카프카 서버 디스크 최적화

이번 주제는 디스크와 관련된 주제로 글을 작성해보겠습니다. 디스크 구성과 관련된 질문들을 여러 차례 받은 경험도 있고, 이러한 주제를 가지고 정리된 글은 없다고 생각되어 적게 되었습니다. 디스크 구성에 대해 이러한 방식이 표준이다라는 정답은 없지만, 향후 규모가 큰 카프카 클러스터를 구성하거나 IO 때문에 고민이신 분들에게 조금이나마 도움이 되었으면 합니다. 사실 예전부터 쓰려고 했던 주제였는데 조금 늦어졌습니다. 오래된 내용이지만, 기억에 의존해가며 작성해보겠습니다.
배경
운영하던 카프카 클러스터 중 하나에서 불규칙적, 간헐적으로 Shrinking ISR과 Expanding ISR이 발생하기 시작하였습니다. ISR은 In Sync Replica의 약어로 현재 복제되고 있는 그룹이라고 이해하시면 됩니다. ISR에 대해 궁금하신 분은 여기를 참고하시면 됩니다. 이러한 현상의 원인을 찾기 위해 서버의 옵션들 여러 가지를 살펴보았고, 별다른 특이 점을 찾지 못하였습니다. 게다가 운영 중인 다른 클러스터와 비교해보면, 초당 메시지 유입 수는 현저하게 낮았기 때문에 부하 때문이라는 생각은 전혀 하지 못하고 있었습니다. 여러 모니터링 지표들 중 IO 지표를 확인하게 되었고, Shrinking ISR 등이 발생하는 원인이 IO 때문이라는 사실을 알게 되었습니다. 그리고 이러한 문제의 원인은 메시지 사이즈가 약 50K이고, 초당 약 60,000개의 메시지를 쏘고 있는 하나의 토픽이라는 것을 알게 되었습니다. 개선 전후의 상황 비교를 위해 IO그래프가 아닌, CPU 사용량의 그래프를 첨부하겠습니다. 참고로 IO wait이란 지표는 IO가 완료될 때까지 기다리는 시간을 말합니다.
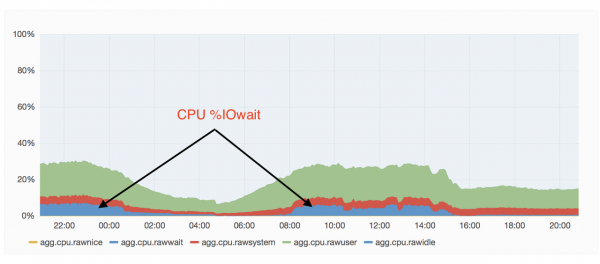
당시의 클러스터 상황을 정리하자면 아래와 같습니다.
- 디스크 구성 : SATA 4TB * 4EA(RAID 1+0)
- 서버 수 : Total 30EA
- 초당 메시지 유입 수 : 500,000(50KB * 60,000 msg/sec)
서버 튜닝
제 자신이 엔지니어라고 생각하고 있기 때문에 누구나 손쉽게 해결할 수 있는 간단한 하드웨어 증설 및 변화로 해결하는 방법이 아닌, 튜닝을 통해 해결해 보고 싶었습니다. 그래서 제가 알고 있는 지식에서 할 수 있는 내용들은 전부 해보고 싶었고, 옵션을 변경하면서 실제로 어떻게 변화하는지 직접 확인해보고 싶었습니다. 그래서 높은 IO 처리를 위해 여러 가지 변경 작업들을 진행하였고, 그중 중요하다고 생각되는 내용들을 정리하겠습니다.
Log Flush Policy 옵션 변경
메시지 또는 데이터 등을 디스크에 저장 시 운영체제는 성능 등의 이슈로 즉시 디스크에 저장하지 않고, 버퍼 캐시 또는 페이지 캐시 등에 저장하게 됩니다. 그리고 이렇게 임시로 캐시에 저장된 데이터들을 fsync()를 이용하여 물리적 디스크로 저장하게 되는데, 이 빈도수가 빈번하게 일어나게 되면 IO 성능은 저하되지만 안정성은 높아지게 됩니다. 카프카 역시 페이지 캐시를 통해 메시지를 저장하도록 동작하고, 아래의 옵션을 이용하여 flush 주기를 수동으로 설정할 수 있습니다.
- log.flush.interval.messages(해당 수의 메시지들이 되면 디스크로 flush 합니다.)
- log.flush.interval.ms(해당 수의 시간이 되면 디스크로 flush 합니다.)
만약 flush를 너무 자주 하게 되면, IO가 빈번히 일어나게 되어 성능에 문제를 줄 수 있습니다. 하지만 성능의 문제보다 데이터의 durability 등을 고려한다면, flush 주기를 짧게 변경할 수도 있습니다. 저의 경우 아래와 같이 옵션을 변경하여 운영했었습니다.
해당 값은 각각 1000000과 1000으로 적용하였었고, 이 설정의 의미는 message 수 또는 ms에 도달하면 flush를 하게 되는 것입니다. 현재 발생하고 있는 높은 IO 이슈를 해결하기 위해 두 옵션 모두 기본값으로 변경하였고, 변경 이후 이슈가 되었던 IO 부하는 다소 낮아졌습니다. 하지만 완벽하게 문제가 해결된 것은 아니었습니다.
IO scheduler 변경
브로커 옵션 변경을 통해 다소 안정적으로 변경되었지만, 전체 클러스터의 사용량이 조금씩 늘어나면서 IO와 관련된 문제는 또다시 발생하기 시작했습니다. 이번에는 OS의 IO scheduler를 변경해보기로 했습니다.
모든 디스크의 read, write 요청들은 filesystem을 거쳐 이 IO scheduler를 거치게 됩니다. IO scheduler의 방식은 총 3가지가 있으며, 각각의 scheduler는 디스크 access 요청에 따라 자신만의 방법으로 처리하게 됩니다. 총 3가지의 방식에 대해 간단하게 살펴보겠습니다.
- noop: 모든 IO요청을 FIFO 대기열에 추가하고, 병합하는 작업만 하는 IO scheduler입니다. 정렬을 하지 않기 때문에 SSD 같이 회전하지 않는 디스크에 적합, RAID 구성시에도 권장됩니다.
- deadline: 주 목표는 요청에 대해 시간을 보장하는 것입니다. 다음 요청을 받기 전에 사용할 큐를 결정하게 됩니다. 기본값으로 read는 500ms, write는 5s.
- cfq: Completely Fair Queueing의 약자로 공정하게 큐잉하는 것입니다. 리눅스 프로세스에서 공정하게 실행하게 되는 것입니다.
OS에서 현재 사용 중인 IO scheduler를 확인하는 방법은 다음과 같습니다.
[root@dev1 ~]# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
특히 우리가 자주 사용하는 플래시 기반의 SSD와 플래터를 이용하는 HDD는 디스크 동작 방식이 다르므로, IO scheduler 역시 다르게 구성하는 것이 효과적입니다. 이미 IO scheduler의 튜닝을 통해 해결할 수 있는 부분이 아니라는 점은 예상했지만, 혹시나 하는 마음으로 테스트 목적으로 모든 옵션을 한 번씩 적용하여 상태를 체크했었습니다. 하지만 높은 IO 이슈는 전혀 개선되지 않았습니다.
디스크 구성 변경
초기 카프카 클러스터 운영 당시 RAID를 사용하지 않고 사용했지만, 수명이 얼마 남아 있지 않은 재고 디스크를 사용하다 보니 잦은 디스크 장애로 오히려 운영의 불편함을 느끼게 되었고, 일부 클러스터는 RAID를 묶어서 사용하고 있었습니다. 높은 IO 문제를 겪고 있는 클러스터의 디스크 구성은 SATA 4TB 디스크 4개로 RAID 1+0으로 설정하여 사용 중이었습니다. 각 서버의 높은 IO 부담을 해결하고자 RAID 구성으로 묶어 사용하기보다, RAID를 풀고 각각의 디스크 4장으로 IO를 분산하게 되면 좀 더 효율적이지 않을까라는 생각이 들어 RAID 구성을 제거하고, 서비스에 투입하였지만 약간의 차이는 있었지만 크게 눈에 띄게 달라지는 점은 보이지 않았습니다.
게다가 해당 클러스터의 사용량은 초당 메시지 유입수가 50만에서 70만으로 점점 높아지면서 Shrinking ISR과 Expanding ISR의 발생 빈도수 역시 크게 증가하게 되었습니다.
문제 해결
나름대로 튜닝해볼 수 있는 여러 가지 방법들을 전부 시도하였으나, 눈에 띄게 개선되는 점은 없었습니다. 안정적인 클러스터 운영이 가장 중요하였기에 다급하게 높은 IO가 발생하는 문제의 토픽만 별도의 독립된 카프카 클러스터로 이전하였고, 이전 작업을 하면서 물리적 디스크 여러 개로 분산시키면 IO에 도움이 된다는 사실을 알게 되었습니다.그래서 서버당 SATA 디스크 4개가 아닌 SATA 디스크 12개로 신규 카프카 클러스터를 구성하기로 결정하고, 다음과 같이 카프카 클러스터를 구성하였습니다.
- 디스크 구성 : SATA 8TB * 12EA
- 서버 수 : Total 30EA
- 초당 메시지 유입 수 : 700,000(50KB * 60,000 msg/sec)
위와 같이 구성한 후 문제가 되는 토픽과 기존 사용하던 모든 토픽들을 새로운 카프카 클러스터로 이전하였고, 그 후 CPU 상태 그래프를 첨부하겠습니다.

앞선 첫 번째 그래프와 비교했을 때, 기존보다 더욱 많은 양의 메시지들을 처리함에도 불구하고 눈에 띄게 IO wait이 사라 졌음을 알 수 있습니다.
마무리
사실 앞서 말씀드린 높은 IO로 인한 문제를 처음 접했을 때, 제가 가지고 있는 지식에 기반하여 튜닝만으로 문제가 해결되기를 원하였습니다. 하지만 그렇게 해결되지 않아 약간의 아쉬운 부분도 있었지만, 여러 가지 테스트를 하면서 배운 점도 많았습니다. 결론적으로 말씀드리고 싶은 것은 카프카가 성능도 좋고 처리량도 좋지만 단일 메시지의 크기가 큰 경우(저의 경우 약 50KB)에는 생각한 것만큼 성능이 나오지 않을 수 있습니다. 그리고 이러한 문제를 해결하기 위해서는 여러 개의 물리적 디스크를 이용한 분산이 매우 중요하다고 생각합니다. 카프카는 토픽 저장 시 인덱스 등을 가지는 구조가 아닌 가장 심플한 sequence append 방식으로 파일을 저장하기 때문에 파일 포맷 등에 관련된 영향은 적다고 할 수 있습니다. 대신 물리적인 디스크의 분산이 성능에 많이 좌우된다고 할 수 있습니다.
긴 글 읽어주셔서 감사드리고, 디스크 구성을 고민하시거나 높은 IO로 고민하시는 분들에게 해당 글이 도움되었으면 합니다. 감사합니다.