 추적과 모니터링을 할 수 있어서 클러스터 간이 데이터 이동을 투명하게 관리할 수 있습니다. 150개가 넘는 프로세스는 Flume, Kafka, HDFS, Elastic Search, HBase, HTTP, FTP, SSH, SQL, SFTP 등 다양한 기능을 제공했고, 이를 이용하여 Kafka에서 실시간으로 데이터를 수집하고, HDFS에서 1시간 단위로 배치 수집을 해 장애로 인한 누락을 방지하고, 이러한 Data Flow를 통합(merge)하여 HBase에 저장하면, 비교적 간단한 작업으로 Lambda Architecture의 수집 부분을 개발할 수 있습니다.
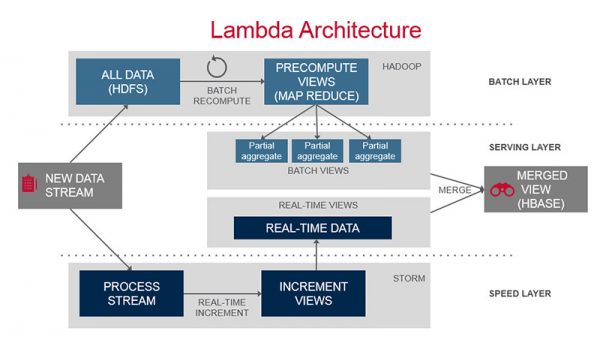 (이미지:http://www.mapr.com/sites/default/files/otherpageimages/lambda-architecture-2-800.jpg)
(이미지:http://www.mapr.com/sites/default/files/otherpageimages/lambda-architecture-2-800.jpg)
이렇듯이 NiFi를 데이터 수집과 전송의 중심에 둠으로써 새로운 빅데이터 시스템의 여러 가지 목표를 달성할 수 있었습니다. 다만 서두에서 단점으로 불필요한 추가 네트워크 트래픽 및 디스크 용량 필요했습니다.
이 연재를 시작으로 Apache NiFi의 설치(클러스터 기반)부터 Data Flow 설계, 확장까지 소개해 드리도록 하겠습니다. 다음 편을 기대해주세요.
긴 글 읽어주셔서 감사합니다.