이벤트 주도 아키텍처는 어떤 이점을 주는가?

미완의 글인데... 코로나19로 중국에 가지 못해서 쓰다만 글을 그냥 노출합니다. ㅡㅡ^
페친이 공유한 기사는 보자마자 좋은 글이란 느낌이 왔다. 그래서, 읽어 보려고 클릭 했는데, 기사 앞부분에서 만난 문구부터 알듯 모를듯 해서 진도가 안 나갔다.
이 아키텍처를 이용하면 룰 기반 서비스를 해체하고 이벤트에 기반해 데이터를 공유하는 마이크로서비스를 만들 수 있다.
룰 기반 서비스를 해체한다는 것이 무슨 말 일까? 몇 번 생각해봐도 명쾌하지 않아 원문을 찾아 보았다. 원문은 아래와 같이 쓰고 있다.
These architectures enable the decoupling of rule-based services to microservices that consume and share data based on events
해체란 말에는 별다른 감이 오지 않는데, decoupling이란 표현을 보니 어떤 의미인지 추정할 수 있었다. 글을 읽고 이해하는 과정이 철저하게 자신의 경험에 묶여 있음을 확인하는 상황이다. 필자의 경우 해체라는 우리말을 프로그래밍 관련 학습 과정에서 쓰거나 들어본 일이 없다. 그래서, 해체란 말은 생소한 반면, decoupling은 수도 없이 읽었고, 스스로도 수차례 하던 말이다. 번역의 좋고 나쁨을 따지려는 것이 아니라 필자의 경험이 그렇다는 뜻이다.
결국 원문을 찾아 다시 읽으면서 소화1)한 내용이 이벤트 주도 아키텍처에 대해 관심있는 다른 독자들에게 유익하기 기대하면 글을 쓴다.
룰 기반 서비스를 해체한다?
처음 해석이 되지 않던 문구부터 보자. 이 말은 복수의 서비스가 규칙(Rule)에 기반해서 묶여 있는 부분을 풀어낸다는 뜻이다. 여기서 서비스는 프로그램 덩어리를 말한다고 전제하자. 개발자들이 서비스라고 말할 때 많은 경우 프로그램 구현 단위2)를 말한다. 그 프로그램들의 기능을 늘려가는 방법이 API 혹은 함수(메소드) 호출 등의 형태로 연결하는 것이다. 그런데 그 연결 과정에 어떤 규칙이 엮여 있다는 뜻이다. 그런 규칙이 종종 암묵적인 경우가 있는데, 그렇게 되면 사람들의 기억에 의존한다. 따라서 이를 부정적 결합(coupling)으로 인식하거나 분류하는 경우가 많다. 마침 오전에 하던 일이 있어서 그걸 예로 들어 설명해보겠다.
넓은 지역의 매장을 관리하는 관리 조직이 있다고 가정하자. 매장을 관리하는 지역 사무소를 지사라고 부르기로 하자. SQL 문법으로 지사 데이터를 추출하려고 가정하면 아래와 유사한 SQL 이 될 수 있다. 여기서 branch는 지사 데이터를 보관하는 테이블이고, used는 이력을 보관하기 위한 현재시점의 유효성을 나타내는 필드이다. 0 이면 이제는 쓰지 않는 지사고, 1이면 유효한 지사라고 구분한다고 가정하자.
1select * from branch where used = 1
이런 식으로 추출하면 될 줄 알았더니, 추출한 데이터를 통해 파악해보면 아래와 같이 SQL을 작성해야 했다.
1 2 3select * from branch where used = 1 and parent is null and left(name, 1 ) <> 'V'
왜 그런가? 알고보니, 지사가 계층 구조를 이루고 있었다. 그래서, 상위 지사를 구하려면 parent is null 과 같이 조건을 제한해야 하고, 반대로 말단의 지사를 지정하려면 parent is not null 과 같은 식이 필요했다. 상식적인 규칙이다. 다만, 이런 사연이 겉으로 드러나지 않고 프로그램 안에만 존재하면 암묵적인 규칙이 될 가능성이 높다는 사실만 기억하자.
계속 사례를 살펴보자. 그 뒤에 또 사연이 생겼다. 다른 이유로 보관이 필요한 데이터 중에 지사 이름(name)이 V로 시작하는 데이터가 유지되고 있었다. 다른 프로그램에 영향을 미칠 수 있어 함부로 제거할 수는 없다. 하지만, 그걸 걸러내야 원하는 데이터를 얻을 수 있다. 필자가 예로 들은 이런 상황은 흔히 발생하는 상황이 아닐까 싶다.
지금까지 쭉 언급한 사항들이 바로 서비스를 묶이게 하는 규칙의 예가 될 수 있다. 여기서 묶인다는 부정적 어감을 주는 표현이다. 부정적으로 쓰는 이유는 규칙이 드러나지 않고 숨겨져 있어 다른 사람에게 혹은 다른 일을 하려고 할 때, 발목을 잡을 수 있기 때문이다. 한때, 유행처럼 쓰이던 기술부채Technical Debt라는 표현과도 무관하지 않다. 암묵적인 규칙이 얽히고 늘어나면 결국 수정이 어려워져 시스템이 사업의 발목을 잡을 수 있다.
규칙이 암묵적이란 의미는?
서비스 사이 연결은 함수나 API 호출로 한다고 했다. 앞에서 설명한 SQL을 담고 있는 서비스가 API로 연결을 제공한다고 가정해보자. 아래와 같은 식으로 말이다.
1http://domain/service/...
이 경우 최상위 지사와 하위 지사가 드러나게 구분할 때 이를 명시(明示)적이라고 말한다. 분명하게 보인다는 한자어다. 명시적으로 최상위 지사를 구하는 예시는 이런 식이다.
1http://domain/service/getRootBranches
상위가 위와 같다면, 이에 상응하여 하위의 지사는 아래와 같은 식으로 얻을 수 있다. 이런 것은 API 호출을 위한 필수적인 규칙이자 서비스 사이의 자연스런 약속이다.
1http://domain/service/getNodeBranches?parent=16
parent=16이라고 쓴 부분은 특정 최상위 지사를 지칭하는 방법으로 16이라는 숫자를 쓴다는 가정으로 만든 예제다. 이들이 명시적인 이유는 서비스를 호출하는 URL에서 규칙이 분명하게 드러나기 때문이다. 앞서 SQL에서 parentbranch is null 이란 조건으로 예를 든 내용이 getRootBranches라는 이름을 통해 프로그램 세부 내용없이도 드러난다. 그래서, 비교적 자유롭게 호출할 수 있다.
또한, parentbranch is not null 이라는 하위 지사도 상위 지사를 지정하는 파라미터 parent와 getNodeBranches 라는 이름으로 명확하게 그 규칙을 드러내고 있다.
그럼 암묵적인 규칙은 어떤 것이냐? 이 경우도 예를 들어 설명해보자. 앞서 SQL 예제에 있던 and left(name, 1 ) <> 'V' 라는 구문을 예로 들 수 있다. 데이터 관리하는 쪽의 사정으로 이렇게 데이터를 유지하는 사례는 흔하게 존재한다. 이런 데이터 보관 방식 자체가 문제가 있는 것은 아니다. 이런 특정 규칙이 명시적으로 드러나지 않고 암묵적인 형태로 존재하다가 다른 서비스나 데이터베이스를 함께 쓰는 프로그램에 의도하지 않는 영향을 주는 것이 문제7)다.
예를 들어, 비슷한 이유로 V로 시작하지 않고 M으로 시작하는 다른 지사도 걸러내야 한다면 어떻게 될까? 앞서 설명했던 API의 결과 값이 알수없는 이유로 달라져 장애나 에러가 발생한다.
바로 이와 같은 상황이 필자가 인용한 기사에서 말하는 규칙 기반으로 서비스가 결합한 사례의 하나라고 할 수 있다. 그리고, 그 규칙 자체가 아니라 바로 그 규칙의 존재 형태가 암묵적인 점이 연결의 잠재적 문제 요소라고 말할 수 있다. 이번에는 기사에서 번역하며 소개된 '해체', 영어로는 decoupling 이란 말을 살펴보자.
해체한다는 말을 다시 돌아보기
해체할 대상이 무엇인가? 필자가 보기에 번역한 글 이해가 어려운 이유가 여기에 있다. 서비스 사이의 관계 자체를 해체하라는 말로 오인할 수 있는데, 실제 해체의 의미는 요소를 재구성해야 한다는 뜻이기 때문이다. 해체할 대상은 바로 서비스간 관계에 따르는 규칙이 암묵적이라는 점 자체다. 암묵적인 것을 분명하게 드러나게 하기 위해서 관계를 구현하는 방식과 함께 서비스 내부 구성을 바꿔야 한다. 개발자들은 프로그램 구성을 바꾸는 리팩토링과 매우 유사하지만, 아키텍처 변경을 수반하는 것도 리팩토링이라 부를 수 있는지는 모르겠다.
실제로 개발 조직의 생산성이 떨어지는 경우를 비공식적으로 조사한 일이 있는데, 개발자들이 개발에 시간을 들이는 비중에 너무나도 많은 시간을 영향도 분석에 써서 깜짝 놀란 일이 있다. 현장에서 암묵적 규칙은 여러 사람이 작성한 것들이 장시간에 걸쳐 켜켜이 쌓여 복잡하기 이를데 없는 경우가 많다. 하지만, 비즈니스 규칙은 필연적인 것으로 제거할 수는 없다. 우리가 차세대 프로젝트란 것을 목격하는 장면이 대부분 이 현상과 깊은 관련이 있다.
딴 길로 이야기가 새는 것을 막기 위해 인용한 기사의 문구를 다시 보자.
이 아키텍처를 이용하면 룰 기반 서비스를 해체하고 이벤트에 기반해 데이터를 공유하는 마이크로서비스를 만들 수 있다. These architectures enable the decoupling of rule-based services to microservices that consume and share data based on events
위 기사를 인용하고 필자가 설명을 덧붙이며 주장하는 바는 암묵적인 규칙을 명시적인 형태로 변경하는 일이 중요하다는 점이다. 그것이 이벤트에 기반해 데이터를 공유하는 마이크로 서비스 만들기와 무슨 관련이 있는가? 운 좋게도 필자가 최근에 하는 일에서 힌트를 얻을 수 있어 글을 쓸 수 있었다.
레거시 시스템과 연결하기
아래는 필자가 최근 레거시 데이터와 불일치 문제를 해결하려고 그린 그림이다. 먼저 배치 프로그램 형태의 프로그램 로직이 너무 복잡해 결과가 정확하지 않았다. 그래서, 구조를 개선하자고 개발자들과 목표를 공감하고 프로젝트를 진행하고 있다. Etract, Transform, Load이라고 해서 고가의 외산 ETL 도구를 떠올리는 분이 있을 수 있지만, 필자의 업무 환경은 Go 프로그래밍 환경에 상용 도구는 쓰지 않는다. ETL이라 표현은 단순히 개념적 프로그램 구분으로 쓸 뿐이다. 그 과정을 함께 따라가다 보면 관계를 명시적으로 하는 일과 이벤트 기반으로 데이터를 공유하는 일의 연결점을 찾을 수 있다고 믿는다. 다만 인용한 원문이 미국의 현실에 기초하고 있다면, 필자의 사례는 대한민국 다수 기업용 프로그램이 처한 현실에 기초해서 이를 설명하려고 한다.
누가 알겠는가? 이글이 단초가 되어서 차세대 프로젝트를 반복하는 늪에서 단 하나의 기업이라도 구해낼 수 있다면 더 바랄 것 없는 기적2)이 아니겠는가?
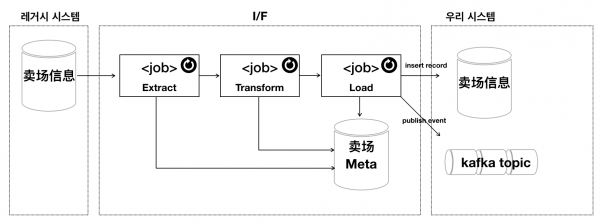
레거시 시스템과 데이터 연동 구조
Extract 남의 데이터를 추출하라
추출이라는 영어 단어 Extract를 써놓고 남의 데이터라고 덧붙인 이유가 있다. 가장 왼쪽에 점선 박스에 넣은 데이터는 레거시 시스템이기 때문이다. 레거시 시스템의 특징은 새로 만드려는 목적 시스템이 어쩔 수 없이 의존하지만, 다른 개발자가 만들었거나 심지어 개발한 사람이 사라지기도 하는 특성을 짧은 문구로 설명하려고 했다. 더구나 내가 모르는 이유로 변경되기도 하는데 그게 핵심이다.
예를 들어보자. 앞서 소개한 예시를 계속 사용하자. 처음에 소개한 SQL에 일부 조건을 추가했다. BranchManger 테이블은 각 지사의 관리자 관계를 보관하는 테이블인데, 지사 구분자(brand code)를 기준으로 지사별 관리자 목록을 뽑는 SQL이다. 관리자 발령 이력을 보관해야 하기 때문에 현황을 알려면 날짜를 기준으로 한번 더 걸러내야 하는데 그것을 SQL로 표현한 것이 마지막 줄 '202001' between b.StartYearMonth and b.endYearMonth 이다.
1 2 3 4 5 6 7select * from branch as a inner join BranchManager as b on a.code = b.branchCode where a.used = 1 and b.used = 1 and a.parent is not null and left(a.name, 1 ) <> 'V' and '202001' between b.StartYearMonth and b.endYearMonth
이렇게 비즈니스 규칙을 추출했다. 추출이란 단어와 규칙이란 단어를 유심히 기억하자.
Transform 목적에 따라 변형하라
위 그림에서 세 개의 점선 박스가 있는데, 첫번째는 레거시 시스템이고 가장 마지막이 우리의 목적 시스템이다. 즉, 우리가 만들려고 하는 대상이다. 그 사이가 바로 인터페이스 구간이다. 양끝의 두 시스템은 목적이 다르기 때문에 레거시에서 추출한 데이터를 목적에 맞게 변환해야 한다. 이 작업은 대부분의 배치 작업에서 어떤 형태로든 다들 하는 것이다. 특별할 것이 없다.
Load "비즈니스 규칙 변화가 드러나도록" 데이터를 적재하라
Load는 데이터 적재인데, 필자가 "비즈니스 규칙 변화가 드러나도록" 이라고 수식을 붙였다. 최근 우리 팀이 하고 있는 일의 목표이기도 하고 바로 이 글에서 설명하려고 시도하는 암묵적인 것을 명시적으로 만드는 일이기도 하기 때문이다. 어떻게 할 수 있을까? 너무나 다양한 방법이 있고, 아직 우리가 한 벌의 구현을 하지 않아서 구체적으로 설명하지는 못하겠다.3)
이 글에선 아래 그림에서 표현한 내용으로 논리적인 설명을 하겠다. Load 구성요소를 구현하는 데에는 세 가지 갈래가 있다.
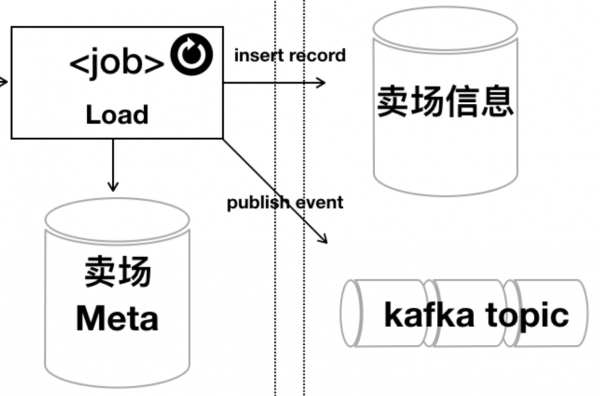
Load를 구현하는 세 가지 갈래
먼저 하나는 외부 즉 레거시 데이터 변화를 해석하는 정보를 메타 데이터로 기록한다. 바로 이 부분이 필자가 우리 팀에 제공하는 고유한 아이디어4)이다. 앞의 예제를 계속 유지해보자. 앞에서 살펴본 SQL 이다.
1 2 3select * from branch where used = 1 and parent is null and left(name, 1 ) <> 'V'
어느날 이렇게 추출한 결과가 전날의 결과와 다르다고 가정해보자. 다르다는 판단을 하려고 해도 보관하는 데이터가 필요하다. 예를 들어 전날 위 SQL을 수행한 결과가 20 이었다면, 바로 그 20과 위 SQL 나타내는 식별자를 보관해둬야 하는데 그것이 메타 데이터의 예시다. 그리고 나서 결과가 20을 예상했는데, 다음날 25가 나왔다면 어떻게 해야 할까? 남의 데이터 때문에 원인을 분석해봐야 한다.
메타데이터 덕분에 서비스 담당자에게 통지할 수 있는 모니터링 기능이 구현되는 것이다. 그리고 담당자가 파악해보니 지사 이름(name)이 M으로 시작되는 지사 데이터가 추가되었는데 이를 빼고 가져와야 한다는 사실을 파악했다. 그러면, 해당 규칙이 변경된 것이고, 규칙이 변경된 것과 함께 수정된 SQL을 나타내는 식별자를 보관해둬야 한다. 같은 목적의 SQL 이지만 바뀐 것을 표현하기 위해 이번에는 버전이 필요할 수 있다.
메타데이터는 사람을 위한 것이라면 이벤트는 기계를 위한 것
적제 구현의 세 갈래를 설명 중 하나가 메터데이터 보관임을 설명했다. 다른 하나는 배치에서 흔히 하는 목적 데이터 저장이다. 레거시 원본을 추출(Extract)하여 변형(Transform)한 후에 목적 시스템의 데이터베이스 스키마에 맞춰 데이터를 보관하면 된다. 그런데, 만일 이렇게 데이터를 저장할 때 앞서 언급한 규칙의 변경에 따라 목적 데이터의 변경 폭이 달라지면 어떻게 될까? 예를 들어, 지사 숫자가 달라지는 정도가 아니라 지사에 추가로 계층이 생기거나 유형이 새로 생겨서 기존에 데이터를 저장하는 테이블 말고 다른 연관 테이블에도 변동이 생겨야 하면 어떤 수정이 생길까?
한 사람이 고치는 일이라면 테이블 숫자는 크게 상관없다. 하지만, 복수의 팀이 관여되어 있다면 문제가 달라진다. 소통이 복잡해지고, 서로의 작업 주기 조정 문제가 발생할 수 있고 그로 인해 수정은 더디게 진행될 수 있다. 이런 일들로 인해 갈등과 반목도 예상할 수 있다. 한편, 테이블 구조를 바꾸면 기존의 화면 다수가 바뀌어야 한다면 어떻게 될까? 화면은 웹 화면 뿐 아니라 모바일 앱의 여러 화면과 키오스크의 화면 일부가 바뀌어야 한다면 어떤가?
이럴 때가 바로 적제 구현의 세번째 갈래로 이벤트 발행과 구독 형식이 필요할 때다.
Load를 구현하는 세 가지 갈래
기호로 Kafka topic 이라고 했지만 정확한 표현은 아니고, Kafka를 꼭 쓸 필요도 없다. 중요한 사실은 직접 레코드를 쓰는 형식이 아니라 필요한 데이터를 비즈니스 의미를 나타내는 형태로 통지5)하고, 통지한 데이터가 이벤트라는 의미로 다른 프로그램에 알려질 수 있는 구조를 사용해야 한다는 것이다. 보통 메시지 전송으로 연계하는 것을 돕는 미들웨어를 사용할 수 있고, 요즘은 이벤트라는 개념을 지원하는 도구들도 존재한다. 그런 기술이나 도구를 이용해서 해당 이벤트와 관련이 있는 프로그램이 자신들과 연계한 데이터 형태에 맞게 이벤트가 담고 있는 데이터를 반영해주는 형식으로 구조를 바꾸면 변화에 대해 기존 구조에 비해 빠르고 대처할 수 있다. 수정이 쉬우니까. 더불어 개발자 사이에 서로간의 간섭이 덜하다. 서로 상대방 테이블의 이름이나 연관관계 등을 바뀐 문제를 따질 이유가 없다.
바로 이 지점이 이벤트 주도 아키텍처와 규칙의 변경을 드러나게 하는 일이 만나는 지점이다. 요약하면 어떤 경우는 메타데이터를 보관해서 사람에게 드러나게 해서 해결할 수 있고, 또 다른 측면으로 하나의 변경이 여러 개의 프로그램을 수정해야 할 경우는 프로그램과의 소통 구조를 바꿔서 다른 서비스가 내포한 규칙에 필요 이상으로 엮이지 않게 이벤트 기반 통지와 수정을 할 수 있도록 하는 일이다.
주석
[1] 여기서 소화란 말을 꼭 원문에 대한 정확한 번역으로 오해하시지 않기를 바란다. 필자는 전문 번역가가 아니고, 프로그래밍 개념에 관심이 많은 소프트웨어 유관 직업인이다.
[2] 구체적으로 들어가면 DDD의 특정 구조물(building block)을 언급하는 사람도 있고, MVC 패턴 등에서 언급하는 충위(layer) 중에 하나를 지칭하기도 하지만 이들을 묶어서 프로그램을 구현하는 단위라고 씀
[3] 관심을 계속 갖고 있는 분들이 있다면, 우리가 구현체가 생겼을 때 공유할 수 있을 것이다.
[4] 나머지는 사실 흔히 알려진 기술이나 남들의 적용 사례와 별반 다르지 않다.