%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D

2026-02-01
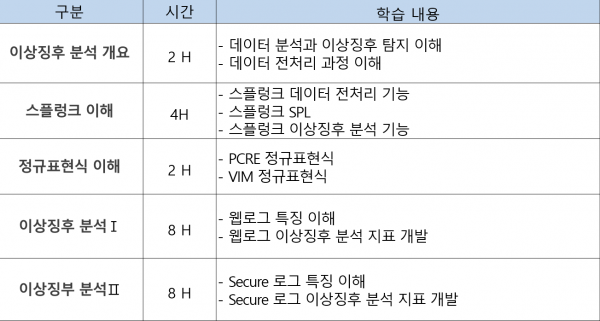
교육기획 담당자로부터 가장 많이 듣는 얘기. 담당자 입장에선 스플렁크 교육으로 결재 받았는데 계획서만 보면 고작 반나절 정도 시간만 할당되어 있으니 답답할만 하다. 그래서 각 단위는 스플렁크 필수 기반 기술이거나, 단위 주제 모두 스플렁크를 활용한다는 보충 설명이 필수. 왜 이런 상황이 자주 발생할까? 건축 커리큘럼을 보고 망치, 톱질은 언제 배우나 궁금해 하는 이가 있을까? 건축의 역사부터 설계, 골조, 단열 등의 과정 하나하나가 건축의 필요조건이며, 전 과정이 조화를 이뤄야만 좋은 집이 지어진다는 사실을 모르는 이는 없을 것이다....
2025-07-23
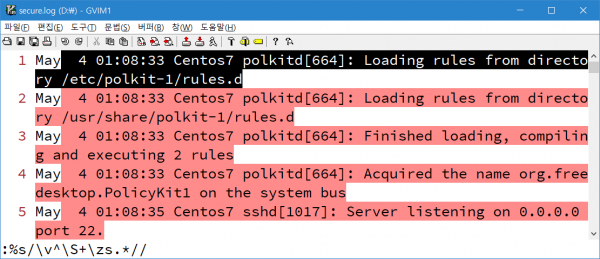
vim을 이용한 월단위 시간 정보 요약. 프로세스 발생 정보 요약. 메시지 발생 정보 요약. 데이터 이해도를 높이기 위한 탐색적 데이터 분석 과정을 진행할 때 가끔 나오는 질문이 있다. VIM 말고 AWK 같은 거 쓰면 안 되나요? why not? 월단위 시간 정보. Jun이 둘인 이유는 uniq 명령이 연속되지 않는 데이터를 다른 데이터로 인식하기 때문. 정렬을 먼저 한 후, 중복을 제거해주면 된다. 프로세스 발생 정보. 메시지 발생 정보. 내친 김에 프로세스 전체 발생 내역....

2025-01-05
맥킨지, 구글 등 쟁쟁한 이력을 자랑하는 백영재 문화인류학 박사의 2023년작. thick data라는 낯선 용어가 시선을 끈다. 두꺼워? 데이터가? 뭔 말인가 했더니 인류학에서 뭔가를 관찰할 때 고유 맥락과 상황을 포함시켜 연구 대상을 더 구체적이고 풍부하게 묘사하는 thick description에서 따온 말이라고. 빅데이터는 표면상으로 드러난 데이터, thick data는 표면에서는 보이지 않는 배경과 맥락을 포함한 데이터라는게 저자의 설명. 빅데이터는 '무엇을 얼마나 '에 관해서만 설명할 수 있다면, thick data는 '어떤 맥락에서 왜 '에 관해 말해 준다......
2024-04-13
로그스태시는 에러 발생 시 상당히 고약한 트러블슈팅 환경을 제공한다. 물론 원인 파악이 쉬울 때도 있음. remove_field 오타 발생. 에러 원인을 정확히 찝어준다. 문제는 안 그럴 때가 많다는 거. ssl_certificate_authorities 오타 발생. 남다른 가독성을 뽐내는 한 줄 에러 메시지. [caption id="attachment_29442" align="aligncenter" width="600"] 엔터 좀 치라고[/caption] 엔터 좀 쳐주면 낫지 않을까? 저 상황에서도 읽기 좋으라고 사용된 문장 기호 중 쉼표를 줄바꿈 문자로 치환. 몇 번째 라인(항상 정확하진 않음), 어느 지점에 문제가 있는지 보이기 시작한다. 적당한 엔터 삽입만으로도 정보 처리 수준이 달라진다. 정보가 잘 보이지 않던 구조를 잘 보이는 구조로 바꾸는 데이터 시각화 사례. [caption id="attachment_29446" align="aligncenter" width="600"]...

2024-01-12
다시 글쓰기를 새로 시작해보려고 합니다. 잘 정리된 글보다는 개발 중에서 발생하는 이슈 기술적인 이슈 처리 위주로 숏하게 써보려고 합니다. 안하는 것보다는 조금이라도 하는게 좋다라는 생각으로 진행합니다. Spark에서 기존 잘 실행되고 있는 프로그램을 복사해서 몇가지 수정한 후 실행 시 다음과 같은 에러가 발생 하였습니다. 소스 코드 원인 위 에러 메시지는 Spark job 결과를 Text 파일로 저장할 경우 발생할 수 있는 에러 메시지인데 내용은 다음과 같습니다....

2022-10-16
검색엔진은 잘 모르지만 엘라스틱을 데이터 분석툴로 사용할 때 데이터 전처리가 차지하는 비중은 생각보다 크다. [caption id="attachment_29096" align="aligncenter" width="600"] youtube [/caption] 그렇다 보니 자연스럽게 로그스태시 필터 기능을 소개하는 데 많은 시간을 할애한다. 그때 종종 받는 (툴을 잘 쓰면 데이터 분석이 쉬워질거라는 기대가 담긴) 질문. 저 기능들을 언제 다 익혔나요? 그러게? 난 언제 저 기능들을 익혔지? 사실은 익힌 적이 없다. 엘라스틱을 만나기 전부터 이미 사용해왔으니까. 도끼 쓰다가 전기톱으로 바꾼다고 나무 잘리는 원리가 달라질 리 없는 것과 마찬가지....
2022-05-15
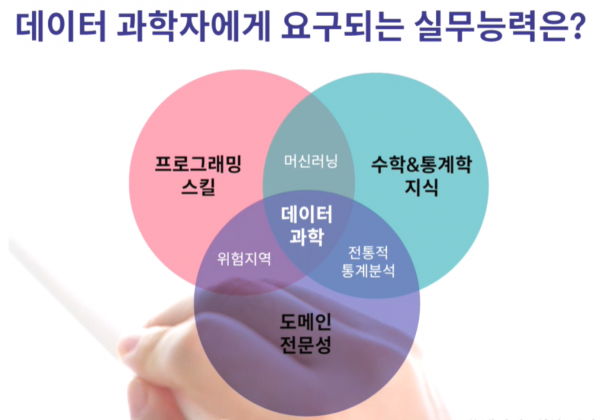
빅데이터가 대세 키워드였던 몇 년 전까지만 해도 하둡 등의 인프라가 모든 것을 해결해줄 듯한 분위기였다면, 알파고 이후엔 수학 및 통계학, 그리고 그런 지식에 기반한 모델링 능력이 필수 자질로 꼽히는 세상이 되었다. 광고, 추천, 번역, 금융 등 많은 분야에서 그런 자질을 요구한다. 열거한 분야들의 공통점은 최종 목적이 결국 돈이라는 것. 돈을 벌기 위해서는 사람의 심리나 행동을 예측해야 한다. 절대 쉽지 않은 작업. 아마 작두 타는 수준의 분석 능력이 필요할 것이다. 복잡한 수학/통계 지식의 필요성에 수긍이 가는 대목....

2021-09-30
5일 중 3일을 정규표현식에 할애한 과정을 진행하다가 아차 (?) 싶었던 첫 강의가 생각난다. 그렇게 정규표현식 비중을 줄이고 줄여서 현재 정규표현식 과정은 반나절 정도 (..) 그럼에도 빠지지 않는 질문이 쉬운 정규표현식? 대체 방법? 정규표현식이 쉬워지는 방법은 많이 써보는 수밖에 없다 보니 정규표현식을 사용하지 않고 원하는 테이블 구조를 만드는 방법에 대한 고민을 자주 한다. 일단 엘라스틱 예제 데이터 생성. url 데이터에서 file 정보를 추출해보자. 다음은 읽기 스키마 기반의 런타임 필드 생성 쿼리....

2021-07-04
다음은 root 사용자의 IP별 접속 현황. 5월 14~16일 및 6월 12일의 IP 변화가 눈에 띈다. 그런데 사용자가 많다면 사용자별 접속 IP의 변화 확인이 꽤 까다로울 것이다. 더 직관적인, 한 눈에 IP 변화를 알아차릴 수 있는 차트를 그릴 수는 없을까? 다음은 root 사용자의 IP 고유 개수 변화. 6월 12일의 변화는 뚜렷한데, 5월 14~16일의 변화는 보이지 않는다. 해당 시점의 접속 IP가 평소와 다른 건 맞지만 유형은 하나뿐이니 당연한 결과. IP 변화를 숫자 변화로 이상징후 분석은 통계 분석의 다른 말이고, 결국 특정 상태의 숫자 변화를 추적하는 과정. 마침 IP는 숫자로도 표현할 수 있다. 8bit 단위로 나눈 IP를 순서대로 256...
2020-11-16
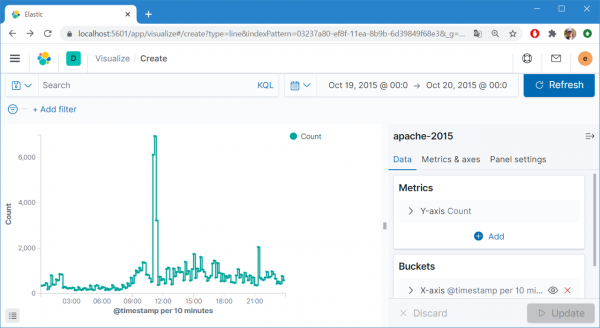
단순 카운트 변화 추이는 로그의 상태를 정확히 표현하지 못한다. 다양한 상태 정보가 섞여 있는 상태에서 개수의 변화가 어떤 상태를 특정하는지 알기 힘들다는 얘기. count 추이(12~25일) 그래서 강조하는 게 상태별 고유성 확보를 통한 데이터 해상도 변경 및 다양한 Metric 활용. 카운트 추이로는 알 수 없었던 19일의 상태 변화가 해상도 및 Metric 변경을 통해 드러난다. URL 고유 개수 백분위 90% 의 변수 길이 이런 결과를 얻기 위해 데이터를 분류하고, 고유성을 확보하고, 효과적인 지표를 개발하는 데 많은 시간을 투자한다. 그러나 그런 노력을 들이고도 정작 쌓인 데이터를 분석하지 않는다면 모든 노력은 물거품이 되고 만다. 반면 정말 단순하게 로그 개수만 센다 해도 매일, 매 시간, 매 분 데이터의 변화를 궁금해한다면 그 데이터에서 의미를 찾아낼 수 있다....
더보기